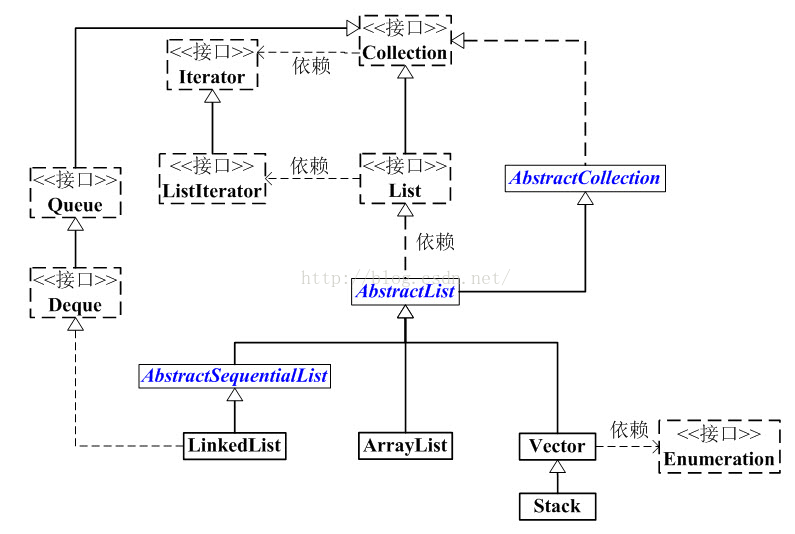
1.ArrayList和 LinkedList的区别。
1.ArrayList是实现了基于动态数组的数据结构。
2.LinkedList基于链表的数据结构。
3.对于随机访问get和set,ArrayList优,因为LinkedList要移动指针。
4.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
总结:通过实践发现,网上面试答案太过含糊(大致意思为:ArrayList 适用于查询 LinkedList适用于修改)
1. 当在末尾插入元素,两者性能差距不大,ArrayList略好
2. 当在固定位置(本文为 0 位置)插入元素,LinkedList性能明显好于ArrayList
3. 当在 i 位置插入元素,ArrayList性能明显高于LinkedList,同时反证了两者在查询效率ArrayList的优势
ArrayList想要get(int index)元素时,直接返回index位置上的元素,而LinkedList需要通过for循环进行查找,虽然LinkedList已经在查找方法上做了优化,比如index < size / 2,则从左边开始查找,反之从右边开始查找,但是还是比ArrayList要慢。这点是毋庸置疑的。
ArrayList想要在指定位置插入或删除元素时,主要耗时的是System.arraycopy动作,会移动index后面所有的元素;LinkedList主耗时的是要先通过for循环找到index,然后直接插入或删除。
插入的数据量和插入的位置是决定两者性能的主要方面。
参考:http://blog.csdn.net/eson_15/article/details/51145788
2.HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
1.HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
2.HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
3.另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
4.由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
5.HashMap不能保证随着时间的推移Map中的元素次序是不变的
要注意的一些重要术语:
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap
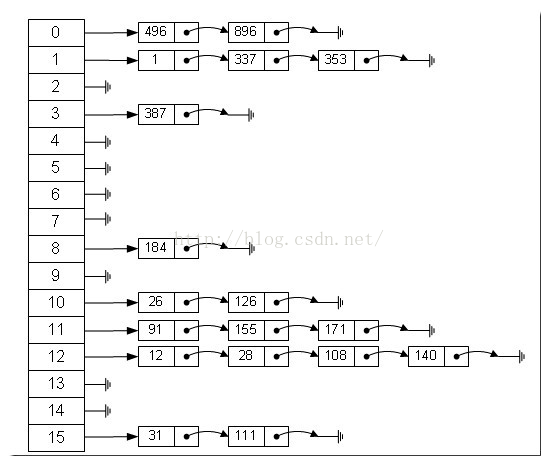
Java中的数据存储方式有两种结构,一种是数组,另一种就是链表,前者的特点是连续空间,寻址迅速,但是在增删元素的时候会有较大幅度的移动,所以数组的特点是查询速度快,增删较慢。
而链表由于空间不连续,寻址困难,增删元素只需修改指针,所以链表的特点是查询速度慢、增删快。
那么有没有一种数据结构来综合一下数组和链表以便发挥他们各自的优势?答案就是哈希表
参考:http://blog.csdn.net/seu_calvin/article/details/52653711
3.JDBC中Statement和PreparedStatement性能的比较
随着数据的不断增大,PreparedStatement的执行效果是Statement
的效果要快。
在安全性上PreparedStatement会进行预处理编译,在数据的安全性上PreparedStatement是可以防止Statement的sql注入导致的漏洞问题
4.分布式锁
http://blog.csdn.net/u010918487/article/details/77799819
6.长连接和短连接的概念
前者是整个通讯过程,客户端和服务端只用一个Socket对象,长期保持Socket的连接;后者是每次请求,都新建一个Socket,处理完一个请求就直接关闭掉Socket。所以,其实区分长短连接就是:整个客户和服务端的通讯过程是利用一个Socket还是多个Socket进行的。
HTTP短连接(非持久连接)是指,客户端和服务端进行一次HTTP请求/响应之后,就关闭连接。所以,下一次的HTTP请求/响应操作就需要重新建立连接。
HTTP长连接(持久连接)是指,客户端和服务端建立一次连接之后,可以在这条连接上进行多次请求/响应操作。持久连接可以设置过期时间,也可以不设置。
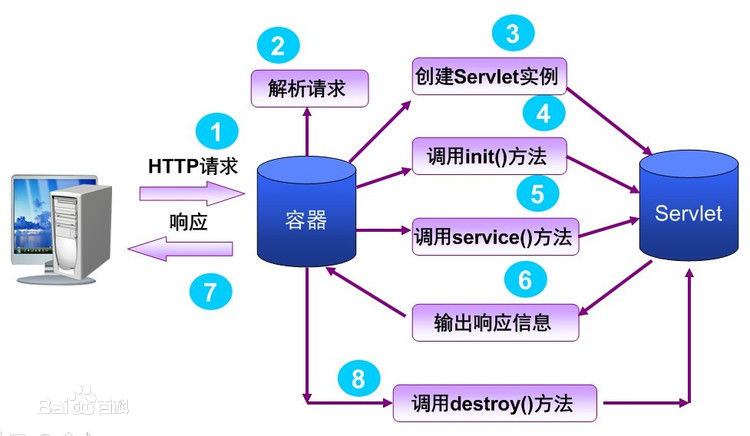
7.serlvlet
8. Java中的NIO,BIO,AIO分别是什么?
IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO
BIO,同步阻塞式IO
简单理解:一个连接一个线程。BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
在JDK1.4之前,用Java编写网络请求,都是建立一个ServerSocket,然后,客户端建立Socket时就会询问是否有线程可以处理,如果没有,要么等待,要么被拒绝。即:一个连接,要求Server对应一个处理线程。
NIO,同步非阻塞IO
简单理解:一个请求一个线程。NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
AIO,异步非阻塞IO
简单理解:一个有效请求一个线程。AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
9.数据库连接池
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
10.
Java内存溢出主要有哪些类型?
主要有三种类型
第一种OutOfMemoryError: PermGen space
发生这种问题的原意是程序中使用了大量的jar或class,使java虚拟机装载类的空间不够,与Permanent Generation space有关。解决这类问题有以下两种办法:
1. 增加java虚拟机中的XX:PermSize和XX:MaxPermSize参数的大小,其中XX:PermSize是初始永久保存区域大小,XX:MaxPermSize是最大永久保存区域大小。如针对tomcat6.0,在catalina.sh 或catalina.bat文件中一系列环境变量名说明结束处(大约在70行左右) 增加一行:
JAVA_OPTS=" -XX:PermSize=64M -XX:MaxPermSize=128m"
如果是windows服务器还可以在系统环境变量中设置。感觉用tomcat发布sprint+struts+hibernate架构的程序时很容易发生这种内存溢出错误。使用上述方法,我成功解决了部署ssh项目的tomcat服务器经常宕机的问题。
2. 清理应用程序中web-inf/lib下的jar,如果tomcat部署了多个应用,很多应用都使用了相同的jar,可以将共同的jar移到tomcat共同的lib下,减少类的重复加载。
第二种OutOfMemoryError: Java heap space
发生这种问题的原因是java虚拟机创建的对象太多,在进行垃圾回收之间,虚拟机分配的到堆内存空间已经用满了,与Heap space有关。解决这类问题有两种思路:
1. 检查程序,看是否有死循环或不必要地重复创建大量对象。找到原因后,修改程序和算法。
我以前写一个使用K-Means文本聚类算法对几万条文本记录(每条记录的特征向量大约10来个)进行文本聚类时,由于程序细节上有问题,就导致了Java heap space的内存溢出问题,后来通过修改程序得到了解决。
2. 增加Java虚拟机中Xms(初始堆大小)和Xmx(最大堆大小)参数的大小。如:set JAVA_OPTS= -Xms256m -Xmx1024m
第三种OutOfMemoryError:unable to create new native thread
这种错误在Java线程个数很多的情况下容易发生