| 这个作业属于哪个课程 | 软件工程1916|W(福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对学号 | 221600117|221600122 |
| 这个作业的目标 | 实现一个能够对文本文件中的单词的词频进行统计的控制台程序。 |
| Github仓库地址 | github |
1.Github的代码签入记录
2.具体分工
我们两个在这次作业中一起实现了基础部分的实现,每个人写了两个功能,队友主要负责基础部分代码的编写和单元测试部分,还有git的使用方法的学习,基础部分博客编写。我主要负责进阶部分的代码编写与相关部分的博客。
3.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 480 | |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 150 |
| • Design Spec | • 生成设计文档 | 15 | 20 |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 5 | 1 |
| • Design | • 具体设计 | 20 | 10 |
| • Coding | • 具体编码 | 180 | 240 |
| • Code Review | • 代码复审 | 30 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 20 | 15 |
| • Size Measurement | • 计算工作量 | 10 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 5 |
| 合计 | 480 | 521 |
4.解题思路
首先拿到题目后,看完了整个题目后,感觉基础部分实现起来并不是特别困难,我们就准备第二天开始着手解决基础部分的代码。我先学习了git的使用方法,通过百度找一些别人写的博客了解了git的基本使用方法。这部分花了一上午的时间。
在接下来就是对于代码实现题目的思考。看到题目要求对字符进行处理统计,就决定使用C++来实现,因为C++对字符的操作更加简单,也不需要特别复杂的操作。
找资料的过程就是通过在网上搜索一些c++中对字符处理的函数方法,距离上次使用C++已经有一段时间了,这次正好复习了一下C++。
看到需求中有要求对代码进行单元测试,还有进行性能分析。这些以前都没有做过,所以学起来也花了一部分时间。网上对于这两部分的讲解资料并不是特别多。
5.设计实现过程
因为题目中有要求对接口的封装:
大家的代码都各有特色,如果现在我们要把这个功能放到不同的环境中去(例如,命令行,Windows图形界面程序,网页程序,手机App),就会碰到困难:代码散落在各个函数中,很难剥离出来作为一个独立的模块运行以满足不同的需求。
几个功能独立出来,成为一个独立的模块(class library, DLL, 或其它),这样的话,命令行和GUI的程序都能使用同一份代码。为了方便起见,我们称之为计算核心"Core模块",这个模块至少可以在几个地方使用:
- 命令行测试程序使用
- 在单元测试框架下使用
- 与数据可视化部分结合使用
所以就决定使用四个函数,分别来实现对文章字符数量的统计,对文章单词数的统计和对文章行数的统计,以及前十高词频的单词统计。
如图,在需求一种,countChar,countLine,countWord,sortWord分别对应四个功能,在主程序Word Count中可以直接调用。在设计函数的时候并没有设计流程图,因为他们都是独立的单元,先实现了最简单的功能,然后后面的函数构造都按第一个实现好的函数的形式写就可以。
单元测试的部分通过对各个函数进行了测试,每个函数用了三组不同的输入数据。一共设计了四个测试函数,对一下情况进行了测试:
- 测试字符数是否正确
- 统计单词数是否正确
- 测试行数是否正确
- 测试如果是不存在的文件
- 测试如果是空文件
算法设计过程
需求一
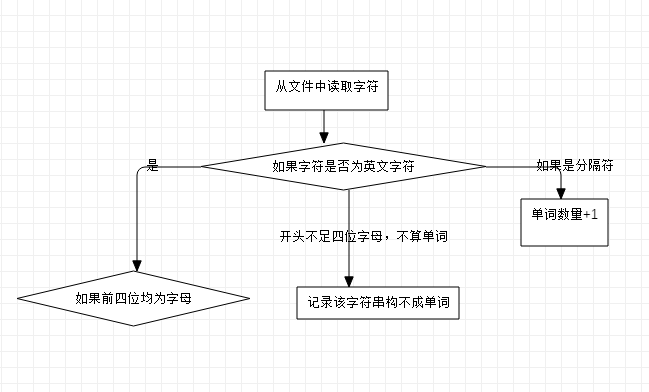
这是统计单词数量的算法流程图,题目中要求统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。于是就需要记录单词开头的字母数量,来进行判断。如果超过了四个以上的字母,说明该字符串为单词,如果读到了分隔符,单词数就加一。开头字母数从头开始计算,读到数字如果已经不构成单词,就把标志位设为-1。
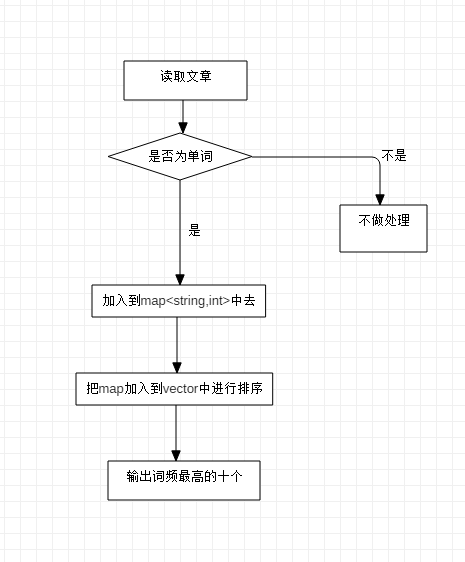
这是对词频进行排序的流程图。因为无法直接对map直接进行排序,所以用到了vector中的pair,把map加入到vector中来进行排序再进行输出。
统计单词数的代码
while((ch = fgetc(file)) != EOF)
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
{
if (f >= 0)//单词前四位是字母
f++;
else//单词前字母不足四位,后面字母不记录
f = -1;
}
else if (ch >= '0' && ch <= '9' && f < 4)//开头不足四位字母,不算单词
{
f = -1;
}
else//读到分隔符
{
if (f >= 4)
cnt++;
f = 0;
}
}
//若最后一个单词符合条件且到文件末尾
if (f >= 4)
cnt++;
统计行数的代码
while ((ch = fgetc(file)) != EOF)
{
//遇到换行符
if (ch == '
')
{
//本行内容为非空字符
if (f > 0)
cnt++;
f = 0;
}
//遇到非空字符
else if(ch != ' ' && ch != ' ')
f++;
}
//最后一行不含回车符,特殊判断
if (f > 0)
cnt++;
统计字符数的代码
while(fgetc(file) != EOF)
{
cnt++;
}
排出前十词频的单词代码
while ((ch = fgetc(file)) != EOF)
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
{
if (ch >= 'A' && ch <= 'Z')
{
ch += ('a' - 'A');
}
if (f >= 0)//单词前四位是字母
{
f++;
temp += ch;
}
else//单词前字母不足四位,后面字母不记录
f = -1;
}
else if (ch >= '0' && ch <= '9')//开头不足四位字母,不算单词
{
if (f < 4)
f = -1;
else
temp += ch;
}
else//读到分隔符
{
if (f >= 4)
{
cnt++;
wmap[temp]++;
}
f = 0;
temp = "";
}
}
if (f >= 4)
{
cnt++;
wmap[temp]++;
}
MapSortOfValue(vec, wmap);
需求二
爬虫:使用java的jsoup库爬取HTML文档,然后生成DOM文档。在DOM树上,寻找到每一篇论文中的href链接发送请求,对于收到的文本中,解析出需要的Title和Abstract内容。
除了统计词组相对于需求一有比较大的变化,其他都是在需求一上做更多的判除操作,对于序号以及论文中的Title与Abstract要不加入计算,所以统计字符时也要加入单词的判断,这些与需求一大致相同,就不多加赘述。
统计词组方面,主要难点是解决规定的词组长度截取以及注意不能跨越两个栏目,解决思路是:利用一个向量来模拟队列。规定队列长度为词组长度,新单词进入加入队尾,超过长度则抛出队头,当队伍长度等于词组长度时,队列就是保留一个合法词组。当遇到Title与Abstract时,队列清空,就可以做到不跨越两个栏目。剩下排序就和需求一相同。核心部分流程图如下:
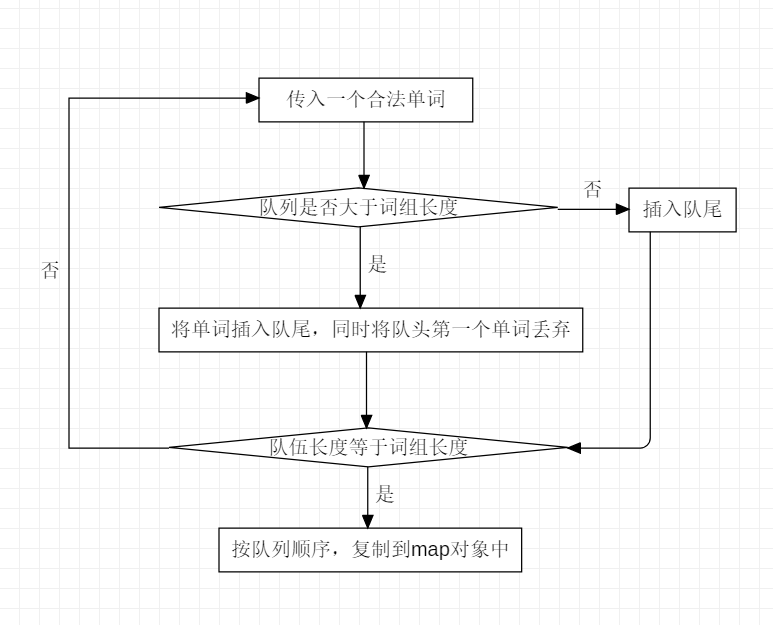
核心代码如下:
//......
while ((ch = fgetc(file)) != EOF)
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
{
if (ch >= 'A' && ch <= 'Z')
{
ch += ('a' - 'A');
}
if (f >= 0)//单词前四位是字母
{
f++;
temp += ch;
}
else//单词前字母不足四位,后面字母不记录
f = -1;
}
else if (ch >= '0' && ch <= '9')//开头不足四位字母,不算单词
{
if (f < 4)
f = -1;
else
temp += ch;
}
else//读到分隔符
{
//当遇上title或者abstract时,模拟队列清空
if (temp == "title" && temp == "abstract")
que.clear();
if (f >= 4 && temp != "title" && temp != "abstract")
{
que.push_back(temp);
//维持词组的规定长度
if (que.size() > Len)
que.erase(que.begin());
//符合长度,加入词组map中
if (que.size() == Len)
{
tt = "";
k = 0;
for (vt = que.begin(); vt != que.end(); vt++)
{
k++;
tt += *vt;
if (k < Len)
tt += " ";
}
wmap[tt]++;
}
}
f = 0;
temp = "";
}
}
//......
6.需要改进的地方
在计算词频出现的时候,需要判断是否为单词,这部分和在统计单词数量的时候的代码有部分重合了,也就是说需要重复的计算相同的部分,会花掉一部分时间,这部分代码的设计存在着问题。
7.单元测试部分
部分代码如下
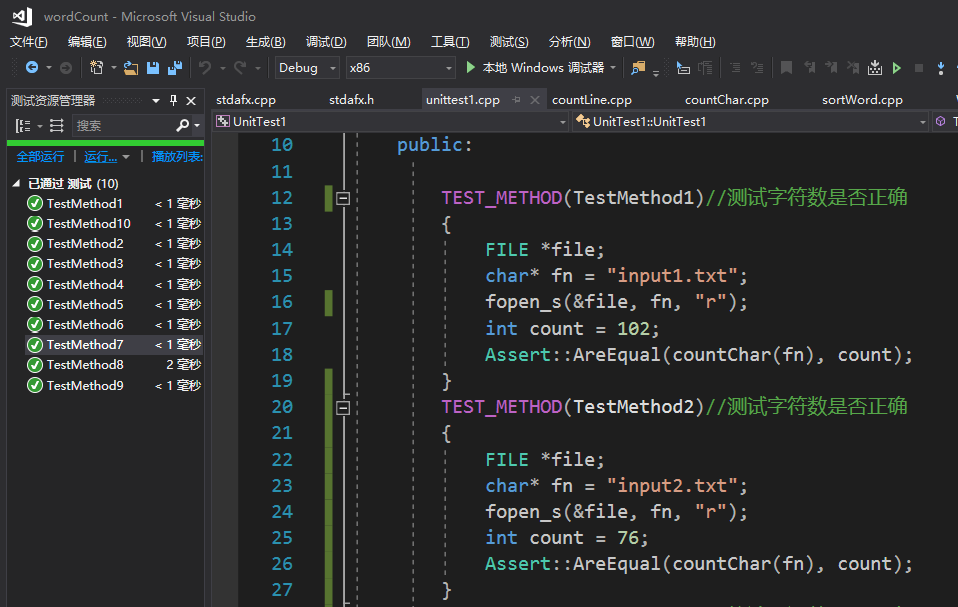
TEST_METHOD(TestMethod1)//测试字符数是否正确
{
FILE *file;
char* fn = "input1.txt";
fopen_s(&file, fn, "r");
int count = 102;
Assert::AreEqual(countChar(fn), count);
}
这是一段测试字符数是否正确的代码,通过input1.txt的文件传入数据,然后验证字符数是否与预计数相等。
经过测试,10个测试点均通过测试。测试代码的思路上面已经提到。
8.性能分析
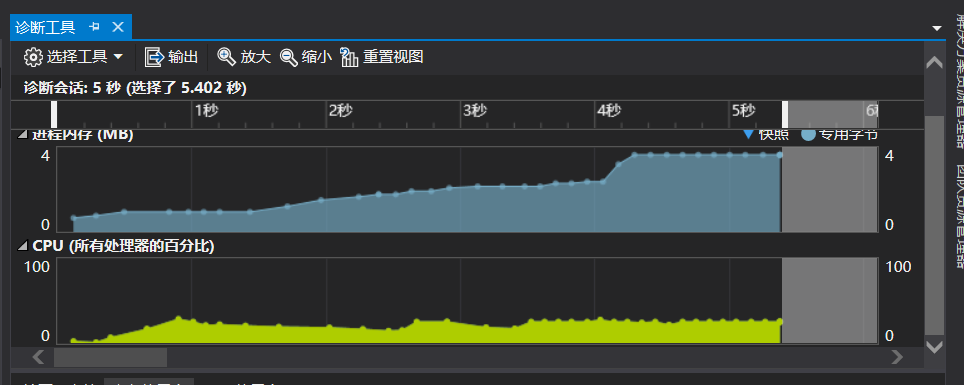
通过图片可以明显看出,在统计词频或者词组频率(后面的提高部分)中所需要的运算量更大,所以更加耗费计算机资源。
9.遇到的困难
关于单元测试和性能分析,是以前从来没有接触过的,只能在网上查找资料来学习。但是相关的资料非常的不好找。所以资料就花掉了很多时间。还有git的使用,不过还好有Linux使用的基础,学起来也还相对轻松。
剩下的困难就是在代码方面的困难了。理解题目需求花了很多时间,经常写着写着发现好像不符合题目的要求,然后就又重新改。
解决办法就是一定要先理解了需求,再开始着手。不然后期会很麻烦,前面努力都白费了。
10.评价队友
队友是一个很积极的人,而且能够很好的完成分工任务。两个人在分配好任务后,分别在约定的时间下完成自己的任务,使得整个过程比较顺利。能够遇上这样的队友,还是比较幸运的!