原始数据接上篇文章来操作。可能需要查看后才能懂。点击这里查看
1.常用的模型字段类型
官方文档:https://docs.djangoproject.com/en/2.1/ref/models/fields/#field-types
定义的模型中,类名对应的表名,类属性对应的表的字段,我们在上节内容有说过,可以查看。这里我们详细了解。
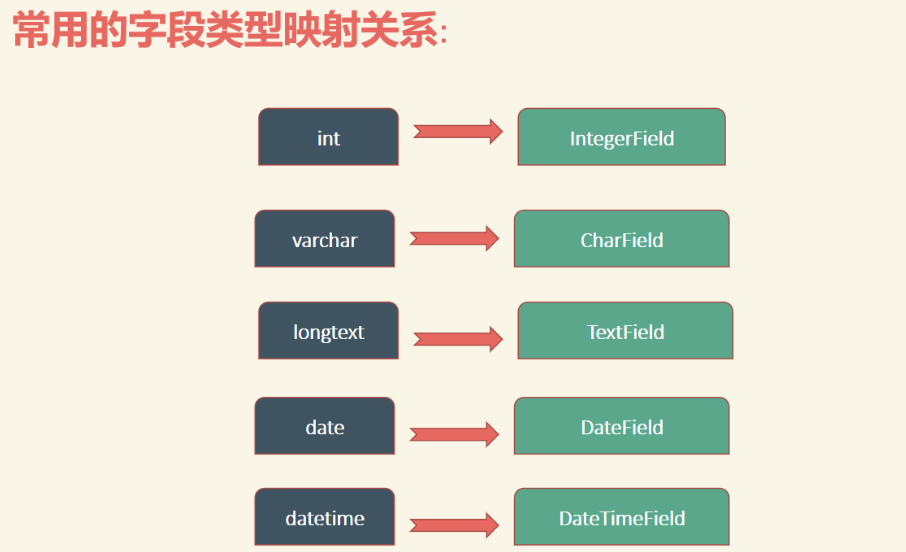
django和mysql的对应类型,models.Model下的方法
| django类型 | 映射到mysql类型 |
|---|---|
| IntegerField : 整型 | 映射到数据库中的int类型。 |
| CharField: 字符类型 | 映射到数据库中的varchar类型,通过max_length指定最大长度。 |
| TextField: 文本类型 | 映射到数据库中的text类型。 |
| BooleanField: 布尔类型 | 映射到数据库中的tinyint类型,在使用的时候,传递True/False进去。如果要可以为空,则用NullBooleanField。 |
| DateField: 日期类型 | 没有时间。映射到数据库中是date类型在使用的时候,可以设置DateField.auto_now每次保存对象时,自动设置该字段为当前时间。设置DateField.auto_now_add当对象第一次被创建时自动设置当前时间。 |
| DateTimeField: 日期时间类型 | 映射到数据库中的是datetime类型,在使用的时候,传递datetime.datetime()进去。 |
2.字段的常用参数
官方文档:https://docs.djangoproject.com/en/2.1/ref/models/fields/#field-options
field常用参数
| 参数名 | 作用 |
|---|---|
| primary_key: | 指定是否为主键。 |
| unique: | 指定是否唯一。 |
| null: | 指定是否为空,默认为False。 |
| blank: | 等于True时form表单验证时可以为空,默认为False。 |
| default: | 设置默认值。 |
| DateField.auto_now: | 每次修改都会将当前时间更新进去,只有调用,QuerySet.update方法将不会调用。这个参数只是Date和DateTime以及TimModel.save()方法才会调用e类才有的。 |
| DateField.auto_now_add: | 第一次添加进去,都会将当前时间设置进去。以后修改,不会修改这个值 |
主键的设置
第一种方式设置主键,指定int类型,设置为主键,使用自增长。 id = models.IntegerField(primary_key=True, auto_created=True) 第二种方式:使用AutoField方法,这个方法是自增长且为int类型 id = models.AutoField(primary_key=True使用AutoField方法,这个方法是自增长且为int类型)
unique设置唯一,注意的事项
1 qq = models.CharField(max_length=20, unique=True, null=True)
当你设置的这个字段是唯一了,就代表必须和其他的不一样,但是有的时候用户没有提供,可以不填的,就可以为空,不然就会出错
3.常用查询
管理器理解
objects是Students的对象,是django.db.models.manager.Manager的一个实例。
>>>Students.objects
<django.db.models.manager.Manager at 0xb36edaec>
QuerySet
表示数据库中对象的集合,可以等同于select的语句。它是惰性的。
单条数据查询:
排序:默认按照主键id排序,可以通过模型中的_meta属性设置排序问题。
first 获取第一条,返回的是一个对象,默认按照主键id排序
>>>Students.objects.first()
<Students: 小明-16>
last 获取最后一条,默认按照主键id排序
>>>Students.objects.last()
<Students: 刘一-19>
get(**kwargs) 根据给定的条件,获取一个对象,如果有多个对象符合,则会报错。
>>>Students.objects.get(name='刘一') <Students: 刘一-19>
多条数据查询
all() 获取所有记录,返回的是QuerySet
>>> Students.objects.all()
<QuerySet [<Students: 小明-16>, <Students: XiaoHong-16>, <Students: 王五-24>, <Students: 赵柳-22>, <Students: 张三-23>, <Students: 李思-17>, <Students: 赵柳-19>, <Students: 孙奇-29>, <Students: Ats: abc-6>, <Students: 刘一-19>]>
filter(**kwargs):过滤,根据给定的条件,获取一个过滤后的QuerySet,多个条件的QuerySet语句是and连接
>>>res = Students.objects.filter(sex=1,age=16) >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE (`teacher_students`.`age` = 16 AND `teacher_students`.`sex` = 1)
exclude(**kwargs) 排除,和filter使用方法一致,作用相反,根据给定的条件,获取一个排除后的QuerySet,可以多个条件
>>>res = Students.objects.exclude(sex=1) >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE NOT (`teacher_students`.`sex` = 1)
Q:或者,多条件查询,相当于MySQL中的or,这个方法需要单独导入
需要导包
from django.db.models import Q
语法: Q(*args) |
>>> res =Students.objects.filter(Q(age=0)|Q(age=1))
SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE (`teacher_students`.`age` = 0 OR `teacher_students`.`age` = 1)
values(*fields),字段查询。可以多个查询,返回一个QuerySet,返回一个字典列表,而不是数据对象
>>> res = Students.objects.values('name') >>>print(res.query) SELECT `teacher_students`.`name` FROM `teacher_students` >>>res <QuerySet [{'name': '小明'}, {'name': 'XiaoHong'}, {'name': '王五'}, {'name': '赵柳'}, {'name': '张三'}, {'name': '李思'}, {'name': '赵柳'}, {'name': '孙奇'}, {'name': 'ABC'}, {'name': 'abc'}, {> >>>res[0]['name'] '小明'
#可以多条查询 res = Students.objects.values('name','age') #可以增加过滤 res = Students.objects.values('name').filter(age=0)
only(*field) 返回QuerySet,是一个对象列表,不是字典,而且only一定包含主键字段。此方法用的更多些。
因为是一个对象列表,所以可以有后期的其他操作,我们可以指定很少的字段后再后期继续获取,效率较高,还可以动态的拿到其他数据。
>>> res = Students.objects.only('name') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name` FROM `teacher_students` #会默认拿到id主键 >>> res[0].c_time datetime.datetime(2019, 2, 26, 8, 4, 57, 955584, tzinfo=<UTC>) #没有获取这个字段也一样可以拿到,这就是only的作用 #其他写法: res = Students.objects.only('name','age').filter(age=16)
defer(*fields) 返回一个QuerySet,和only一样用法,作用相反
>>>res = Students.objects.defer('c_time','age') >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone` FROM `teacher_students` >>>res <QuerySet [<Students: 小明-16>, <Students: XiaoHong-16>, <Students: 王五-24>, <Students: 赵柳-22>, <Students: 张三-23>, <Students: 李思-17>, <Students: 赵柳-19>, <Students: 孙奇-29>, <Students: nts: abc-6>, <Students: 刘一-19>]> >>>res[0].c_time datetime.datetime(2019, 2, 26, 8, 4, 57, 955584, tzinfo=<UTC>)
排序
order_by(*fields):根据给定的字段来排序,默认是正序,在字段名前加上-,会变成反序,可以多字段排序。
正序
>>>res = Students.objects.order_by('c_time') >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` ORDER BY `teacher_students`.`c_time` ASC #可以配合only使用: #res = Students.objects.order_by('c_time').only('name')
反序,在需要的条件前面加上'-'
>>>res = Students.objects.order_by('-c_time') >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` ORDER BY `teacher_students`.`c_time` DESC
Lower:按照小写进行排序,创建复杂查询的时候用。
Lower这个方法需要导包
from django.db.models.functions import Lower
正序
>>> res = Students.objects.order_by(Lower('name')) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` ORDER BY LOWER(`teacher_students`.`name`) ASC #LOWER是数据库本身的功能,它把字段的内容(`teacher_students`.`name`) 变成大写排序。 >>> res <QuerySet [<Students: ABC-5>, <Students: abc-6>, <Students: XiaoHong-16>, <Students: 刘一-19>, <Students: 孙奇-29>, <Students: 小明-16>, <Students: 张三-23>, <Students: 李思-17>, <Students: 王五ents: 赵柳-22>, <Students: 赵柳-19>]>
倒序
>>> res = Students.objects.order_by(Lower('name').desc()) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` ORDER BY LOWER(`teacher_students`.`name`) DESC >>> res <QuerySet [<Students: 赵柳-22>, <Students: 赵柳-19>, <Students: 王五-24>, <Students: 李思-17>, <Students: 张三-23>, <Students: 小明-16>, <Students: 孙奇-29>, <Students: 刘一-19>, <Students: Xiaents: ABC-5>, <Students: abc-6>]>
切片
等同于MySQL里面的LIMIT,OFFSET,数量量和偏移量,和python的列表切片用法相似,不支持负索引,数量量大时不用步长
***切片过后,不再支持附加的过滤条件与排序,条件需要放在切片之前。
>>>res = Students.objects.all()[:5] >>>print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` LIMIT 5 >>>res = Students.objects.all()[2:6] >>>print(res.query) #打印出他的sql语句 SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` LIMIT 4 OFFSET 2 >>>res = Students.objects.all()[::2] >>>res [<Students: 小明-16>, <Students: 赵柳-22>, <Students: 赵柳-19>, <Students: abc-6>] #得到的直接是一个list列表,不是一个对象,不能再有后续的操作
常用查询条件 ,一般使用双下划线 '__'
支持 filter、exclude、get……, LINK子句
exact:精准匹配,对象列表
>>> res = Students.objects.filter(id__exact=4) #__exact也可以不写,默认的不用写 >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`id` = 4
iexact:不区分大小写,对象列表
>>> res = Students.objects.filter(name__iexact='abc') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE abc >>> res <QuerySet [<Students: ABC-5>, <Students: abc-6>]>
contains 包含
>>> res = Students.objects.filter(name__contains='abc') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE BINARY %abc% >>> res <QuerySet [<Students: abc-6>]>
icontains 包含,不区分大小写
>>> res = Students.objects.filter(name__icontains='abc') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE %abc%
in:在……里面找
>>> res = Students.objects.filter(name__in=['abc','ABC','小明']) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` IN (abc, ABC, 小明)
range:范围,在一个范围内找。
>>> res = Students.objects.filter(age__range=(14,20)) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`age` BETWEEN 14 AND 20 >>> res <QuerySet [<Students: 小明-16>, <Students: XiaoHong-16>, <Students: 李思-17>, <Students: 赵柳-19>, <Students: 刘一-19>]>
gt:大于,gte:大于等于
#大于 方法 >>> res = Students.objects.filter(age__gt=18) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`age` > 18 #大于等于 方法 >>> res = Students.objects.filter(age__gte=18) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`age` >= 18
lt:小于,lte:小于等于
#小于方法 >>> res = Students.objects.filter(age__lt=18) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`age` < 18 #小于等于 方法 >>> res = Students.objects.filter(age__lte=18) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`age` <= 18
startswith :以……开头,大小写敏感,区分大小写
>>> res = Students.objects.filter(name__startswith='小') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE BINARY 小%
istartswith :以……开头,不区分大小写
>>> res = Students.objects.filter(name__istartswith='小') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE 小%
endswith :以……结尾,区分大小写
>>> res = Students.objects.filter(name__endswith='小') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE BINARY %小
iendswith :以……结尾,不区分大小写
>>> res = Students.objects.filter(name__iendswith='小') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` LIKE %小
isnull:返回True,False,BOOL值,对应MySQL中的IS NULL、IS NOT NULL
True/False; 做 IF NULL/IF NOT NULL 查
>>> res = Students.objects.filter(name__isnull=True) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` IS NULL >>> res = Students.objects.filter(name__isnull=False) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time` FROM `teacher_students` WHERE `teacher_students`.`name` IS NOT NULL
快速查找方法表
| 类型 | 描述 |
|---|---|
| exact | 精确匹配: polls.get_object(id__exact=14). |
| iexact | 忽略大小写的精确匹配: polls.objects.filter(slug__iexact="foo") 匹配 foo, FOO, fOo, 等等. |
| contains | 大小写敏感的内容包含测试: polls.objects.filter(question__contains="spam") 返回question 中包含 "spam" 的所有民意测验.(仅PostgreSQL 和 MySQL支持. SQLite 的LIKE 语句不支持大小写敏感特性. 对Sqlite 来说, contains 等于 icontains.) |
| icontains | 大小写不敏感的内容包含测试: |
| gt | 大于: polls.objects.filter(id__gt=4). |
| gte | 大于等于. |
| lt | 小于. |
| lte | 小于等于. |
| ne | 不等于. |
| in | 位于给定列表中: polls.objects.filter(id__in=[1, 3, 4]) 返回一个 polls 列表(ID 值分别是 1或3或4). |
| startswith | 大小写敏感的 starts-with: polls.objects.filter(question__startswith="Would"). (仅PostgreSQL 和MySQL支持. SQLite 的LIKE 语句不支持大小写敏感特性. 对Sqlite 来说,startswith 等于 istartswith) |
| endswith | 大小写敏感的 ends-with. (仅PostgreSQL 和 MySQL) |
| istartswith | 大小写不敏感的 starts-with. |
| iendswith | 大小写不敏感的 ends-with. |
| range | 范围测试: polls.objects.filter(pub_date__range=(start_date, end_date)) 返回 pub_date 位于 start_date 和 end_date (包括)之间的所有民意测验 |
| year | 对 date/datetime 字段, 进行精确的 年 匹配: polls.get_count(pub_date__year=2005). |
| month | 对 date/datetime 字段, 进行精确的 月 匹配: |
| day | 对 date/datetime 字段, 进行精确的 日 匹配: |
| isnull | True/False; 做 IF NULL/IF NOT NULL 查询: polls.objects.filter(expire_date__isnull=True). |
聚合
需要导包
from django.db.models import Count, Avg, Max, Min, Sum
通过管理器的aggregate方法
Count 统计与count(首字母小写)
小写count >>> Students.objects.filter(name__startswith='小').count() 1 大写Count >>> Students.objects.filter(sex=1).aggregate(age_count=Count('age')) {'age_count': 7}
Avg 平均数
返回一个字典,需要我们给一个key,然后生成一个字典。
>>> Students.objects.filter(sex=1).aggregate(age_avg=Avg('age')) {'age_avg': 17.4286}
Max 最大
>>> Students.objects.filter(sex=1).aggregate(age_max=Max('age')) {'age_max': 29}
Min 最小
>>> Students.objects.filter(sex=1).aggregate(age_min=Min('age')) {'age_min': 5}
Sum 求和
>>> Students.objects.filter(sex=1).aggregate(age_sum=Sum('age')) {'age_sum': 122}
分组
需要配合聚合、values、Count一起使用
通过找到字段数据后,然后对这个字段的信息进行聚合后,再分组
拿到字段为sex的,然后对sex这个字段来统计聚合后,再分组 >>> Students.objects.values('sex').annotate(num=Count('sex')) <QuerySet [{'sex': 1, 'num': 7}, {'sex': 0, 'num': 4}]> >>> Students.objects.values('age').annotate(num=Count('age')) <QuerySet [{'age': 16, 'num': 2}, {'age': 24, 'num': 1}, {'age': 22, 'num': 1}, {'age': 23, 'num': 1}, {'age': 17, 'num': 1}, {'age': 19, 'num': 2}, {'age': 29, 'num': 1}, {'age': 5, 'num': 1}, {'age': 6, 'num': 1}]> >>> res = Students.objects.values('age').annotate(num=Count('age')) >>>print(res.query) SELECT `teacher_students`.`age`, COUNT(`teacher_students`.`age`) AS `num` FROM `teacher_students` GROUP BY `teacher_students`.`age` ORDER BY NULL
4.表关系的实现
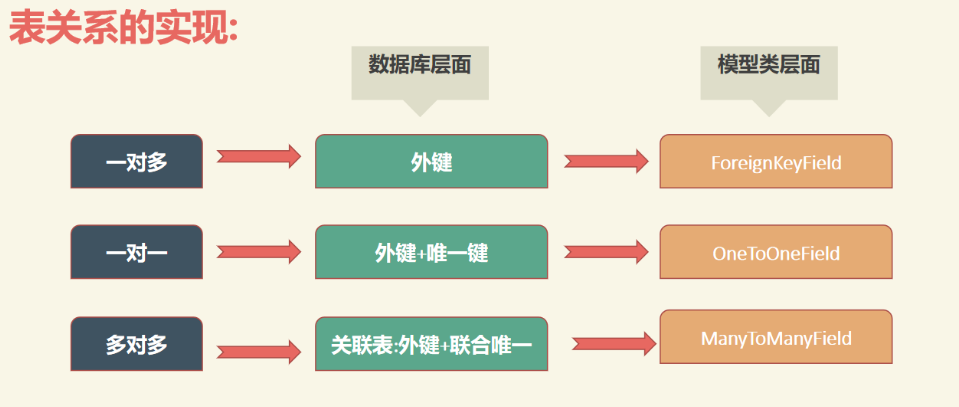
MySQL表关系的创建:在Django中创建模型来生成MySQL中表的关系。
OneToOne:一对一的表关系,OneToOneField方法
使用主键关联主键。模型类操作。
例子如上面内容所写1 from django.db import models 2 3 学生主表(一) 4 class Students(models.Model): 5 name = models.CharField(max_length=20) 6 age = models.SmallIntegerField(default=0) 7 sex = models.SmallIntegerField(default=1) 8 qq = models.CharField(max_length=20, unique=True, null=True) 9 phone = models.CharField(max_length=20, unique=True, null=True) 10 c_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) 11 e_time = models.DateTimeField(verbose_name='编辑时间', auto_now=True) 12 13 #__str__代码,表示输出格式化,是为了在ipython调试中方便查看数据,对数据库不造成任何影响,不用做数据库迁移 14 def __str__(self): 15 return '%s-%s' % (self.name, self.age) 16 17 学生详情表(一) 18 Class StudentsDetail(models.Model): 19 num = models.CharField(max_length=20, default='') 20 college = models.CharField(max_length=20, default='') 21 student = models.OneToOneField('Students', on_delete=models.CASCADE) 22 23 24 一对一的关联操作解析:'OneToOneField' 25 student = models.OneToOneField('Students', on_delete=models.CASCADE) 26 第一个参数是需要关联的表,需要字符串操作,第二个参数'on_delete=models.CASCADE'表示级联操作,如果主表有信息删除则此表信息也会跟着删除。
OneToMany:一对多的表关系,ForeignKey方法
from django.db import models 学生主表(多) class Students(models.Model): name = models.CharField(max_length=20) age = models.SmallIntegerField(default=0) sex = models.SmallIntegerField(default=1) qq = models.CharField(max_length=20, unique=True, null=True) phone = models.CharField(max_length=20, unique=True, null=True) c_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) e_time = models.DateTimeField(verbose_name='编辑时间', auto_now=True) grade = models.ForeignKey('Grade', on_delete=models.SET_NULL, null=True) 多对一关联解析:'ForeignKey':设置外键关联Grade表 grade = models.ForeignKey('Grade', on_delete=models.SET_NULL, null=True) 'on_delete=models.SET_NULL':(必须带一个null=True)代表如果关联的表对应数据被删除,则显示NULL,不会被级联删除(如果班级被删除,学生则还在,所以不能级联) 班级表(一) class Grade(models.Model): num = models.CharField(max_length=20) name = models.CharField(max_length=20)
ManyToMany:多对多的表关系,ManyToManyField
只有一个字段的多对多:(简单的多对多)
1 from django.db import models 2 3 学生主表(多) 4 class Students(models.Model): 5 name = models.CharField(max_length=20) 6 age = models.SmallIntegerField(default=0) 7 sex = models.SmallIntegerField(default=1) 8 qq = models.CharField(max_length=20, unique=True, null=True) 9 phone = models.CharField(max_length=20, unique=True, null=True) 10 c_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) 11 e_time = models.DateTimeField(verbose_name='编辑时间', auto_now=True) 12 grade = models.ForeignKey('Grade', on_delete=models.SET_NULL, null=True) 13 14 15 课程表(多) 16 class Course(models.Model): 17 name = models.CharField('课程名称', max_length=20) 18 students = models.ManyToManyField('Students') 19 20 #当你的另外一张表里面仅仅只有两个字段的时候(id+外键),Django会自动创建中间表,不需要我们自己来创建。
多张表的多对多,复杂,通过ManyToMany(多对多表)和ForeignKey(外键)来实现。
1 from django.db import models 2 3 学生主表(多) 4 class Students(models.Model): 5 name = models.CharField(max_length=20) 6 age = models.SmallIntegerField(default=0) 7 sex = models.SmallIntegerField(default=1) 8 qq = models.CharField(max_length=20, unique=True, null=True) 9 phone = models.CharField(max_length=20, unique=True, null=True) 10 c_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) 11 e_time = models.DateTimeField(verbose_name='编辑时间', auto_now=True) 12 grade = models.ForeignKey('Grade', on_delete=models.SET_NULL, null=True) 13 14 15 课程表(多) 16 class Course(models.Model): 17 name = models.CharField('课程名称', max_length=20) 18 students = models.ManyToManyField('Students',through='Enroll') 19 20 报名表(多) 21 class Enrloo(models,Model): 22 student = models.ForeignKey('Students',on_delete=models.CASCADE) 23 student = models.ForeignKey('Students',on_delete=models.CASCADE) 24 pay = models.IntegerField('缴费金额', default=0) 25 c_time = models.DateTimeField('报名时间', auto_now_add=True)
使用报名表的两个外键把学生表和报名表关联起来,来达到多对多的方法,但是想要学生表直接访问到课程表,就需要在ManyToMany的参数中设置好两张表的关联。('多对多的表',through=来源的表)
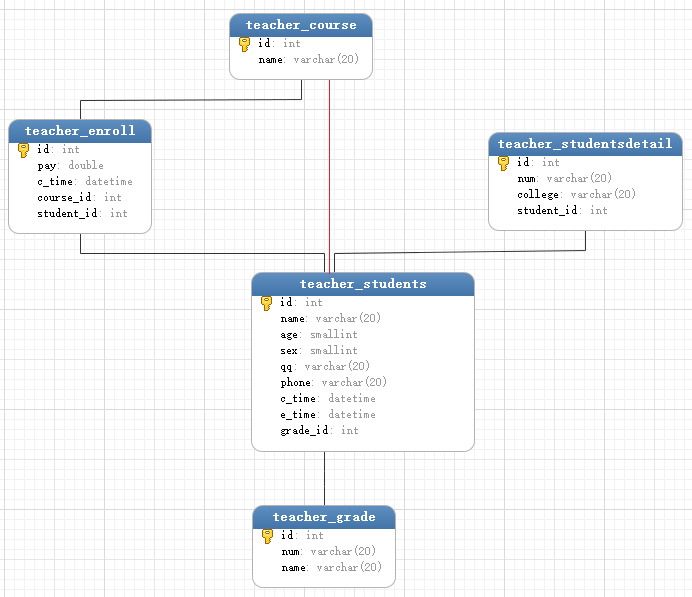
创建关系的5张表汇总代码如下。
1 ↓↓↓最后的全部代码参考↓↓↓ 2 from django.db import models 3 4 # Create your models here. 5 6 # 学生表 7 class Students(models.Model): 8 name = models.CharField(max_length=20) 9 age = models.SmallIntegerField(default=0) 10 sex = models.SmallIntegerField(default=1) 11 qq = models.CharField(max_length=20, unique=True, null=True) 12 phone = models.CharField(max_length=20, unique=True, null=True) 13 c_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) 14 e_time = models.DateTimeField(verbose_name='修改时间', auto_now=True) 15 grade = models.ForeignKey('Grade', on_delete=models.SET_NULL, null=True) 16 17 def __str__(self): 18 return '%s-%s' % (self.name, self.age) 19 20 21 # 学生详情表 22 class StudentsDetail(models.Model): 23 num = models.CharField(max_length=20, default='') 24 college = models.CharField(max_length=20, default='') 25 26 # 创建一对一需要创建的第一个参数是需要关联的表,第二个参数是主表有信息删除则此表信息也会跟着删除。 27 student = models.OneToOneField('Students', on_delete=models.CASCADE) 28 29 30 # 年级表 31 class Grade(models.Model): 32 num = models.CharField(max_length=20) 33 name = models.CharField(max_length=20) 34 35 36 # 课程表 37 class Course(models.Model): 38 name = models.CharField(max_length=20) 39 student = models.ManyToManyField('Students', through='Enroll') 40 41 42 # 报名表 43 class Enroll(models.Model): 44 student = models.ForeignKey('Students', on_delete=models.CASCADE) 45 course = models.ForeignKey('Course', on_delete=models.CASCADE) 46 pay = models.IntegerField('缴费金额', default=0) 47 c_time = models.DateTimeField('报名时间', auto_now_add=True)
输出的结果通过工具查看他的导向图:
sqlmigrate 从迁移获取sql语句:获取创建表的sql语句
>>> python manage.py sqlmigrate teacher 0001
解析: teacher:appname 0001:Django的迁移执行文件
| 参数 | 作用 |
|---|---|
| on_delete=models.CASCADE | 级联关系,级联的表对应的数据删除,此表的对应的数据就删除,保证同步删除。 |
| on_delete=models.SET_NULL (必须带一个null=True) | 代表如果关联的表对应数据被删除,则显示NULL,不会被级联删除(如果班级被删除,学生则还在,所以不能级联) |
关联表的数据操作
One-To-Many:一对多and多对一
正向的增删改查:
一个模型如果定义了一个外键字段,通过这个模型的操作外键就是正向。
现在我们开始操作数据库:
首先给年级表teacher_grade表增加几条数据
| id | num | name |
|---|---|---|
| 1 | 33期 | django框架 |
| 2 | 34期 | 爬虫 |
以下代码为清除数据后的新表,代码是和前面的有关联的,变量和前面的有关。
赋值增加:通过外键字段得到关联表的数据
第一种方法:通过赋值方式添加数据,使用获取到的关联表的数据,通过本表的外键接受数据,然后保存即可。
通过获取到的数据,赋值给当前表的外键字段,然后保存。 # 先拿到Grade的一条数据 >>> g1 = Grade.objects.first() # 获取一个Students的空对象 >>> s = Students() # 给对象添加一个name字段的数据 >>> s.name = '张三' # 把g1的数据复制给Students的grade的字段,然后得到数据。 >>> s.grade = g1 # 保存 >>> s.save()
第二种方法:通过外键字段得到关联表的数据,用对象的外键字段名接受关联表的数据(id获取)
>>> s2 = Students(name='李四') >>> g2 = Grade.objects.last() # 用对象的外键字段名接受关联表的数据,需要是关联表的主键id >>> s2.grade_id = g2.id >> sa.save()
更新和修改
也可以通过赋值来操作
# 把对象的外键grade字段拿来接受g2的对象数据,以达到修改 >>> s.grade = g2 >>> s.save()
删除外键数据
# 通过赋值None来操作 >>> s.grade = None >>> s.save()
查询
# 通过外键去拿到关联的数据 >>> s2.grade.name '爬虫'
反向的增删改查
一个模型被另外一个模型的外键关联,通过这个模型对关联他的这个模型操作就是反向。
通过被关联表名的小写加上set来操作。管理器范式(小写_set)
增加
#在创建的同时,也直接把g2的对象数据一起增加了,此方法立刻执行 >>> g2.students_set.create(name='王五') <Students: 王五-0> #把已有的对象通过add方法增加关联的数据,此方法立刻执行,如果本身自带了数据,则自动修改为本对象的数据 >>> g2.students_set.add(s)
查询
>>> g2.students_set.all() <QuerySet [<Students: 张三-0>, <Students: 李四-0>, <Students: 王五-0>]> #查询的所有方法都可以使用,这里只做一个例子
删除
#删除单条 >>> g2.students_set.remove(s, s2) #删除所有 >>> g2.students_set.clear()
set方法,接受对象列表,此方法是先执行clear后,再执行set添加。
把本来有的对象删除后,再添加新的对象
# 获取对象后,添加到本对象的表中 >>> g3.students_set.set([s, s2]) >>> g3.students_set.all()
通过本表的外键查询关联表的关于本表的数据
通过学生表查询年级表的所有学生,用外键字段加上__和关联表的字段名, 字段查询,不能全部查询
# 使用本表的外键查询('外键'+'__'+'关联表字段名') >>> res = Students.objects.filter(grade__name='爬虫') >>> res <QuerySet [<Students: 张三-0>, <Students: 李四-0>, <Students: 赵柳-0>]> >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time`, `teacher_students`.`e_time`, `teacher_students`.`grade_id` FROM `teacher_students` INNER JOIN `teacher_grade` ON (`teacher_students`.`grade_id` = `teacher_grade`.`id`) WHERE `teacher_grade`.`name` = 爬虫
Many-To-Many:多对多
多对多的两端都可以获得自动API去访问,访问的原理和一对多的反向有点类似,但是有一个不同的地方是多对多的模型使用的是本字段的属性名,而反向的是使用原始模型的小写加上set。下面我们来看怎么操作。
指定了中间表后,add、remove、set都不能用,必须用中间表。
首先增加几个课程数据(Course)来实现例子:
| id | name |
|---|---|
| 1 | pyton全栈 |
| 2 | Java全栈 |
| 3 | English |
查看一下当前Students表数据
| id | name | age | sex | phone | c_time | e_time | grade_id | |
|---|---|---|---|---|---|---|---|---|
| 1 | 张三 | 0 | 1 | 2019-02-28 11:09:52.462364 | 2019-02-28 11:34:21.636189 | 2 | ||
| 2 | 李四 | 0 | 1 | 2019-02-28 11:18:47.456735 | 2019-02-28 11:18:47.456806 | 2 | ||
| 3 | 王五 | 0 | 1 | 2019-02-28 11:52:15.526063 | 2019-02-28 11:52:15.526134 | null |
add、remove、set都是没有指定中间表(through='Enroll')的时候才可以使用,不能使用用在对多的字段,当他指定这个的时候,就不能使用。
# 把创建出来的Course对象获取到变量中得到c1, c2, c3 >>> c1,c2,c3 = Course.objects.all() # 把创建出来的Students对象获取到变量中得到s1, s2, s3 >>> s1,s2,s3 = Students.objects.all()
增加
# 获取一个空对象 >>> e = Enroll() # 把c1的对象赋值给Enroll的这个对象 >>> e.course = c1 # 把s1的对象赋值给Enroll的这个对象 >>> e.student = s1 >>> e.save() #用两个外键字段名接受 关联表对象的数据。然后保存,可以得到一条外键关联的数据。
结果得到的Enroll表数据为:
| id | pay | c_time | course_id | student_id |
|---|---|---|---|---|
| 1 | 0 | 2019-03-01 04:18:12.193959 | 1 | 1 |
#用外键字段名id接受关联的对象id >>> e.course_id = c2.id >>> e.student_id = s2.id >>> e.save()
结果到的Enroll表为:
| id | pay | c_time | course_id | student_id |
|---|---|---|---|---|
| 1 | 0 | 2019-03-01 04:18:12.193959 | 1 | 1 |
| 2 | 0 | 2019-03-01 04:24:53.105775 | 2 | 2 |
create方法创建,直接操作数据库
# 使用creat方法可以一起指定外键,然后创建 >>> Enroll.objects.create(sudent=s1,course=c3)
表中ManyToMany方法的应用。
#创建表的时候的代码解析: student = models.ManyToManyField('Students', through='Enroll') #Course表中的的字段,并不会在数据库中创建,而是django中需要配置的管理器。他可以很方便的在查询中起到作用。
我们来应用这个管理器,他可以很方便的查询到我们需要的数据,不是一个字段,我们可以在不使用第三张表(Enroll表)介入的时候,让Students和Course两个相互访问。
# 在course表中,使用的ManyToMany是一个管理器 >>> c1.student <django.db.models.fields.related_descriptors.create_forward_many_to_many_manager.<locals>.ManyRelatedManager at 0xaff763ec> # 查找c1下面的所有学生 >>> c1.student.all() <QuerySet [<Students: 张三-0>]> # 查找学生报名的所有课程 >>> s1.course_set.all() <QuerySet [<Course: pyton全栈>]>
One-To-One 一对一
增加
>>> sd = StudentsDetail.objects.create(num='20190301001', college='家里蹲', student=s1) >>> sd <StudentsDetail: 家里蹲-20190301001>
查询
>>> sd.student <Students: 张三-0> >>> sd.student.name '张三'
在一对一的关系中,可以通过关联表的模型名的小写(是对象,不是管理器),来拿到需要的数据,没有_set
>>> s1.studentsdetail <StudentsDetail: 家里蹲-20190301001> >>> s1.studentsdetail.num '20190301001'
跨表查询
跨模型的相关字段的字段名,并且用双下划綫'__'去分割,直到达到想要获取的字段位置。
通过例子来查看如何跨表查询
查询男生都报名了什么课程:
# 用相关联的字段名+'__'关联表的字段名 >>> res = Course.objects.filter(student__sex=1) >>> print(res.query) SELECT `teacher_course`.`id`, `teacher_course`.`name` FROM `teacher_course` INNER JOIN `teacher_enroll` ON (`teacher_course`.`id` = `teacher_enroll`.`course_id`) INNER JOIN `teacher_students` ON (`teacher_enroll`.`student_id` = `teacher_students`.`id`) WHERE `teacher_students`.`sex` = 1
反向查询:用对应的模型名的小写。
查询所有报名python课程的学员:
#模糊查询用contains >>> res = Students.objects.filter(course__name__contains='python') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time`, `teacher_students`.`e_time`, `teacher_students`.`grade_id` FROM `teacher_students` INNER JOIN `teacher_enroll` ON (`teacher_students`.`id` = `teacher_enroll`.`student_id`) INNER JOIN `teacher_course` ON (`teacher_enroll`.`course_id` = `teacher_course`.`id`) WHERE `teacher_course`.`name` LIKE BINARY %python%
and关系
查询所有报名英语的33期的学员:
>>> res = Students.objects.filter(course__name__contains='englist',grade__num__contains='33期') >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time`, `teacher_students`.`e_time`, `teacher_students`.`grade_id` FROM `teacher_students` INNER JOIN `teacher_enroll` ON (`teacher_students`.`id` = `teacher_enroll`.`student_id`) INNER JOIN `teacher_course` ON (`teacher_enroll`.`course_id` = `teacher_course`.`id`) INNER JOIN `teacher_grade` ON (`teacher_students`.`grade_id` = `teacher_grade`.`id`) WHERE (`teacher_course`.`name` LIKE BINARY %englist% AND `teacher_grade`.`num` LIKE BINARY %33期%)
查询所有缴费金额小于3000的学员:
>>> res = Students.objects.filter(enroll__pay__lt=3000) >>> print(res.query) SELECT `teacher_students`.`id`, `teacher_students`.`name`, `teacher_students`.`age`, `teacher_students`.`sex`, `teacher_students`.`qq`, `teacher_students`.`phone`, `teacher_students`.`c_time`, `teacher_students`.`e_time`, `teacher_students`.`grade_id` FROM `teacher_students` INNER JOIN `teacher_enroll` ON (`teacher_students`.`id` = `teacher_enroll`.`student_id`) WHERE `teacher_enroll`.`pay` < 3000.0
查询所有报名python的班级有哪些
>>> res = Grade.objects.filter(students__course__name__contains='python') 通过学生表去查课程名称之后, >>> print(res.query) SELECT `teacher_grade`.`id`, `teacher_grade`.`num`, `teacher_grade`.`name` FROM `teacher_grade` INNER JOIN `teacher_students` ON (`teacher_grade`.`id` = `teacher_students`.`grade_id`) INNER JOIN `teacher_enroll` ON (`teacher_students`.`id` = `teacher_enroll`.`student_id`) INNER JOIN `teacher_course` ON (`teacher_enroll`.`course_id` = `teacher_course`.`id`) WHERE `teacher_course`.`name` LIKE BINARY %python%
跨表查询小节:需要查询的结果表名放在前面,然后把要查询的内容放在括号内。