---恢复内容开始---
今天接到任务,写一个爬虫案例,要写的通俗易懂,还要能包含爬虫的基本知识,让大家从一个案例中学会爬虫!我寻思着应该爬什么大家比较喜欢呢?爬取日本小姐姐?怕尺度太大审核不过!!!那就爬取淘宝小姐姐吧!淘宝小姐姐也是个个水灵的很。
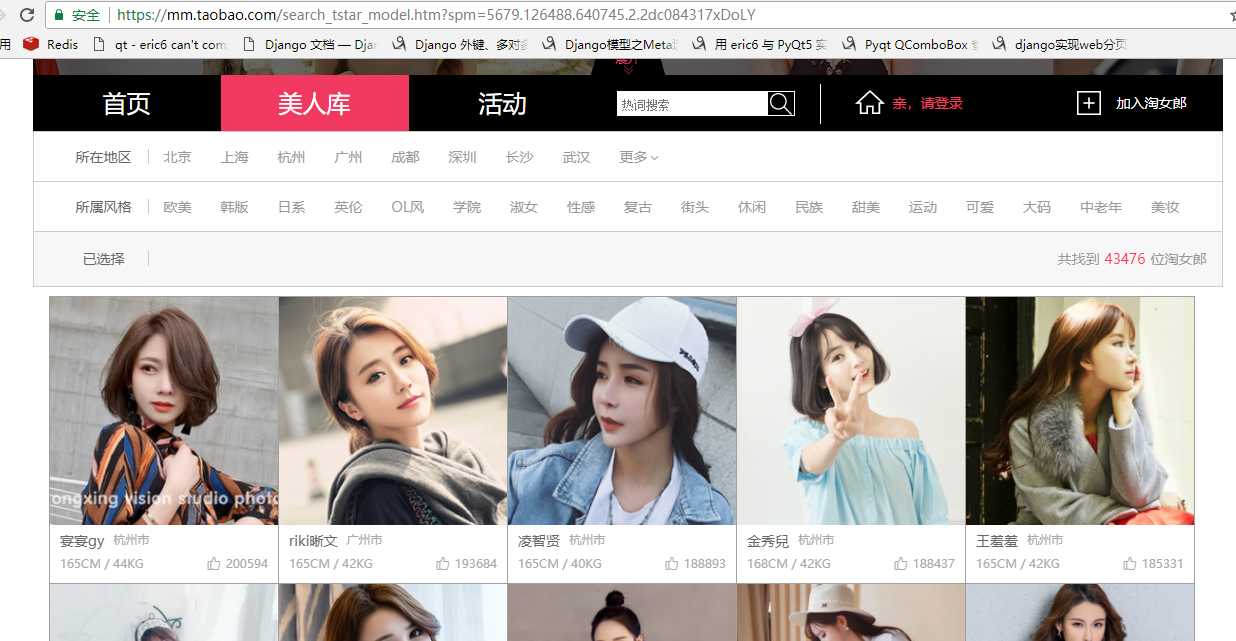
先上一高清无码大图,让大家过过眼瘾。
爬虫一共就四个主要步骤:
1、明确目标:明确需要抓取那些内容,在哪个网页
2、爬:分析网站结构,将所有的网站的内容全部爬下来
3、取:提取我们所需要的数据
4、处理数据:按照需求存储使用
第一步:
明确目标:
网站url: https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.2dc084317xDoLY
抓取内容:
头像:存储在本地硬盘。
名字,城市,身高,体重,点赞数: 保存在mysql数据库
说明:这里只是用作教程并非真的要将爬取的内容作为其它用途,我只是单纯想看看淘宝小姐姐的卓越风姿。
第二步爬:
使用到的模块:
python 3.6: python环境
requests: 发送请求
pymysql: 操作mysql
queue: 队列
random: 产生随机数
想要看懂这篇文章,还是需要那么一丢丢的python基础知识。
分析网页结构:
1、确定网页数据的请求方式'GET'还是'POST',ajax异步请求还是直接浏览器请求,一般ajax请求的url跟我们在浏览器上的url地址栏看到是不一样的,所以我们需要使用到浏览器的开发者工具抓包查看。
我观察了下淘女郎这个模特库首页是有分页的,这里有个小技巧,来确定请求方式:
我这里使用的是谷歌浏览器,按F12打开浏览器的开发者工具,切换到netrork选项,然后将网页拉到最下面有分页的地方。
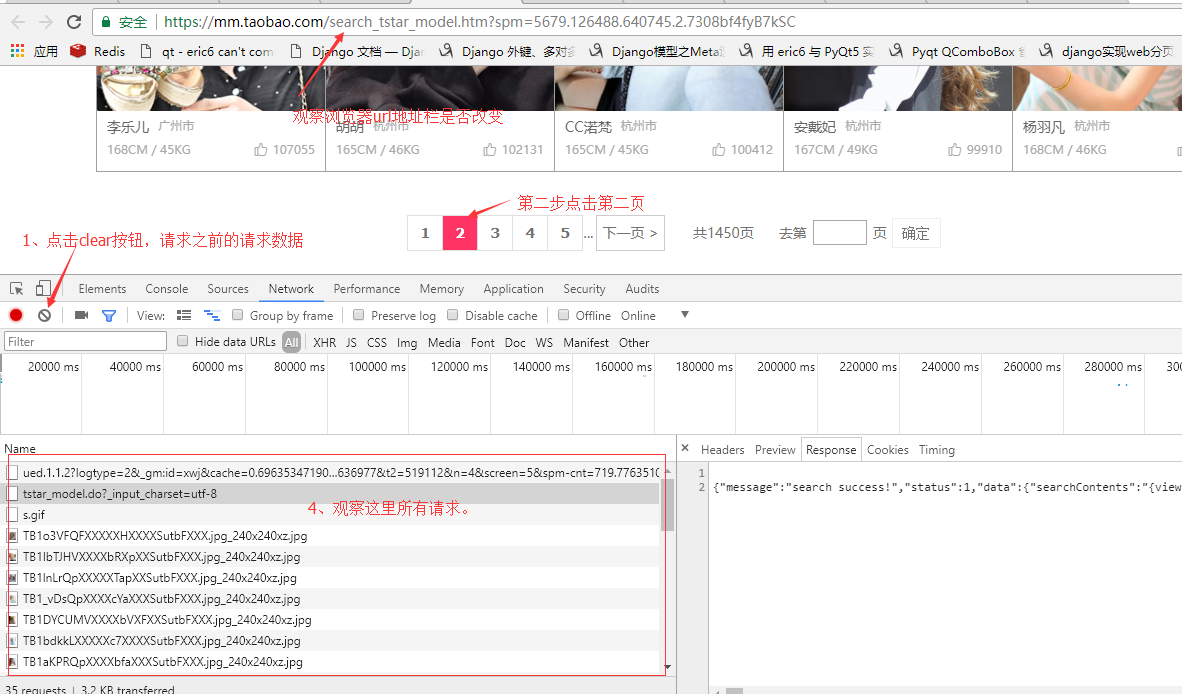
我们观察url地址栏上的地址并没有发生改变,所以地址栏上的url对我们没有帮助!这也说明这个网页的内容是通过ajax加载的。
查看图片上4的位置所有请求的url,发现第一个请求并没有返回任何数据,只有第二个请求有返回数据第三个请求之后的全部都是请求图片的。
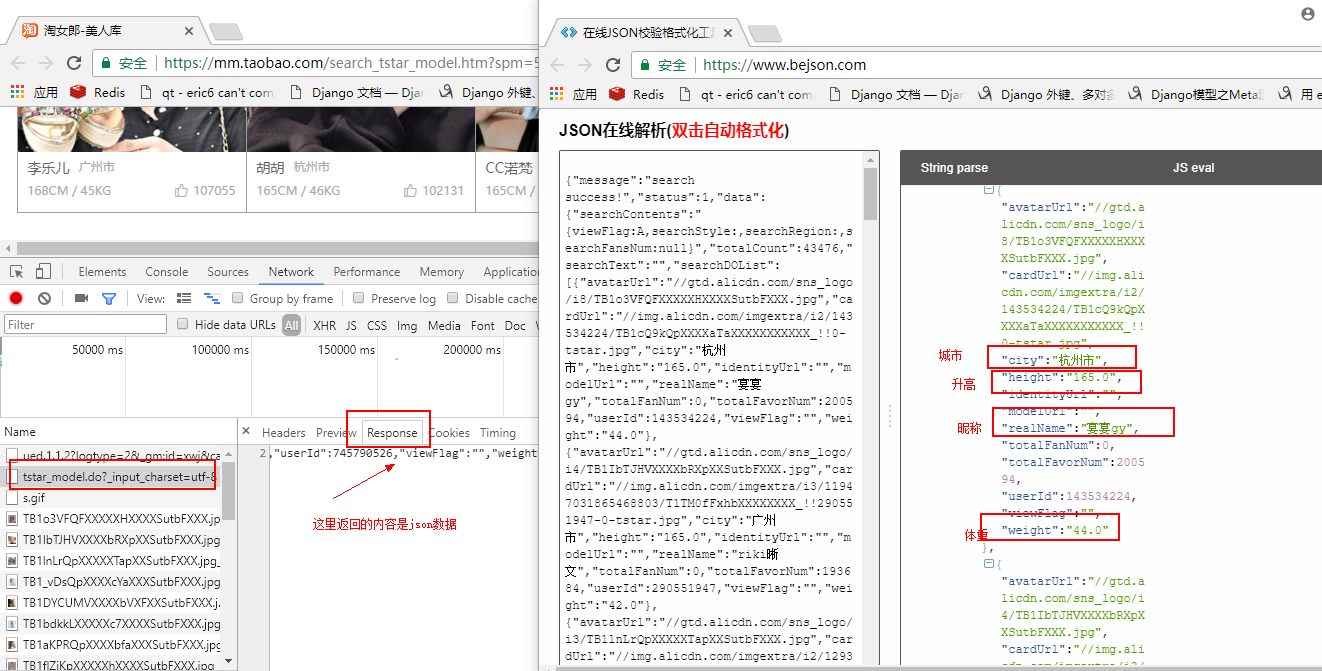
选中第二个请求,选中response,查看返回的数据是json数据,可以将json数据复制到json在线解析网站解析看下返回的是什么,解析出来后我们发现,json数据 "searchDOList" 字段就是包含了当前页所有淘宝小姐姐的信息。
确定我们需要的数据就是在第二请求之后,我们回到开发者管理工具,点击headers查看请求头信息。
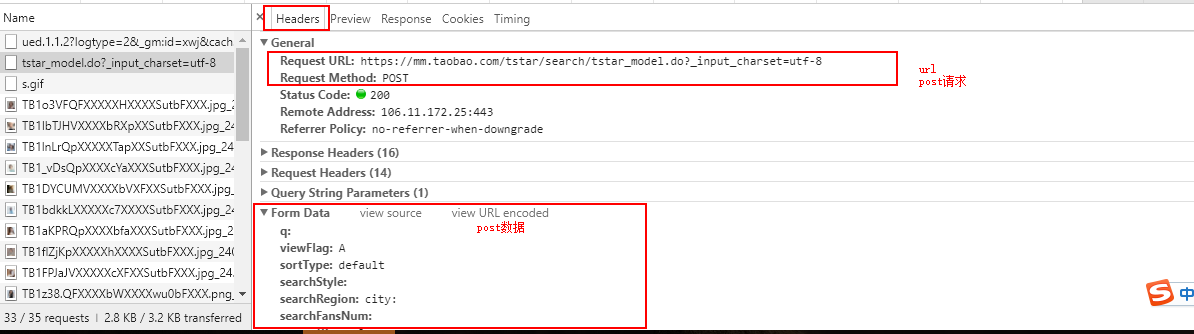
标红框的这几个数据等会写爬虫会用到,分析到这里我们就拿到了等下写爬虫需要的数据:
```
url:https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8
请求方式:post
post参数:
q:
viewFlag:A
sortType:default
searchStyle:
searchRegion:city:
searchFansNum:
currentPage:2
pageSize:100
```
淘女郎一共有1450页,所以采取多线程的方式进行抓取。
线程:一个进程可以有多个线程,所有线程共享进程的内存空间,通讯效率高,切换开销小。
多线程:密集I/O任务(网络I/O,磁盘I/O,数据库I/O)使用多线程合适。
缺陷:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发。
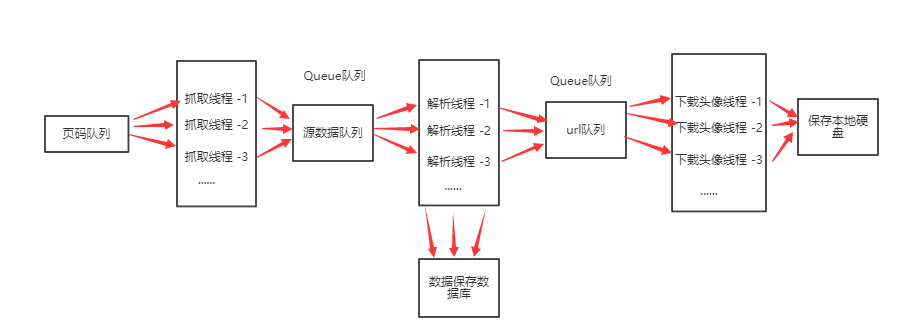
抓取线程:
1、设置请求头,网站一般会检查请求头,所以我们在发送请求的时候一般都要携带请求头
根据经验,大部分网站都会对下面字段进行检查:
- origin 表示记录你从那个网站进来
- user-agent 标识浏览器
2、设置id代理,如果一个id请求频繁,一般网站都会封掉这些ip,那么爬虫需要使用代理id。
3、构造post数据,根据刚才在浏览器开发者管理工具中看到的字段构造
4、利用requests模块发送请求
class ThreadCrawl(Thread):
def __init__(self,page_queue):
Thread.__init__(self) # 继承多线程父类
self.q = page_queue
def run(self):
while True:
if self.q.empty():
break
# 构造请求头
page = self.q.get()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'origin': 'https://mm.taobao.com'
}
# 请求url
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
# 从任务队列中取出任务,页数
# 构造post请求数据
data = {
'viewFlag': 'A',
'sortType': 'default',
'currentPage': page,
'pageSize': 100,
}
# 根据协议类型,选择不同的代理
proxies = [{"http": "http://61.135.217.7:80"},
{"http": "http://120.27.144.192:8080"},
{"http": "http://123.119.202.254:8118"},
] # 普通ip代理设置方式
proxies = random.choice(proxies) # 多个代理ip随机选一个发送请求
# proxy = {"http": "账号:密码@61.158.163.130:16852"} #私密ip代理设置方式
timeout = 3 # 定义重复请求次数
while timeout:
# 发送请求
data = requests.post(url=url, data=data, headers=headers, proxies=proxies).json()
if data['status'] == -1: # 如果没有请求到正确的数据将重复请求三次
timeout -= 1
else:
data_queue.put(data) # 将抓取下来的数据放到数据队列
break
第三步提取:
由于我们抓取的整个网站返回的json数据,使用requests对象的json方法,可以返回一个python的字典对象,所以提取数据时候只需要按照python字典方式提取就可以了这里比较简单。
将淘宝小姐姐的信息插入到数据库,头像url继续放入到url队列中
class ParseCrawl(Thread):
def __init__(self, thread_id, data_queue):
Thread.__init__(self) # 继承多线程父类
self.threadID = thread_id # 线程id
self.q = data_queue # 任务队列
def run(self):
while not exitFlag_Parser:
try:
data = self.q.get(block=False) # 从队列中取出一条数据,block=False 设置队列为空时不阻塞,直接抛异常,用try处理.
# 这样主要是防止get方法阻塞
info_list = data['data']['searchDOList'] # 获取到一页中所有小姐姐的信息
for info in info_list:
# 将提取的数据写入数据库
param = [info["realName"],info['city'],str(info['height']),str(info['weight']),info['totalFavorNum']]
sql = 'insert into taobaomm VALUE (0,"%s","%s","%s","%s","%s")'
self.save_mysql(sql,param)
# 提取出头像url放入对列
avatar_queue.put((info['avatarUrl'], info['realName']))
except:
pass
def save_mysql(self,sql,param):
# 连接数据库
com = pymysql.connect(host='192.168.0.103',port=3306,password='mysql',
charset='utf8',user='root',database='mm')
cur = com.cursor()
cur.execute(sql,param)
cur.close()
com.commit()
com.close()
第四步:
下载淘宝小姐姐头像保存到硬盘中。
头像在json中返回的是一个url,所有需要再次请求头像图片。
class LoadImage(Thread):
def __init__(self, avatar_queue):
Thread.__init__(self) # 继承多线程父类
self.q = avatar_queue # 任务队列
def run(self):
# 控制线程是否退出
while not exitFlag_Load:
try:
url, realName = self.q.get(block=False) # 从url队列中提取一条数据
print(url)
url = 'http:' + url # 拼接头像url
image = requests.get(url).content # 请求图片
# 将头像保存下来以头像命名
with open('./tp/' + realName + '.png', 'wb') as f:
f.write(image)
except:
pass
主程序逻辑
if __name__ == '__main__':
# 创建三个队列
page_queue,data_queue,avatar_queue = Queue(),Queue(),Queue()
threadcrawl = []
parsecrawl = []
loadcrawl = []
exitFlag_Parser = False # 线程状态
exitFlag_Load = False
# 将任务入队列
for i in range(1, 1451):
page_queue.put(i)
crawl_list = ['crawl_1','crawl_2','crawl_3','crawl_4']
# 开四个线程
for crawl_id in crawl_list:
crawl = ThreadCrawl(page_queue)
parse = ParseCrawl(data_queue)
load = LoadImage(avatar_queue)
# 将全部线程保存到列表
threadcrawl.append(crawl)
parsecrawl.append(parse)
loadcrawl.append(load)
# 开启线程
crawl.start()
parse.start()
load.start()
while not page_queue.empty():
pass
# 让主线程等待子线程结束
for t in threadcrawl:
t.join()
# 当数据队列为空时通知线程退出
while data_queue.empty():
pass
exitFlag_Parser = True
for t in parsecrawl:
t.join()
# 当url 队列为空时通知线程退出
while not avatar_queue.empty():
pass
exitFlag_Load = True
for t in loadcrawl:
t.join()
费了九牛二虎之力终于写完了,开始运行爬虫,小姐姐们一个一个乖乖的往我的硬盘上跑!想想就激动呢!

看下我们数据库已经存了很多妹子信息了。

关于爬虫一些建议:
1、尽量减少请求次数,能抓列表页就不抓详情页,能抓json数据,尽量不抓页面数据。
2、实际应用时候,反爬措施最常见的一般是,检查请求头,封ip, 验证码。封ip可用代理,验证码可机器识别或者接第三方打码平台。
3、爬取速度尽量不要太快,大家都是混碗饭吃,不要把对方服务器爬崩了,在能接受的范围内延时,重要的是将数据爬取下来。
4、一些网站数据加密,数据动态加载的,可用 Selenium调用浏览器获取源码。
---恢复内容结束---