String s = new String("abc")这段代码创建了几个对象呢?s=="abc"这个判断的结果是什么?s.substring(0,2).intern()=="ab"这个的结果是什么呢?- s.charAt(index) 真的能表示出所有对应的字符吗?
"abc"+"gbn"+s直接的字符串拼接是否真的比使用StringBuilder的性能低?
前言
很高兴遇见你~
Java中的String对象特性,与c/c++语言是很不同的,重点在于其不可变性。那么为了服务字符串不可变性的设计,则衍生出非常多的相关问题:为什么要保持其不可变?底层如何存储字符串?如何进行字符串操作才拥有更好的性能?等等。此外,字符编码的相关知识也是非常重要;毕竟,现在使用emoij是再正常不过的事情了。
文章的内容围绕着不可变 这个重点展开:
- 分析String对象的不可变性;
- 常量池的存储原理以及intern方法的原理
- 字符串拼接的原理以及优化
- 代码单元与代码点的区别
- 总结
那么,我们开始吧~
不可变性
理解String的不可变性,我们可以简单看几行代码:
String string = "abcd";
String string1 = string.replace("a","b");
System.out.println(string);
System.out.println(string1);
输出:
abcd
bbcd
string.replace("a","b")这个方法把"abcd"中的a换成了b。通过输出可以发现,原字符串string并没有发生任何改变,replace方法构造了一个新的字符串"bbcd"并赋值给了string1变量。这就是String的不可变性。
再举个栗子:把"abcd"的最后一个字符d改成a,在c/c++语言中,直接修改最后一个字符即可;而在java中,需要重新创建一个String对象:abca,因为"abcd"本身是不可变的,不能被修改。
String对象值是不可变的,一切操作都不会改变String的值,而是通过构造新的字符串来实现字符串操作。
很多时候很难理解,为什么Java要如此设计,这样不是会导致性能的下降吗?回顾一下我们日常使用String的场景,更多的时候并没有直接去修改一个string,而是使用一次,则被抛弃。但下次,很可能,又再一次使用到相同的String对象。例如日志打印:
Log.d("MainActivity",string);
前面的"MainActivity"我们并不需要去更改他,但是却会频繁使用到这个字符串。Java把String设计为不可变,正是为了保持数据的一致性,使得相同字面量的String引用同个对象。例如:
String s1 = "hello";
String s2 = "hello";
s1与s2引用的是同个String对象。如果String可变,那么就无法实现这个设计了。因此,我们可以重复利用我们创建过的String对象,而无需重新创建他。
基于重复使用String的情况比更改String的场景更多的前提下,Java把String设计为不可变,保持数据一致性,使得同个字面量的字符串可以引用同个String对象,重复利用已存在的String对象。
在《Java编程思想》一书中还提到另一个观点。我们先看下面的代码:
public String allCase(String s){
return string.toUpperCase();
}
allCase方法把传入的String对象全部变成大写并返回修改后的字符串。而此时,调用者的期望是传入的String对象仅仅作为提供信息的作用,而不希望被修改,那么String不可变的特性则非常符合这一点。
使用String对象作为参数时,我们希望不要改变String对象本身,而String的不可变性符合了这一点。
存储原理
由于String对象的不可变特性,在存储上也与普通的对象不一样。我们都知道对象创建在 堆 上,而String对象其实也一样,不一样的是,同时也存储在 常量池 中。处于堆区中的String对象,在GC时有极大可能被回收;而常量池中的String对象则不会轻易被回收,那么则可以重复利用常量池中的String对象。也就是说, 常量池是String对象得以重复利用的根本原因 。
常量池不轻易垃圾回收的特性,使得常量池中的String对象可以一直存在,重复被利用。
往常量池中创建String对象的方式有两种: 显式使用双引号构造字符串对象、使用String对象的intern()方法 。这两个方法不一定会在常量池中创建对象,如果常量池中已存在相同的对象,则会直接返回该对象的引用,重复利用String对象。其他创建String对象的方法都是在堆区中创建String对象。举个栗子吧。
当我们通过new String()的方法或者调用String对象的实例方法,如string.substring()方法,会在堆区中创建一个String对象。而当我们使用双引号创建一个字符串对象,如String s = "abc",或调用String对象的intern()方法时,会在常量池中创建一个对象,如下图所示:
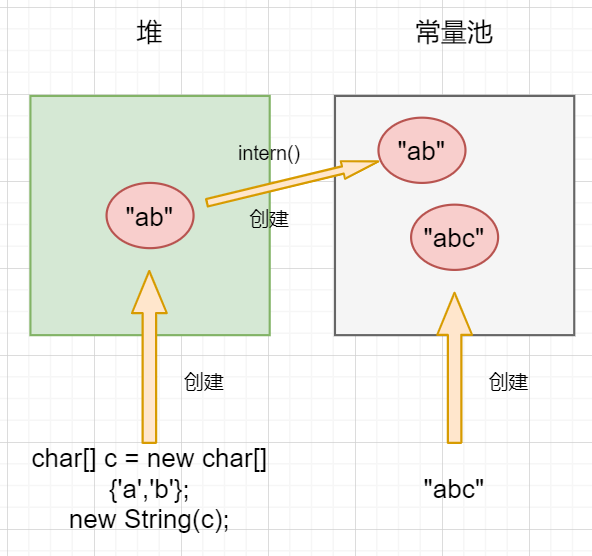
还记得我们文章开头的问题吗?
String s = new String("abc"),这句代码创建了几个对象?"abc"在常量池中构造了一个对象,new String()方法在堆区中又创建了一个对象,所以一共是两个。s=="abc"的结果是false。两个不同的对象,一个位于堆中,一个位于常量池中。s.substring(0,2).intern()=="ab"intern方法在常量池中构建了一个值为“ab"的String对象,"ab"语句不会再去构建一个新的String对象,而是返回已经存在的String对象。所以结果是true。
只有显式使用双引号构造字符串对象、使用String对象的
intern()方法 这两种方法会在常量池中创建String对象,其他方法都是在堆区创建对象。每次在常量池创建String对象前都会检查是否存在相同的String对象,如果是则会直接返回该对象的引用,而不会重新创建一个对象。
关于intern方法还有一个问题需要讲一下,在不同jdk版本所执行的具体逻辑是不同的。在jdk6以前,方法区是存放在永生代内存区域中,与堆区是分割开的,那么当往常量池中创建对象时,就需要进行深拷贝,也就是把一个对象完整地复制一遍并创建新的对象,如下图:
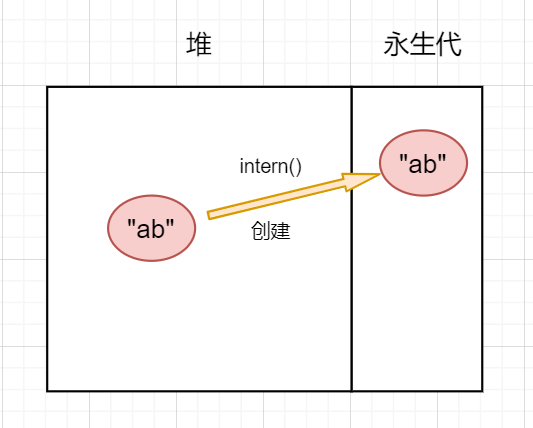
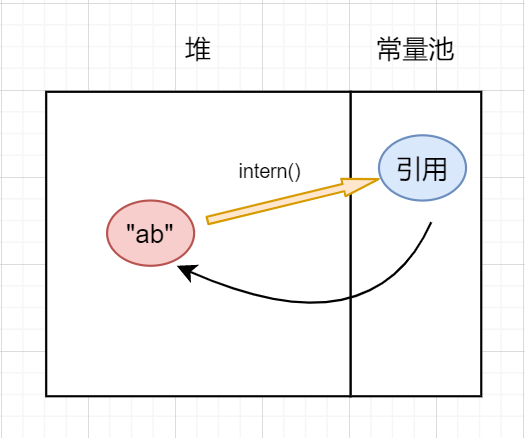
永生代有一个很严重的缺点:容易发生OOM 。永生代是有内存上限的,且很小,当程序大量调用intern方法时很容易就发生OOM。在JDK7时将常量池迁移出了永生代,改在堆区中实现,jdk8以后使用了本地空间实现。jdk7以后常量池的实现使得在常量池中创建对象可以进行浅拷贝,也就是不需要把整个对象复制过去,而只需要复制对象的引用即可,避免重复创建对象,如下图:
观察这个代码:
String s = new String(new char[]{'a'});
s.intern();
System.out.println(s=="a");
在jdk6以前创建的是两个不同的对象,输出为false;而jdk7以后常量池中并不会创建新的对象,引用的是同个对象,所以输出是true。
jdk6之前使用intern创建对象使用的深拷贝,而在jdk7之后使用的是浅拷贝,得以重复利用堆区中的String对象。
通过上面的分析,String真正重复利用字符串是在使用双引号直接创建字符串时。使用intern方法虽然可以返回常量池中的字符串引用,但是本身已经需要堆区中的一个String对象。因而我们可以得出结论:
尽量使用双引号显式构建字符串;如果一个字符串需要频繁被重复利用,可以调用intern方法将他存放到常量池中。
字符串拼接
字符串操作最多的莫过于字符串拼接了,由于String对象的不可变性,如果每次拼接都需要创建新的字符串对象就太影响性能了。因此,官方推出了两个类: StringBuffer、StringBuilder 。这两个类可以在不创建新的String对象的前提下拼装字符串、修改字符串。如下代码:
StringBuilder stringBuilder = new StringBuilder("abc");
stringBuilder.append("p")
.append(new char[]{'q'})
.deleteCharAt(2)
.insert(2,"abc");
String s = stringBuilder.toString();
拼接、插入、删除都可以很快速地完成。因此,使用StringBuilder进行修改、拼接等操作来初始化字符串是更加高效率的做法。StringBuffer和StringBuilder的接口一致,但StringBuffer对操作方法都加上了synchronize关键字,保证线程安全的同时,也付出了对应的性能代价。单线程环境下更加建议使用StringBuilder。
拼接、修改等操作来初始化字符串时使用StringBuilder和StringBuffer可以提高性能;单线程环境下使用StringBuilder更加合适。
一般情况下,我们会使用+来连接字符串。+在java经过了运算符重载,可以用来拼接字符串。编译器也对+进行了一系列的优化。观察下面的代码:
String s1 = "ab"+"cd"+"fg";
String s2 = "hello"+s1;
Object object = new Object();
String s3 = s2 + object;
-
对于s1字符串而言,编译器会把
"ab"+"cd"+"fg"直接优化成"abcdefg",与String s1 = "abcdefg";是等价的。这种优化也就减少了拼接时产生的消耗。甚至比使用StringBuilder更加高效。 -
s2的拼接编译器会自动创建一个StringBuilder来构建字符串。也就相当于以下代码:
StringBuilder sb = new StringBuilder(); sb.append("hello"); sb.append(s1); String s2 = sb.toString();那么这是不是意味着我们可以不需要显式使用StringBuilder了,反正编译器都会帮助我们优化?当然不是,观察下边的代码:
String s = "a"; for(int i=0;i<=100;i++){ s+=i; }这里有100次循环,则会创建100个StringBuilder对象,这显然是一个非常错误的做法。这时候就需要我们来显示创建StringBuilder对象了:
StringBuilder sb = new StringBuilder("a"); for(int i=0;i<=100;i++){ sb.append(i); } String s = sb.toString();只需要构建一个StringBuilder对象,性能就极大地提高了。
-
String s3 = s2 + object;字符串拼接也是支持直接拼接一个普通的对象,这个时候会调用该对象的toString方法返回一个字符串来进行拼接。toString方法是Object类的方法,若子类没有重写,则会调用Object类的toString方法,该方法默认输出类名+引用地址。这看起来没有什么问题,但是有一个大坑:切记不要在toString方法中直接使用+拼接自身 。如下代码@Override public String toString() { return this+"abc"; }这里直接拼接this会调用this的toString方法,从而造成了无限递归。
Java对+拼接字符串进行了优化:
- 可以直接拼接普通对象
- 字面量直接拼接会合成一个字面量
- 普通拼接会使用StringBuilder来进行优化
但同时也有注意这些优化是有限度的,我们需要在合适的场景选择合适的拼接方式来提高性能。
编码问题
在Java中,一般情况下,一个char对象可以存储一个字符,一个char的大小是16位。但随着计算机的发展,字符集也在不断地发展,16位的存储大小已经不够用了,因此拓展了使用两个char,也就是32位来存储一些特殊的字符,如emoij。一个16位称为一个 代码单元 ,一个字符称为 代码点 ,一个代码点可能占用一个代码单元,也可能是两个。
在一个字符串中,当我们调用String.length() 方法时,返回的是代码单元的数目, String.charAt() 返回也是对应下标的代码单元。这在正常情况下并没有什么问题。而如果允许输入特殊字符时,这就有大问题了。要获得真正的代码点数目,可以调用 String .codePointCount 方法;要获得对应的代码点,可调用 String.codePointAt 方法。以此来兼容拓展的字符集。
一个字符为一个代码点,一个char称为一个代码单元。一个代码点可能占据一个或两个代码单元。若允许输入特殊字符,则必须使用代码点为单位来操作字符串。
总结
到此,关于String的一些重点问题就分析完毕了,文章开头的问题读者应该也都知道答案了。这些是面试常考题,也是String的重点。除此之外,关于正则表达式、输入与输出、常用api等等也是String相关很重要的内容,有兴趣的读者可自行学习。
希望文章对你有帮助。
参考资料
- 《Java编程思想》 java工程师皆知的神书,详细讲解了如何更好运用java来编程,感受编程思想。
- 《Java核心技术卷一》 入门书籍,主要讲解如何使用String的api以及一些注意的点。
- 《深入理解JVM》对于理解方法区以及常量池有非常大的帮助。
- 深入解析String#intern美团技术团队的一篇分析String.intern方法的文章。
- 感谢网络其他博客的贡献。
全文到此,原创不易,觉得有帮助可以点赞收藏评论转发。
笔者才疏学浅,有任何想法欢迎评论区交流指正。
如需转载请评论区或私信交流。另外欢迎光临笔者的个人博客:传送门