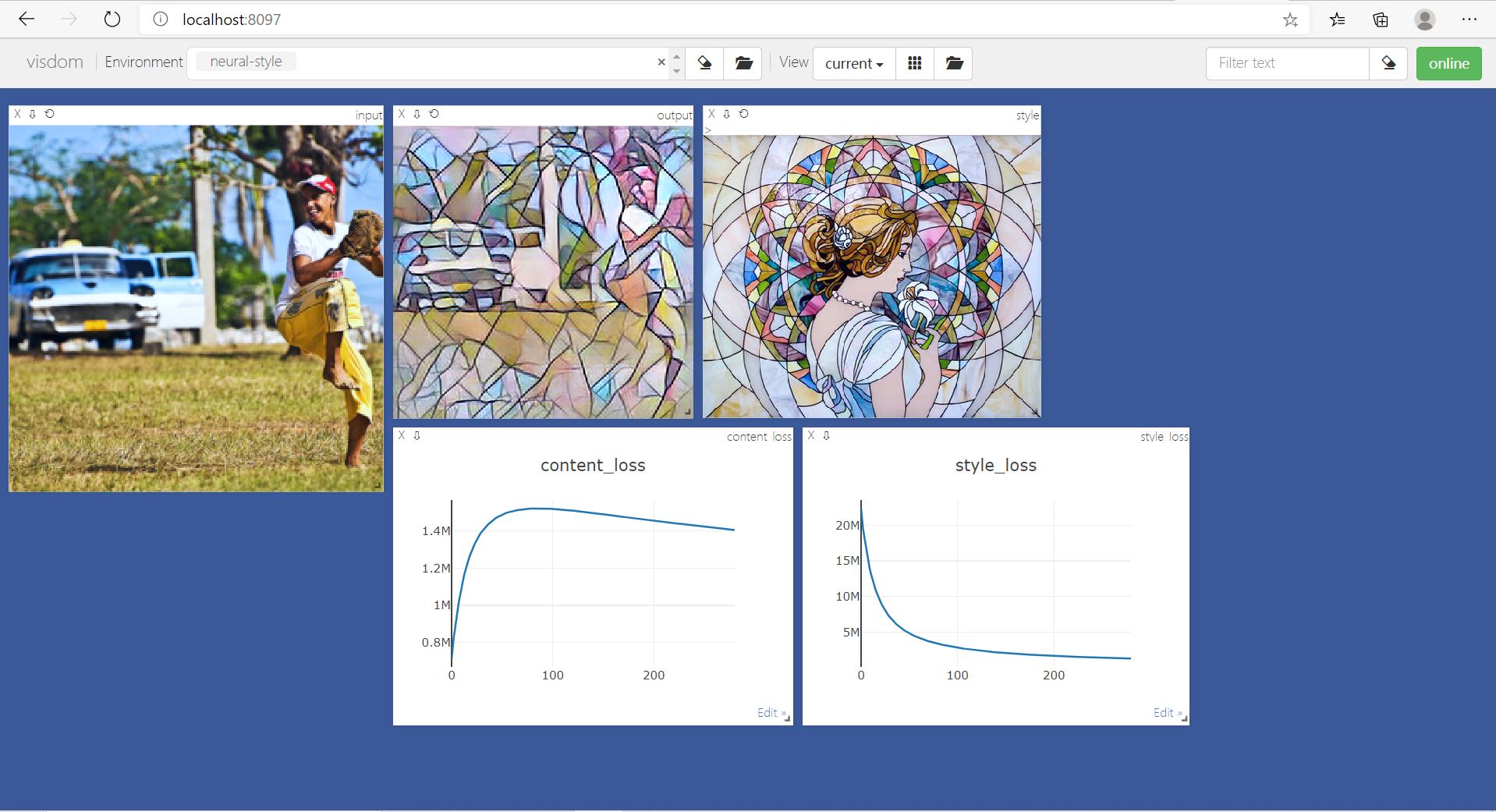
这是我在学习《深度学习框架PyTorch入门与实践》第九章的笔记。原书实现了Fast Neural Style,实现将输入图片转换为对应图片风格的类型。
该博客有书中的全部内容,并且有全部代码和数据集的百度网盘链接。代码在PyCharm下测试可运行。
部分代码和注释如下:
transformer_net.py
import torch import torch.nn as nn import numpy as np class TransformerNet(nn.Module): def __init__(self): super(TransformerNet, self).__init__() # 下卷积层 self.initial_layers = nn.Sequential( ConvLayer(3, 32, kernel_size=9, stride=1), nn.InstanceNorm2d(32, affine=True), # torch.nn.InstanceNorm2d(num_features: int, # eps: float = 1e-05, momentum: float = 0.1, # affine: bool = False, # track_running_stats: bool = False) # 该函数与Batch Normalization的区别是,可以对每个通道的输入进行标准化 nn.ReLU(True), ConvLayer(32, 64, kernel_size=3, stride=2), nn.InstanceNorm2d(64, affine=True), nn.ReLU(True), ConvLayer(64, 128, kernel_size=3, stride=2), nn.InstanceNorm2d(128, affine=True), nn.ReLU(True) ) # Residual layers(残差层) self.res_layers = nn.Sequential( ResidualBlock(128), ResidualBlock(128), ResidualBlock(128), ResidualBlock(128), ResidualBlock(128) ) # Upsampling Layers(上卷积层) self.upsample_layer = nn.Sequential( UpsampleConvLayer(128, 64, kernel_size=3, stride=1, upsample=2), nn.InstanceNorm2d(64, affine=True), nn.ReLU(True), UpsampleConvLayer(64, 32, kernel_size=3, stride=1, upsample=2), nn.InstanceNorm2d(32, affine=True), nn.ReLU(True), ConvLayer(32, 3, kernel_size=9, stride=1) ) def forward(self, x): x = self.initial_layers(x) x = self.res_layers(x) x = self.upsample_layer(x) return x class ConvLayer(nn.Module): """ 使用Reflection Pad 默认padding是在边缘补0 """ def __init__(self, in_channels, out_channels, kernel_size, stride): super(ConvLayer, self).__init__() reflection_padding = int(np.floor(kernel_size / 2)) self.reflection_pad = nn.ReflectionPad2d(reflection_padding) # torch.nn.ReflectionPad2d(padding: Union[T, Tuple[T, T, T, T]]) # 上下左右反射边缘的像素进行补齐 self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride) def forward(self, x): out = self.reflection_pad(x) out = self.conv2d(out) return out class ResidualBlock(nn.Module): def __init__(self, channels): super(ResidualBlock, self).__init__() self.res_block = nn.Sequential( ConvLayer(channels, channels, kernel_size=3, stride=1), nn.InstanceNorm2d(channels, affine=True), nn.ReLU(True), ConvLayer(channels, channels, kernel_size=3, stride=1), nn.InstanceNorm2d(channels, affine=True), ) def forward(self, x): residual = x out = self.res_block(x) out = out + residual return out class UpsampleConvLayer(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, stride, upsample=None): super(UpsampleConvLayer, self).__init__() self.upsample = upsample reflection_padding = kernel_size // 2 self.reflection_pad = nn.ReflectionPad2d(reflection_padding) self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride) def forward(self, x): x_in = x if self.upsample: x_in = nn.functional.interpolate(x_in, mode='nearest', scale_factor=self.upsample) out = self.reflection_pad(x_in) out = self.conv2d(out) return out
utils.py
import torch as t import torch.nn as nn import torchvision as tv from torchvision.models import vgg16 from collections import namedtuple class Vgg16(nn.Module): def __init__(self): super(Vgg16, self).__init__() features = list(vgg16(pretrained=True).features)[:23] # vgg16的前23层 # vgg16是vgg的一种变形,可以在官网源代码找到其定义及网络结构 # https://pytorch.org/docs/stable/_modules/torchvision/models/vgg.html#vgg11 self.features = nn.ModuleList(features).eval() # ModuleList与定义网络层的Sequential类似 def forward(self, x): results = [] # features的第3,8,15,22层分别是:relu1_2,relu2_2,relu3_3,relu4_3 for ii, model in enumerate(self.features): x = model(x) # ModuleList为子model,x记录每一层的输出 if ii in {3, 8, 15, 22}: results.append(x) # append()方法用于在列表末尾添加新的对象。 vgg_outputs = namedtuple("VggOutpus", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3']) return vgg_outputs(*results) # *表示传递参数,对应上一行的vgg_outputs定义名称 IMAGENET_MEAN = [0.485, 0.456, 0.406] IMAGENET_STD = [0.229, 0.224, 0.225] def gram_matrix(y): """输入形状b,c,h,w 输出形状b,c,c""" """ b:batch_size c:channel h:height w:width """ (b, ch, h, w) = y.size() features = y.view(b, ch, w * h) features_t = features.transpose(1, 2) # transpose将1轴和2轴交换。从0轴开始计数。 gram = features.bmm(features_t) / (ch * h * w) # 返回b*ch*ch return gram def get_style_data(path): """ 加载风格图片 :param path: 输入路径 :return: 形状1*c*h*w, Tensor """ style_transform = tv.transforms.Compose([ tv.transforms.ToTensor(), tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD), ]) style_image = tv.datasets.folder.default_loader(path) style_tensor = style_transform(style_image) return style_tensor.unsqueeze(0) def normalize_batch(batch): """ :param batch:输入b,ch,h,w, 0~255, Variable :return:b,ch,h,w -2~2, Variable """ mean = batch.data.new(IMAGENET_MEAN).view(1, -1, 1, 1) std = batch.data.new(IMAGENET_STD).view(1, -1, 1, 1) mean = t.autograd.Variable(mean.expand_as(batch.data)) std = t.autograd.Variable(std.expand_as(batch.data)) return (batch / 255.0 - mean) / std
main.py
import torch as t import torchvision as tv import torchnet as tnt from torch.utils import data from transformer_net import TransformerNet import utils from PackedVGG import Vgg16 from torch.nn import functional as F import tqdm import os import ipdb mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] class Config(object): image_size = 256 # 图片大小 batch_size = 8 data_root = 'data/' # 数据集存放路径:data/coco/a.jpg num_workers = 4 # 多线程加载数据 use_gpu = True # 使用GPU style_path = 'style.jpg' # 风格图片存放路径 lr = 1e-3 # 学习率 env = 'neural-style' # visdom env plot_every = 10 # 每10个batch可视化一次 epoches = 2 # 训练epoch content_weight = 1e5 # content_loss 的权重 style_weight = 1e10 # style_loss的权重 model_path = None # 预训练模型的路径 debug_file = 'debug/debug.txt' # touch $debug_fie 进入调试模式 content_path = 'input.png' # 需要进行分割迁移的图片 result_path = 'output.png' # 风格迁移结果的保存路径 def train(**kwargs): opt = Config() for k_, v_ in kwargs.items(): setattr(opt, k_, v_) device=t.device('cuda') if opt.use_gpu else t.device('cpu') vis = utils.Visualizer(opt.env) # 数据加载 transfroms = tv.transforms.Compose([ tv.transforms.Resize(opt.image_size), tv.transforms.CenterCrop(opt.image_size), tv.transforms.ToTensor(), tv.transforms.Lambda(lambda x: x * 255) ]) dataset = tv.datasets.ImageFolder(opt.data_root, transfroms) dataloader = data.DataLoader(dataset, opt.batch_size) # 转换网络 transformer = TransformerNet() if opt.model_path: transformer.load_state_dict(t.load(opt.model_path, map_location=lambda _s, _: _s)) transformer.to(device) # 损失网络 Vgg16 vgg = Vgg16().eval() vgg.to(device) for param in vgg.parameters(): param.requires_grad = False # 优化器 optimizer = t.optim.Adam(transformer.parameters(), opt.lr) # 获取风格图片的数据 style = utils.get_style_data(opt.style_path) vis.img('style', (style.data[0] * 0.225 + 0.45).clamp(min=0, max=1)) style = style.to(device) # 风格图片的gram矩阵 with t.no_grad(): features_style = vgg(style) gram_style = [utils.gram_matrix(y) for y in features_style] # 损失统计 style_meter = tnt.meter.AverageValueMeter() content_meter = tnt.meter.AverageValueMeter() for epoch in range(opt.epoches): content_meter.reset() style_meter.reset() for ii, (x, _) in tqdm.tqdm(enumerate(dataloader)): # 训练 optimizer.zero_grad() x = x.to(device) y = transformer(x) y = utils.normalize_batch(y) x = utils.normalize_batch(x) features_y = vgg(y) features_x = vgg(x) # content loss content_loss = opt.content_weight * F.mse_loss(features_y.relu2_2, features_x.relu2_2) # style loss style_loss = 0. for ft_y, gm_s in zip(features_y, gram_style): gram_y = utils.gram_matrix(ft_y) style_loss += F.mse_loss(gram_y, gm_s.expand_as(gram_y)) style_loss *= opt.style_weight total_loss = content_loss + style_loss total_loss.backward() optimizer.step() # 损失平滑 content_meter.add(content_loss.item()) style_meter.add(style_loss.item()) if (ii + 1) % opt.plot_every == 0: if os.path.exists(opt.debug_file): ipdb.set_trace() # 可视化 vis.plot('content_loss', content_meter.value()[0]) vis.plot('style_loss', style_meter.value()[0]) # 因为x和y经过标准化处理(utils.normalize_batch),所以需要将它们还原 vis.img('output', (y.data.cpu()[0] * 0.225 + 0.45).clamp(min=0, max=1)) vis.img('input', (x.data.cpu()[0] * 0.225 + 0.45).clamp(min=0, max=1)) # 保存visdom和模型 vis.save([opt.env]) t.save(transformer.state_dict(), 'checkpoints/%s_style.pth' % epoch) @t.no_grad() def stylize(**kwargs): opt = Config() for k_, v_ in kwargs.items(): setattr(opt, k_, v_) device=t.device('cuda') if opt.use_gpu else t.device('cpu') # 图片处理 content_image = tv.datasets.folder.default_loader(opt.content_path) content_transform = tv.transforms.Compose([ tv.transforms.ToTensor(), tv.transforms.Lambda(lambda x: x.mul(255)) ]) content_image = content_transform(content_image) content_image = content_image.unsqueeze(0).to(device).detach() # 模型 style_model = TransformerNet().eval() style_model.load_state_dict(t.load(opt.model_path, map_location=lambda _s, _: _s)) style_model.to(device) # 风格迁移与保存 output = style_model(content_image) output_data = output.cpu().data[0] tv.utils.save_image(((output_data / 255)).clamp(min=0, max=1), opt.result_path) if __name__ == '__main__': import fire fire.Fire() train()
训练过程中的结果如下图所示: