1 实验目的
1.1论文信息
作者:Cornelius Aschermann, Sergej Schumilo, Ali Abbasi, and Thorsten Holz
出处:2020 IEEE Symposium on Security and Privacy (S&P 20)
1.2 文章摘要解读
目前的模糊测试(fuzzing)方法是非常有效的,但仍有许多情况下,如复杂状态机的全自动方法失败。在这种情况下,最先进的模糊化方法为人类提供了非常有限的交互和帮助模糊者的能力。更具体地说,目前的大多数方法仅限于添加字典或新的种子输入来指导模糊器。在处理复杂程序时,这些机制无法发现代码库的新部分。
在这篇文章中,作者提出了IJON,一个分析人员可以用来引导模糊者的注释机制(annotation mechanism)。与上述两种技术相比,这种方法允许基于表示程序内部状态的数据对程序的行为进行更系统的探索。因此,只要使用很少的(通常是一行)注释,用户就可以帮助fuzzer解决以前无法解决的难题。作者扩展了各种基于AFL的模糊器(fuzzer),使之能够用指导提示注释目标应用程序的源代码。作者的评估表明,这种简单的注释能够解决我们所知的问题——目前没有其他的基于模糊器或符号执行的工具能够克服这些问题。例如,通过使用作者的扩展,fuzzer能够玩并解决超级马里奥兄弟(Super Mario Bros)之类的游戏,或者解决更复杂的模式,比如哈希映射散列图查找。为了进一步展示注释的功能,作者使用AFL和IJON来发现新的安全性问题和以前需要一个自定义的和全面的语法才能发现的问题。最后,作者证明,使用IJON和AFL,可以解决迄今为止抵制了所有全自动和人工引导的尝试的CGC数据集的许多挑战。
2 实验内容及原理
2.1 程序状态空间
状态空间代表程序所有可能状态的集合,状态代表内存和寄存器的一种配置,以及系统提供的状态(比如文件描述符、类似原语)。状态空间比代码覆盖统计空间更大,若改造AFL就需要实现对状态空间的支持,以优化测试用例达到状态的多样性。
2.2 主要设计原理
作者设计了一套源码注释原语,其实就是给源码加个一两行补丁代码,用来干预Fuzzer的反馈功能。在可交互的Fuzzing会话中,分析人员可以人工介入去分析一直无法触达的执行路径,然后为其增加补丁代码解决路径探索障碍的问题。
afl-gcc或afl-clang本身就是对gcc/clang编译器的封装,添加一些编译选项,以及代码插桩的功能,作者为其编写了个链接库,以实现前面所说的注释原语,包括一些自定义函数和宏等,通过它能够访问AFL用于存储覆盖信息的位图(其实是个哈希表),直接添加和设置条目上去,将状态值直接反馈给Fuzzer。同时,也允许相同的edge coverage存储到不同的覆盖位图中,因为不同的状态值可能触发的是同一处edge coverage,这代表它能够实现更细粒度的反馈,为此它还提供扩展用于存储覆盖位置的共享内存区域。对于状态空间爆炸的问题,也会提供"爬山算法”(hill-climbing)作出优化选择。
作者对超级玛丽作了修改,使所有的键盘命令都可以从标准输入中读取,并且马里奥只能不停地向右跑,只要停下来就死掉,这个设计主要是为节省时间。
作者还用改造后的Ijon与AFL作对比,运行12小时的AFL看其能打到哪一关,而使用注释原语的Ijon只几分钟就通过了大部分的关卡,有些确实过不了。下图是超级玛丽打喷火怪兽那关,线条是Fuzzer发现的所有执行路径,对比还是比较明显的,AFL暴力探测的密集度比较明显,更关键还是没通关,从作者统计图上可以看到(图1所示)。
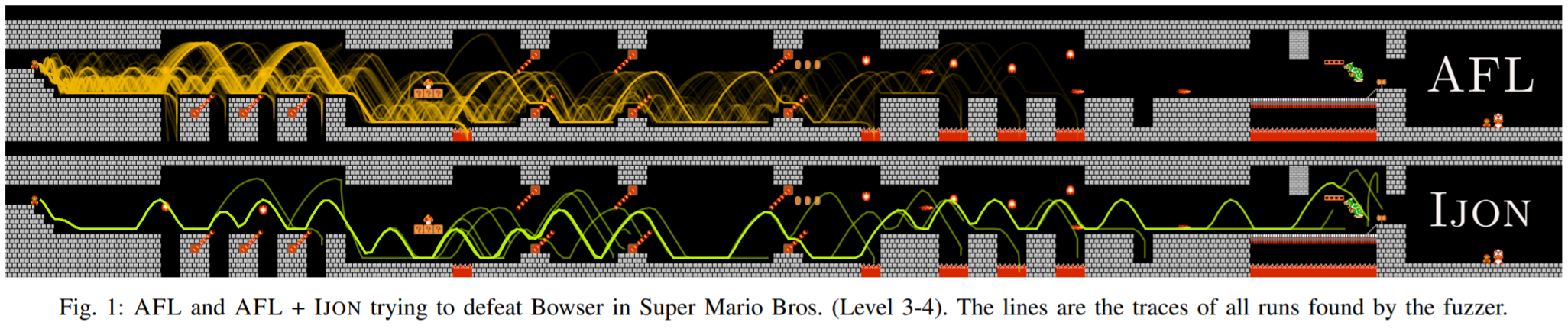
图1
2.3 文章介绍
近年来,fuzzing的研究重心放在了进一步改进fuzzing方法上,通常是为了获得更大的代码覆盖率并更深入地研究给定的软件应用程序。但是,仍然存在大量的open challenge,无论是symbolic/concolic execution还是fuzzing都难以解决。很大程度上是因为在一般情况下根本无法确定潜在的问题,即fuzzing的方向性。
本文针对的问题:探索复杂的状态机
当前fuzzing的方法难以探索复杂的状态机。这些状态机的状态变化主要反映在程序状态数据的更改中。由于状态数据的更新都是由某些代码触发的,因此coverage-based fuzzer能够地探索每个单独的更新。但是如果先前已观察到所有单独的更新,则没有反馈可奖励探索导致新状态的不同更新的组合,使得fuzzer很难产生特定的更新顺序来发现错误。
类似地,因为确切的更新顺序(以及因此选择的精确代码路径)对于发现错误至关重要,所以concolic execution也会失败。由于concolic execution将路径固定为观察到的执行路径,因此求解器无法获得触发目标条件的输入。最后,如果状态空间变得太大,那么即使可以自由探索不同路径的完全符号执行也会失败。
有一种复杂的解决方案仅基于符号执行来支持最少的环境/指令集,以克服fuzzing中的挑战。然而此类方法无法很好地扩展到复杂的应用程序,成本较高,工业界很少使用。
“Computers are incredibly fast, accurate and stupid; humans are incredibly slow, inaccurate and brilliant; together they are powerful beyond imagination”
作者探索了分析人员如何操纵fuzzer来克服当前的挑战。主要基于两点观察的启发:“相比计算机,分析人员更擅长制定high level的战略计划,而计算机胜在执行力。所以在很多领域中常常使用 “human-in-the-loop” 这种方法。”许多模糊测试从业人员在其fuzzing过程中使用封闭的反馈回路:首先,运行fuzzer一段时间,然后分析代码覆盖率。经过手动分析后,调整fuzzing过程以增加覆盖率。改善fuzzing性能的常见策略包括从目标应用程序中删除具有挑战性的部分(e.g.,校验和)、更改mutation策略或显式添加输入样本以解决fuzzer无法自动生成的某些约束。
作者相信,通过辅助和控制fuzzing过程,与fuzzer进行交互的人员可以大大提高fuzzing分析应用程序的能力,并克服当前的许多障碍。具体来说,作者将重点放在一类特殊的挑战上:当前的fuzzer无法在代码覆盖率之外正确探索程序的状态空间(无法探索导致相同代码覆盖率但状态值不同的程序执行)。作者的方法中,分析人员可以注释那些更应该彻底地探索的状态空间的部分,从而修改fuzzer的反馈功能。
为了证明方法的可行性,作者扩展了各种基于AFL的fuzzer,通过注释目标应用程序以指导fuzzer。作者将其扩展命名为IJON(Stanislaw Lem书中著名的太空探险家Ijon Tichy)。四个案例表明注释可以帮助克服重大障碍并探索更多有趣的行为。例如,使用简单的注释,可以玩Super Mario Bros.,并可以从CGC挑战数据集中解决困难的情况。
2.4 论文贡献
系统地分析当前fuzzer实现的反馈方法,研究它们如何表示状态空间,并研究在哪些情况下会失败;
为当前feedback fuzzer设计了一组扩展,这些扩展使分析人员可以在应用程序的状态空间中引导fuzzer以解决当前方法无法克服的困难约束
在几个案例研究中演示了如何使用这些注释来探索目标应用程序的更深层行为。作者展示了fuzzer如何有效地探索可信平台模块(TPM)、复杂格式解析器、游戏Super Mario Bros.、迷宫和哈希映射实现的软件仿真器的状态空间。此外,作者证明了其方法能够解决CGC数据集中的一些最困难的挑战,并在实际软件中发现新的漏洞。
2.5 理论背景
作者的工作基于AFL家族的fuzzer,它们通常试图从程序的状态空间中找到一个能触发多种不同状态的语料库。这里的状态表示存储器和寄存器的一种配置,以及由OS提供的状态(例如,文件描述符和类似的原语)。状态空间是程序可能处于的所有可能状态的集合。由于状态空间非常庞大,fuzzer必须优化测试test case以达到更多更有趣的状态。此类fuzzer通常使用代码覆盖率来确定输入是否达到与语料库中存在的状态足够不同的状态。
2.5.1 AFL Coverage Feedback
AFL类型的fuzzer跟踪在每个测试用例输入期间CFG中各个边被执行的频率,插入到目标应用程序中的探针将计算CFG中每条边的频率并将其存储。
局部的共享映射(shared map):该映射会在每次测试运行期间累积所有边缘的计数
全局的位图(bitmap):包含整个fuzzing中遇到的所有边缘覆盖率,用于快速判断测试输入是否触发了新的覆盖率
如果在任何一条边上出现了新的执行次数,AFL就认为这个测试输入是有趣的并将其存储。由于边始终连接两个基本块,因此被编码为包含两个标识符的元组((id_s,id_t))。
2.5.2 Extending Feedback Beyond Coverage
fuzzing有时会卡在搜索空间的一部分中,这是因为没有任何可能的突变会提供新的反馈。先前的一些方法可以将反馈机制扩展到代码覆盖率外,从而避免陷入平稳状态。 * LAF-INTEL 通过将大型比较指令拆分为多个较小的比较指令来解决magic byte类型约束。 * STEELIX 使用动态二进制工具来实现相同的方法,将多字节比较指令拆分为多个单字节指令后,每当操作数的一个字节匹配时,fuzzer便可以查找新的覆盖范围。 * ANGORA 为每个函数分配一个随机标识符。它使用这些标识符将覆盖元组扩展到第三个字段,该字段包含当前执行上下文的哈希值。如果在不同的调用上下文中出现了“相同”的覆盖率,则可以找到它。此方法有助于解决对strcmp函数的多次调用。然而,这种方法的缺点是将所有调用上下文视为唯一的,很可能产生大量实际上并不有趣的输入,也就需要更大的位图。
2.6 设计开发
fuzzer会尝试从状态空间的“有趣”区域中尽可能高效地进行采样,但是很难找到一个准确客观的指标来衡量任何给定输入的状态空间有多“有趣”。 AFL家族的整体成功表明遵循边缘覆盖率是识别新的有趣区域的有效指标,因为在大多数程序中,每个新边缘都表示一种特殊情况。但是在某些代码构造中,如果不探索状态空间中的中间点就不可能产生新的覆盖率。而这种中间点需要用户在概念上进行描述来为fuzzer提供附加反馈。实际上是通过用户交互,来提供具有适应性的更有针对性的metric作为feedback
2.6.1 State Exploration
为了确定使用当前技术难以fuzz的代码结构,作者使用了最新的fuzzer进行实验,并手动检查获得的覆盖率。主要有以下三个问题:
(1)已知的相关状态值: 有时代码覆盖率几乎不产生有关程序状态的信息,因为所有感兴趣的状态都存储在数据中。如果分析人员了解存储有趣状态的变量,则可以将状态直接反馈给fuzzer,然后fuzzer便可以探究导致不同内部状态的输入。
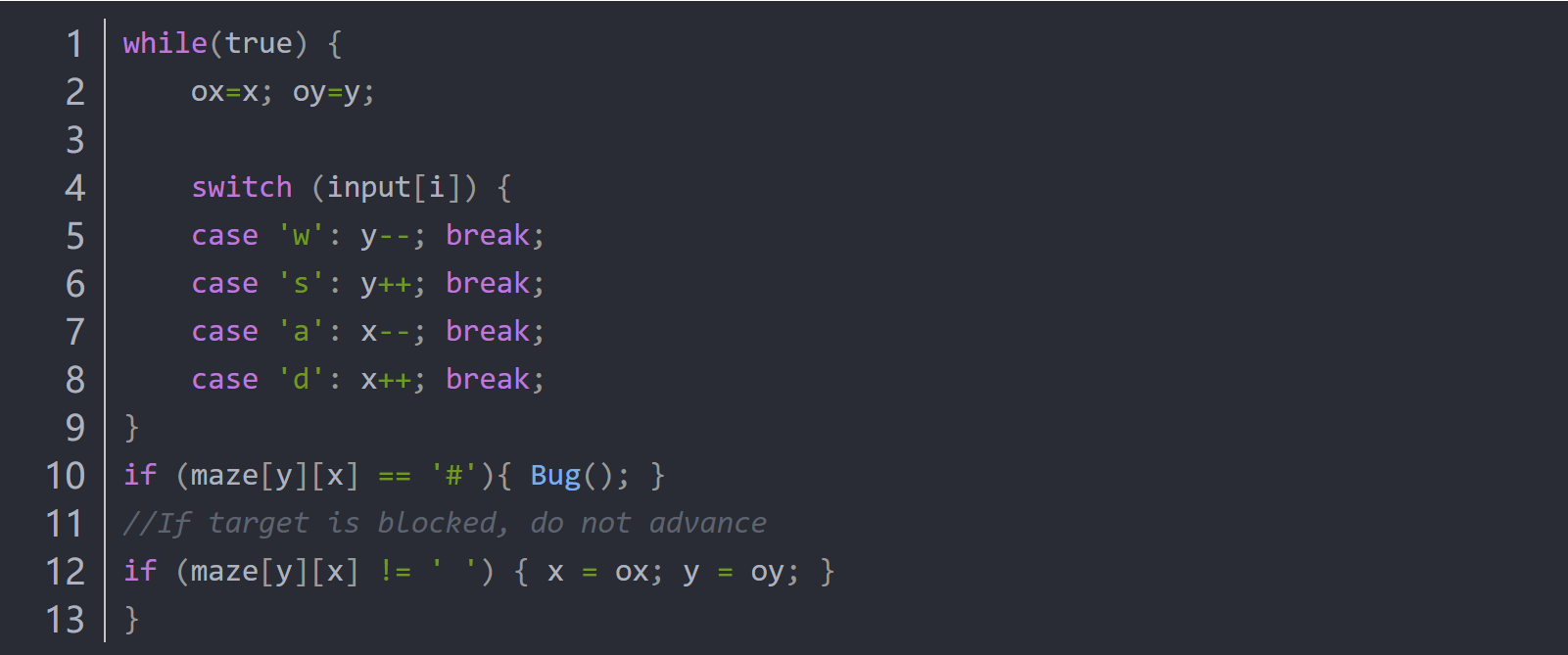
图2-Listing 1: A harder version of the maze game
Listing-1中的代码实现了一个迷宫游戏,玩家在四个方向上移动来探索迷宫,玩家可以退后并留在同一位置。这将在程序中创建大量不同的路径。同时,只有四个分支可以覆盖,因此仅依靠覆盖率并不足以说明一个行为是否有趣。在这个较难的版本中,x和y坐标是需要探索的相关状态,必须考虑x和y的组合才能发现解。由于迷宫很小(最多只能到达几百个不同的x,y对),因此分析人员可以指示fuzzer将任意新对作为新覆盖率(图3-a)。
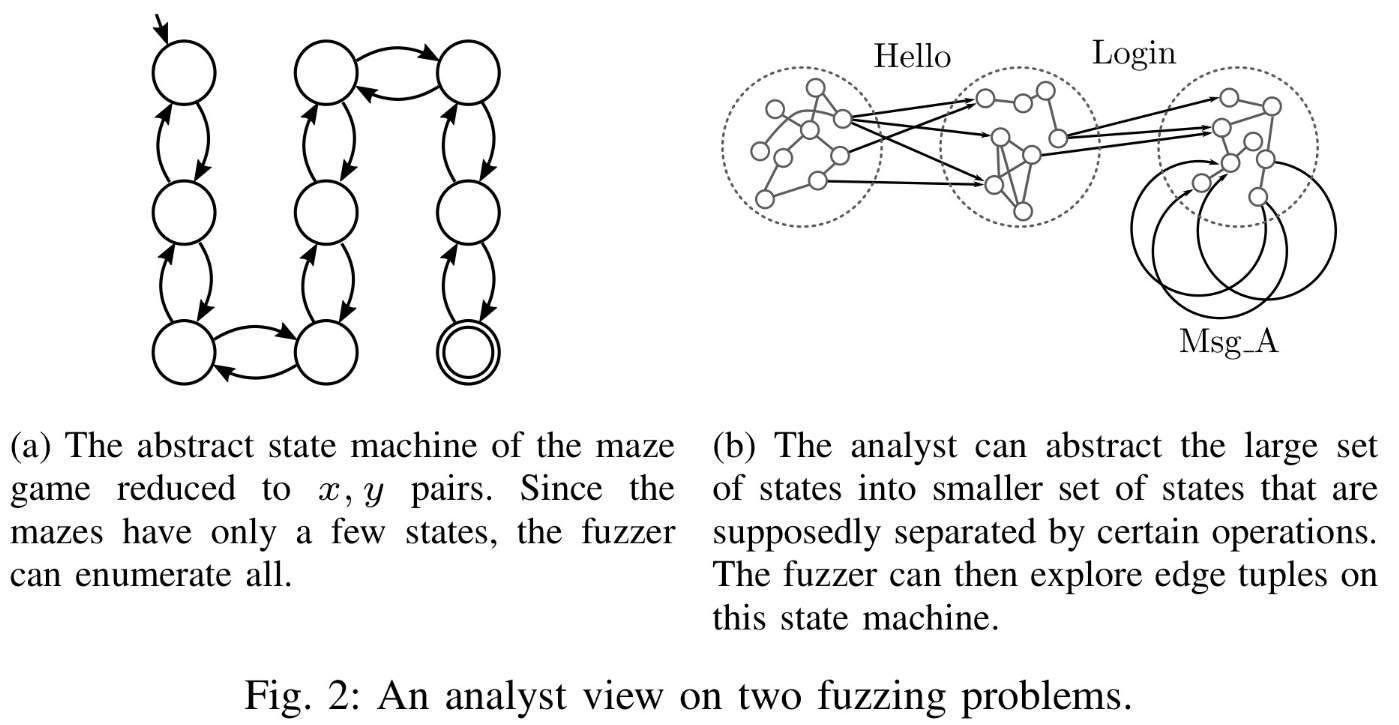
图3-: Fig. 2: An analyst view on two fuzzing problems
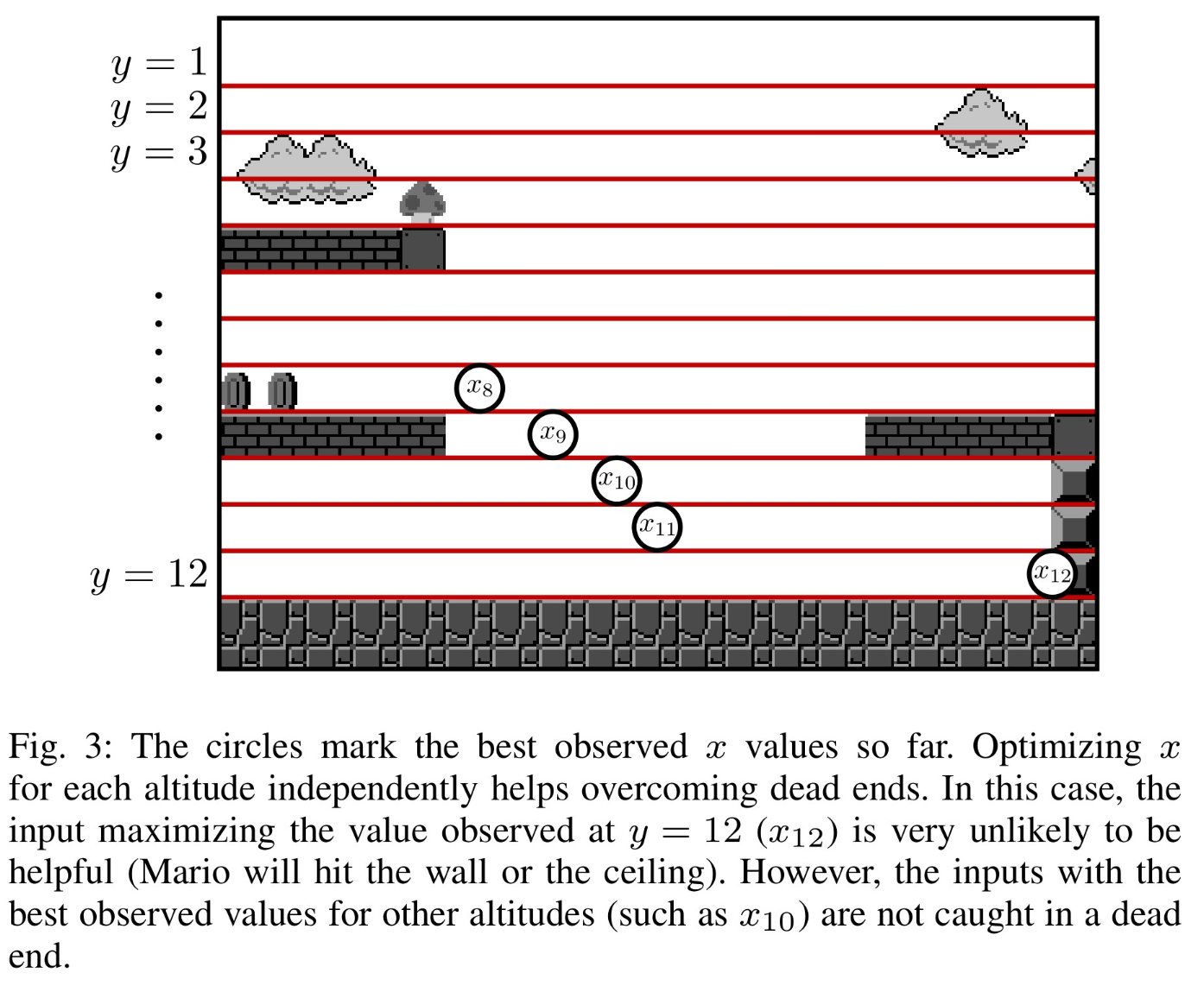
图4
这类情况在较大的状态空间也是同样的,例如游戏《超级马里奥兄弟》(图4)同样主要关心玩家的坐标。但是,玩家坐标的空间比迷宫游戏大得多。因此分析人员需要能够提供一个fuzzer可以实现的目标(如增加x坐标),而不是简单地探索所有不同的状态。这样,fuzzer就可以丢弃次等的中间结果。
(2)已知状态更改: 在某些情况下,用户可能不知道相关状态的哪些部分值得研究或者状态可能散布在整个应用程序中且难以识别。虽然状态可能是已知的,但是不能识别出足够小的子集以用于直接引导fuzzer。 分析人员可以标识预期会更改状态的代码部分。这种情况通常发生在使用高度结构化数据(例如消息序列或文件格式的块列表)的应用程序中。在这种情况下,用户可以创建一个包含消息日志或块类型的变量,而不是直接给出状态本身。此变量可以充当实际状态更改的代理,并且可以暴露给反馈函数(图3-b)。结果,fuzzer现在可以尝试探索这些状态变化的不同组合。在这种情况下,状态更改日志用作真实状态(无法轻易将其暴露给fuzzer)的抽象层。
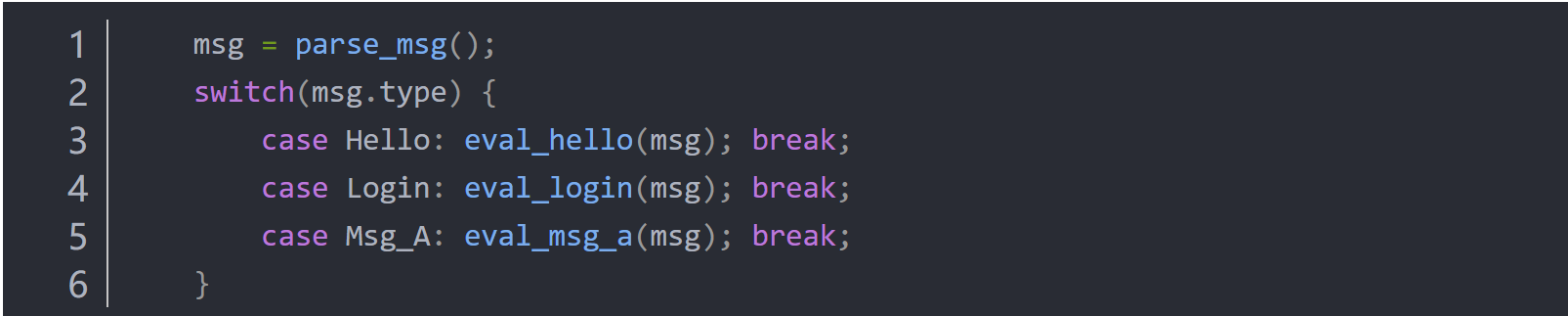
图5-Listing 2: A common problem in protocol fuzzing.
考虑listing-2中所示的调度程序代码,该代码基于许多常见的协议实现。AFL很难生成有趣的消息序列,因为fuzzer无法区分程序状态机中的不同状态。通过使用已成功处理的消息类型的日志,fuzzer能够更有效地探索由消息组合导致的不同状态。
(3)缺少中间状态: 例如magic byte校验,程序的覆盖率和值均未提供相关反馈,因此AFL型fuzzer无法解决它们。尤其在更复杂的情况下,如果输入和最终比较之间的关系变得更加复杂,那么即使concolic execution之类的技术也会失败。但是分析人员通常可以推断程序的行为方式,并且通常可以提供fuzzing进度的指示。通过将该指示符编码为额外的人为中间状态,分析人员可以引导fuzzer。
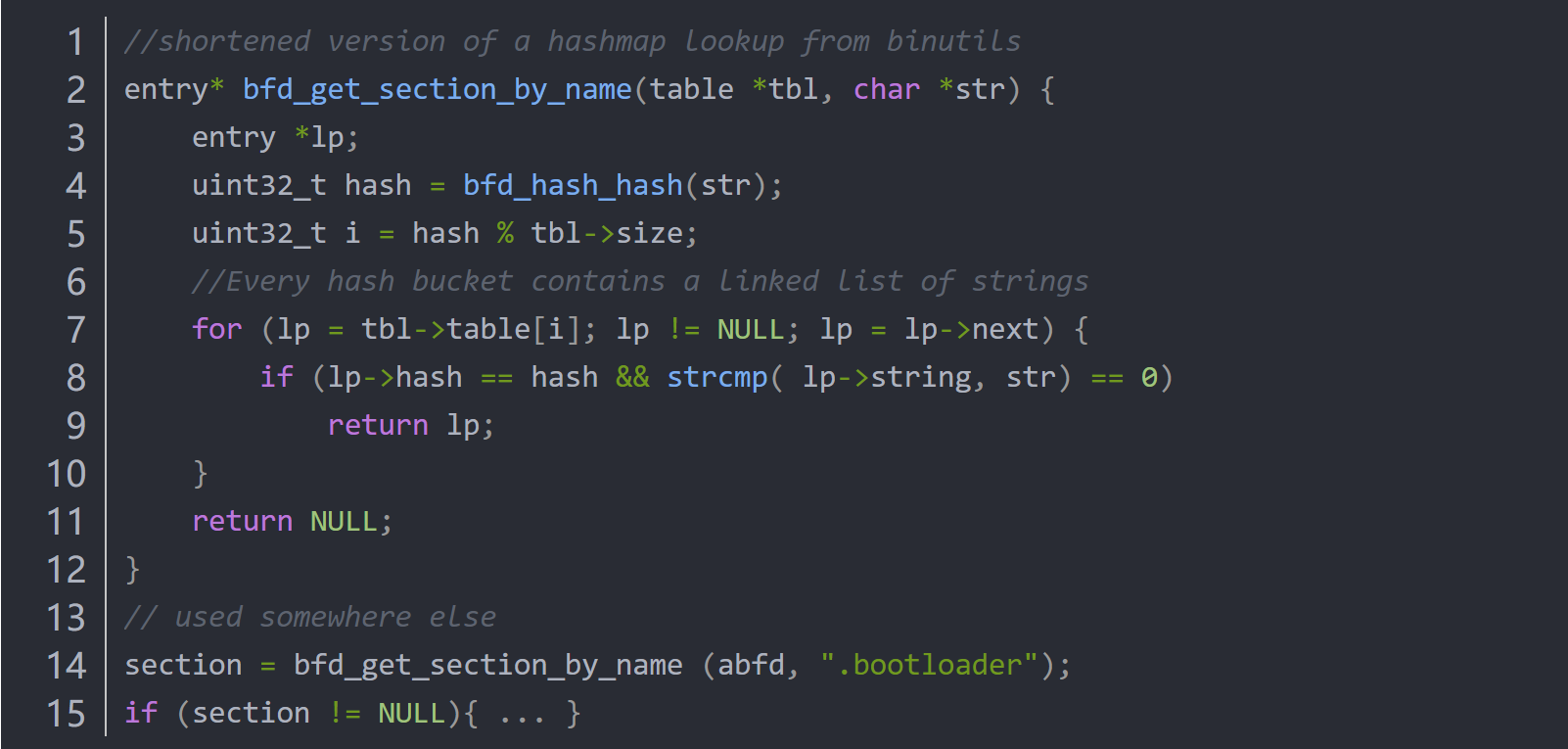
图6-Listing 3: A hash map lookup that is hard to solve (from binutils libbfd,
available at bfd/section.c).
如listing-3,该代码基于objdump二进制文件中的一个困难案例。该程序包含一个执行哈希表查找的功能和一个if条件,其中查找结果用于搜索给定的字符串。更具体地说,首先对密钥进行哈希处理,然后检查相应的存储桶。如果存储桶为空,则不会进行进一步处理。如果存储桶中包含一些值,则将它们进行单独比较。 这对基于concolic execution的工具和fuzzer都构成了重大挑战:解决此约束要求找到路径(即,计算散列所需的循环迭代次数)和所有相同的覆盖范围的hash值。即使找到了确切的路径,仍然依赖于哈希和实际的字符串匹配。fuzzer必须解决比较问题,同时保持输入的哈希值始终等于目标字符串的哈希值。concolic executor很难找到解决此约束的确切路径。 作者发现,在整个binutils代码库中,各种字符串都发生了500次以上的类似情况。在大多数情况下,散列表用输入中的值填充,并查找固定的字符串。分析人员可以认识到这有效地实现了一对多的字符串比较。借助这种观察认识,可以通过将这种复杂的约束转化为一系列简单的字符串比较(可以通过类似LAF-INTEL的反馈来解决)来指导fuzzer找到解决方案。
2.6.2 Feedback Mechanisms
Annotation(patch): 由于当前的fuzzer都无法让分析人员直接向fuzzer提供反馈,因此作者设计了一组注释,以使分析人员能够影响fuzzer的反馈函数,其目标是使分析人员可以通过这些注释为fuzzing过程提供high level的指导。
long-running fuzzing session & a second fuzzing session: 分析人员可以确定fuzzer无法取得进展的原因然后开始第二次模糊测试,其重点是使用自定义注释解决该障碍。当fuzzer解决路障时,long-running fuzzing会话会从临时会话中选择会产生新覆盖率的输入,并继续进行模糊测试,从而克服了困难的情况。
为了简化这样的工作流程,作者设计了四个可用于注释源代码的通用原语: (1)允许分析人员选择与解决当前问题相关的代码区域。
(2)允许直接访问AFL位图以存储其他值。bitmap的条目可以直接设置或增加,从而将状态值公开给反馈函数。
(3)分析师能够干预覆盖范围的计算:允许相同的边缘覆盖率导致不同的位图覆盖率,能在不同状态下创建更细粒度的反馈。
(4)引入了一个原语,允许用户添加hill climbing optimization。如果可能状态的空间太大而无法穷举探索,则用户可以为fuzzer提供一个工作目标。
2.6.3 IJON-Enable
IJON-ENABLE和IJON-DISABLE注释可用于启用和禁用覆盖率反馈。这样就可以有效地排除代码库的无用部分,指导fuzzer仅在满足某些条件的情况下探索代码。
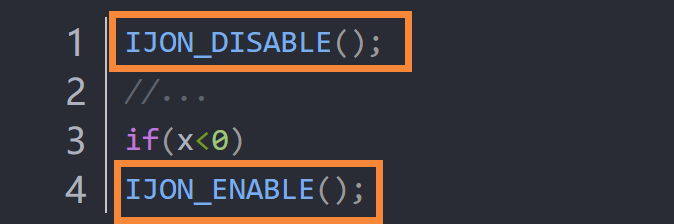
图7-Listing 4: Using the IJON-ENABLE annotation. The green highlight indicates
an added annotation.
例1.考虑Listing 4中的注释(框中部分)。在本例中,IJON-ENABLE将临时模糊会话限制为到达注释行且x为负值的输入。此注释允许模糊器集中精力解决难题,而不会浪费时间探索输入队列中的许多其他路径。
2.6.4 IJON-INC 和 IJON-SET
IJON-INC和IJON-SET注释可用于增加或设置位图中的特定条目。这允许将状态中的新值等同于新代码覆盖率。分析人员可以使用此注释将状态的各个方面选择性地暴露给fuzzer使其可以探索该变量的许多不同值。该注释增加了代码覆盖范围之外的反馈机制。使得新数据覆盖率也能使Fuzzer受到奖励。

图8-Listing 5: Using the IJON-INC annotation to expose the value x to the
feedback function.
例2.考虑listing-5中所示的注释。每次x更改时,位图中的新条目都会增加(基于当前文件名、当前行号和x值的哈希值计算位图中的索引,然后位图中的相应条目将递增)。
IJON-SET注释不设置条目的增量,而是直接设置位图值的最低有效位。这使得可以控制位图中的特定条目来引导模糊器。先前介绍的所有三种注释方法都使用此原语。
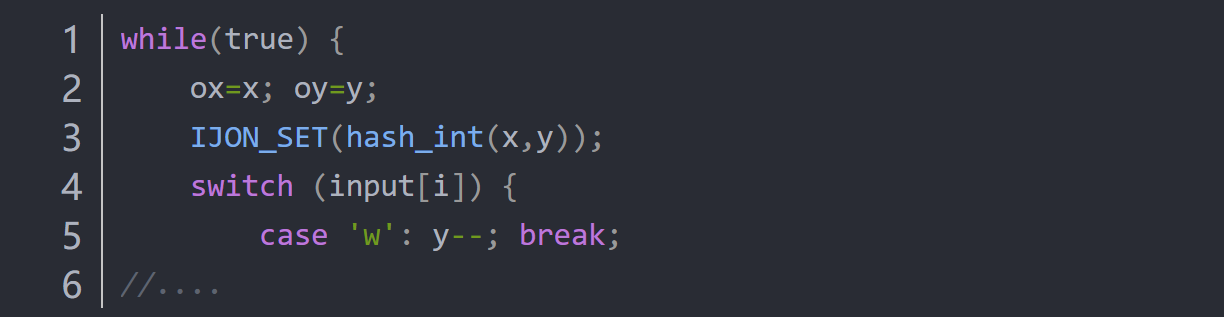
图9-Listing 6: Annotated version of the maze
例3.在迷宫游戏中添加了单行注释(listing-6),它使用x和y坐标的组合作为反馈。于是游戏中任何新访问的位置都被视为新的覆盖范围。使用IJON-SET而不是IJON-INC,因为我们不关心给定位置被访问的频率。相反,我们只对访问了一个新位置的事实感兴趣。
如果无法轻易观察到状态,则可以使用状态更改日志来记录,在其中注释已知会影响我们关心的状态的操作,并将状态更改日志用作反馈的索引。
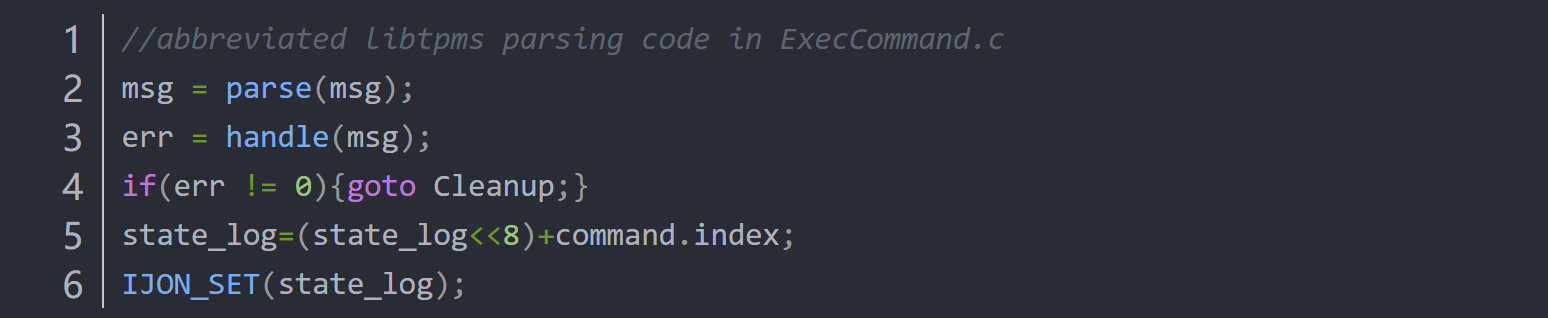
图10-Listing 7: Annotated version of libtpms.
例4.考虑listing-7中,在每次成功解析和处理了每条消息之后,将代表消息类型的命令索引附加到状态更改日志中。然后,设置一个由状态更改日志的哈希值寻址的位。每当看到多达四个成功处理的消息的新组合时,模糊器都将输入视为有趣的,从而在应用程序的状态空间中提供了更好的覆盖范围。
2.6.5 IJON-STATE
如果消息无法轻松联系起来,状态更改日志可能不足以探索不同的状态。为了产生更细粒度的反馈,可以探究状态和代码覆盖率的笛卡尔积。 为了实现这一点,作者提供了IJON-STATE,该原语能够更改边缘覆盖范围本身的计算。作者使用名为“虚拟状态”的第三个组件扩展了边缘元组。 在计算任何边缘的位图索引时,也会考虑此虚拟状态分量。只要虚拟状态发生变化,任何边缘都会触发新的覆盖范围。但是如果虚拟状态的数量增加太多,则fuzzer会被大量输入淹没,这实际上会减慢模的进度。

图11-Listing 8: Annotated version of the protocol fuzzing example (using IJONSTATE).
例5.考虑listing-8提供的示例,在没有注释的情况下,fuzzer可能难以探究各种消息的组合。通过将协议状态显式添加到fuzzer的虚拟状态,可以根据协议状态创建代码的多个虚拟副本。
因此,模糊器能够全面浏览协议状态机各种状态下的所有可能消息。 实际上,相同的边缘覆盖率现在可以导致不同的位图覆盖率,因此模糊器可以有效地探索被测程序的状态空间。 请注意,为防止状态爆炸,状态只有三个可能的值。 结果,一旦成功通过身份验证,模糊器就可以完全重新开发整个代码库。
2.6.6 IJON-MAX
前面的主要提供可用于增加所存储输入的多样性的反馈。但是在某些情况下,我们想针对特定目标进行优化或者状态空间太大而无法完全覆盖。在这种情况下,可能不关心一组不同的值,或者想要丢弃所有中间值。为了在这种情况下实现有效的fuzzing,作者提供了一个称为IJON-MAX的最大化原语。它有效地将fuzzing变成了基于爬坡的通用黑盒优化器。为了使多个值最大化,提供了多个(默认为512个)插槽来存储这些值。像coverage位图一样,每个值都独立最大化。使用此原语,也可以通过最大化-x来轻松构建x的最小化原语。

图12-Listing 9: Annotated version of the game Super Mario Bros
例9.以游戏《超级马里奥兄弟》为例,其中玩家在侧向滚动游戏中控制角色。在每个关卡中,目标是到达关卡的末端,同时避免诸如敌人,陷阱和陷阱之类的危险。如果角色被敌人碰触或掉进坑中,游戏结束。为了正确地探索游戏的状态空间,达到每个关卡的末尾很重要。如listing-9所示,可以通过要求fuzzer尝试最大化玩家的x坐标来完成关卡。鉴于这是一款横向滚动游戏,可以有效地指导fuzzer找到通过关卡成功完成游戏的方法。
2.7 程序实现
为了实现覆盖率反馈,AFL附带了一个用于clang的特殊编译器pass,用于检测每条分支指令。此外,AFL提供了一个包装器,可用来代替clang来编译目标。 该包装器自动注入自定义编译器pass。扩展了包装器和编译器通道。为了支持更改,引入了一个附加的运行时库,编译器将其静态链接。运行时实现了各种辅助功能和宏,可用于对目标应用程序进行注释。特别是,增加了对快速哈希函数的支持,该函数可用于生成分布更好的值或将字符串压缩为整数。 总之,使用了2.6中的原语,并添加了一些更高级的辅助函数。
1)IJON-ENABLE:为实现IJON-ENABLE,引入了一个适用于所有位图索引计算的掩码。如果掩码设置为零,则只能寻址和更新第一个位图条目。如果将其设置为0xffff,则使用原始行为。 这样,可以有效地禁用和启用覆盖范围跟踪。
2) IJON-INC and IJON-SET: 这两个注释都可以与位图直接交互,因此实现非常简单。 调用ijon_inc(n)后,位图中的第n项将增加。同样,调用ijon_set(n)会将第n条目的最低有效位设置为1。
如果在程序代码中的多个位置使用了这些功能,则必须非常小心,不要重用相同的位图索引。为了避免这种情况,引入了辅助宏IJON_INC(m)和IJON_SET(m)。 这两个宏都调用相应的函数,但根据m的哈希值以及宏调用的文件名和行号来计算位图索引n。 因此,避免在常用参数(例如0或1)上发生琐碎的冲突。
3)IJON-STATE:当调用IJON_STATE(n)时,更改了将基本块边缘映射到位图条目的方式。为此,更改边缘元组的定义,以包括源ID和目标ID(状态,ID,IDT)之外的状态。在此,“状态”是线程局部变量,用于存储与当前状态有关的信息。调用IJON_STATE(n)更新状态:=状态state n。这样,两个连续的调用会互相抵消
还修改了编译器pass,以使位图索引的计算如下:state⊕(ids * 2)⊕idt。 这样,每次状态变量更改时,每个边沿都会在位图中获得新索引。这些技术允许相同的代码在不同的上下文中执行时产生不同的覆盖范围。
4)IJON-MAX:扩展了模糊器,以保持额外的第二输入队列以实现最大化。 支持最多增加512个不同的变量。 这些变量中的每一个都称为插槽slot。模糊器仅存储为每个插槽产生最佳值的输入,并丢弃导致较小值的旧输入。为了存储最大的观察值,引入了一个附加的共享内存max-map,该映射由64位无符号整数组成。调用最大化原语IJON_MAX(slot,val)会更新maxmap [slot] = max(maxmap [slot],val)。
执行测试输入后,模糊器将检查共享位图和max-map是否有新覆盖。与共享覆盖位图和全局位图的设计类似(如2.5.2中所述),还实现了全局max-map,该图在整个模糊测试过程中都将持续存在,并补充了共享最大图。与位图相反,没有bucketing 应用于共享的max-map。 如果共享的max-map中的条目大于全局max-map中的对应条目,则认为该条目是新颖的。
由于现在有两个输入队列,因此还必须更新调度策略。 IJON要求用户提供使用原始队列(从代码覆盖率生成)或最大化队列(从最大化插槽生成)的概率。 使用此功能,用户可以决定哪个队列对选择模糊输入更为重视。 用户可以提供环境变量IJON_SCHEDULE_MAXMAP,其值为0到100。每次计划新的输入时,模糊器都会绘制一个介于100和100之间的随机数。如果随机数小于IJON_SCHEDULE_MAXMAP的值,则会进行通常的基于AFL的调度。否则,在max-map中选择一个随机的非零slot,并模糊测试对应于该slot的输入。如果在模糊其输入的同时更新了同一插槽,则旧输入将立即被丢弃,并且基于新近更新的输入,将继续进行模糊测试阶段。
5) Helper函数:IJON的运行库包含一组Helper函数,可以简化公共注释。例如,运行库包含帮助函数来散列不同类型的数据,例如字符串、内存缓冲区、活动函数堆栈或当前行号和文件名。此外,还有一些helper函数可用于计算两个值之间的差异。实现了不同的助手函数来简化注释过程,如下所述:
•IJON_CMP(x,y):计算x和y之间不同的位数。此辅助函数直接使用它来触摸位图中的单个字节。值得一提的是,出于实用目的,它并不直接使用不同位数作为位图的索引。考虑 Listing 5,如果在多个位置重复使用了相同的注释,则索引将发生冲突(两者共享0到64的范围)。相反,IJON_CMP将参数与当前文件名和行的哈希值组合在一起。因此,大大减少了碰撞的机会。
•IJON_HASH_INT(u32 old,u32 val):返回old和val的哈希。如第III-D节所述,使用哈希函数来创建更多不同的索引集并减少发生冲突的可能性。
•IJON_HASH_STR(u32 old,charSTR):返回两个参数的哈希值。例如,使用这个helper函数来创建文件名的散列。
• IJON_HASH_MEM(u32 old, u8 mem, size_t len): 返回旧字节和mem的第一个len字节的哈希值。
• IJON_HASH_STACK (u32 old): 活动函数的返回地址(称之为执行上下文)。 所有地址都单独进行哈希处理。将结果值异或在一起以产生最后结果。这样,递归调用也不会创建许多不同的价值。此辅助功能可用于根据哈希值创建反馈的虚拟副本执行上下文。
·IJON_STRDIST(char* a, char* b): 计算并返回a和b的公共前缀的长度。
为了传达中间覆盖率结果,基于AFL的模糊器使用包含以下内容的共享内存区域:共享位图,将区域替换为共享结构。该结构具有两个不同的字段。首先一个是原始的AFL共享位图。第二个是用于最大化原语的共享max-map。
2.8 实验评估
作者在五个最先进的fuzzer之上实现了IJON,展示了相同的注释如何根据各种不同的指标来超越作为baseline的fuzzer。作者针对多个不同的目标进行实验,以展示如何仅使用少量注释就能克服各种难题。
2.8.1 Setup
实验机器配置:Debian 4.9.65-3,Intel Xeon E5-2667(12核),2.9GHz,94GB RAM
作者将未修改的fuzzer与带有注释的fuzzer进行比较。IJON的用例是使任何fuzzer都可以运行,直到(基本)饱和,检查覆盖率,并使用手动注释对其进行改进。在一些实验中,作者选择了一些小例子,并假设只关心解决这个困难的方面。这模拟了使用IJON_ENABLE将fuzzing限制在感兴趣的区域。baseline fuzzer通常无法专注于单个区域,于是在该特定任务上的表现更差,因为它们还会探索目标应用程序的其他部分。
2.8.2 The Maze – Small, Known State Values
迷宫通常用于演示基于符号执行的测试用例生成的功能。公开发行的版本很简单,这是因为迷宫没有死角且只有正确的举动才能立即终止游戏。Out-of-the-box AFL和类似的fuzzer无法在合理的时间内解决这种迷宫,而KLEE可以在几秒钟内找到解决方案。该游戏的有效状态空间在采取的步骤数上是线性的,并且不会发生状态爆炸。
作者提升了游戏复杂度:玩家可以退后并停留在同一位置(通过走进墙壁)而不会死。结果,状态空间的步数呈指数增长,KLEE也无法解决迷宫问题。此外,作者创建了一个更大的迷宫。
(1)初始运行:作者对大型和小型迷宫都进行了实验。每个实验分别使用两种配置执行3次。在第一种配置中,使用原始的简单规则,任何错误的举动都会立即终止游戏。在第二种配置中,使用了困难的规则,游戏具有更大的状态空间。每个fuzzer都经过了未经修改的版本以及与IJON组合的测试。每个实验进行一小时。
(2)IJON:作者添加了一个简单的单行注释(listing-10),该注释使用x和y坐标的组合作为反馈。游戏中任何新访问的位置都被视为新的覆盖范围。
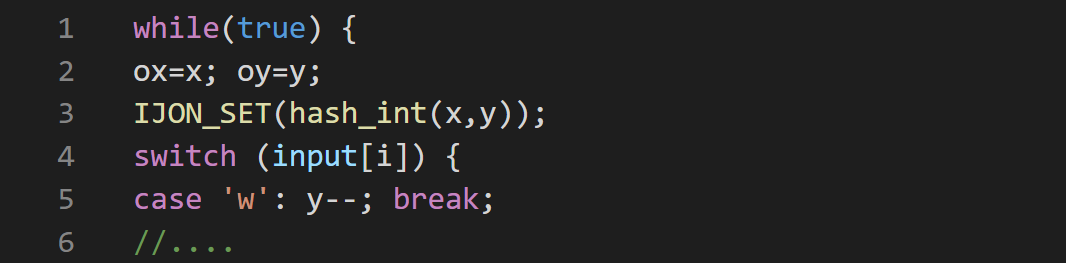
图13-Listing 10: Annotated version of the maze game.
如表I所示,没有一种原始工具能够解决迷宫的更复杂变体。但是,有了一个单行注解和IJON的支持,所有的fuzzer都可以解决所有迷宫变体。表II显示了不同的模糊器解决迷宫变化所花费的时间。

图14-表Ⅰ

图15-表Ⅱ
使用IJON注释,AFL在简易迷宫中的性能与KLEE相当。在更困难的版本上,带有IJON的AFL比在简单版本上的KLEE还要快而KLEE无法解决难题。此外,虽然没有IJON的AFL有时可以在简易模式下解决小迷宫,但结合IJON的AFL比没有IJON的AFL快20倍以上。最后,与baseline AFL相比,AFL的大多数扩展(例如LAF-INTEL,QSYM和ANGORA)实际上反而降低了性能。这是由于这些fuzzer提供的附加机制所致,在这种情况下,该机制产生了额外的成本,但没有提供任何价值。
2.8.3 Super Mario Bros. – Large Known State Values
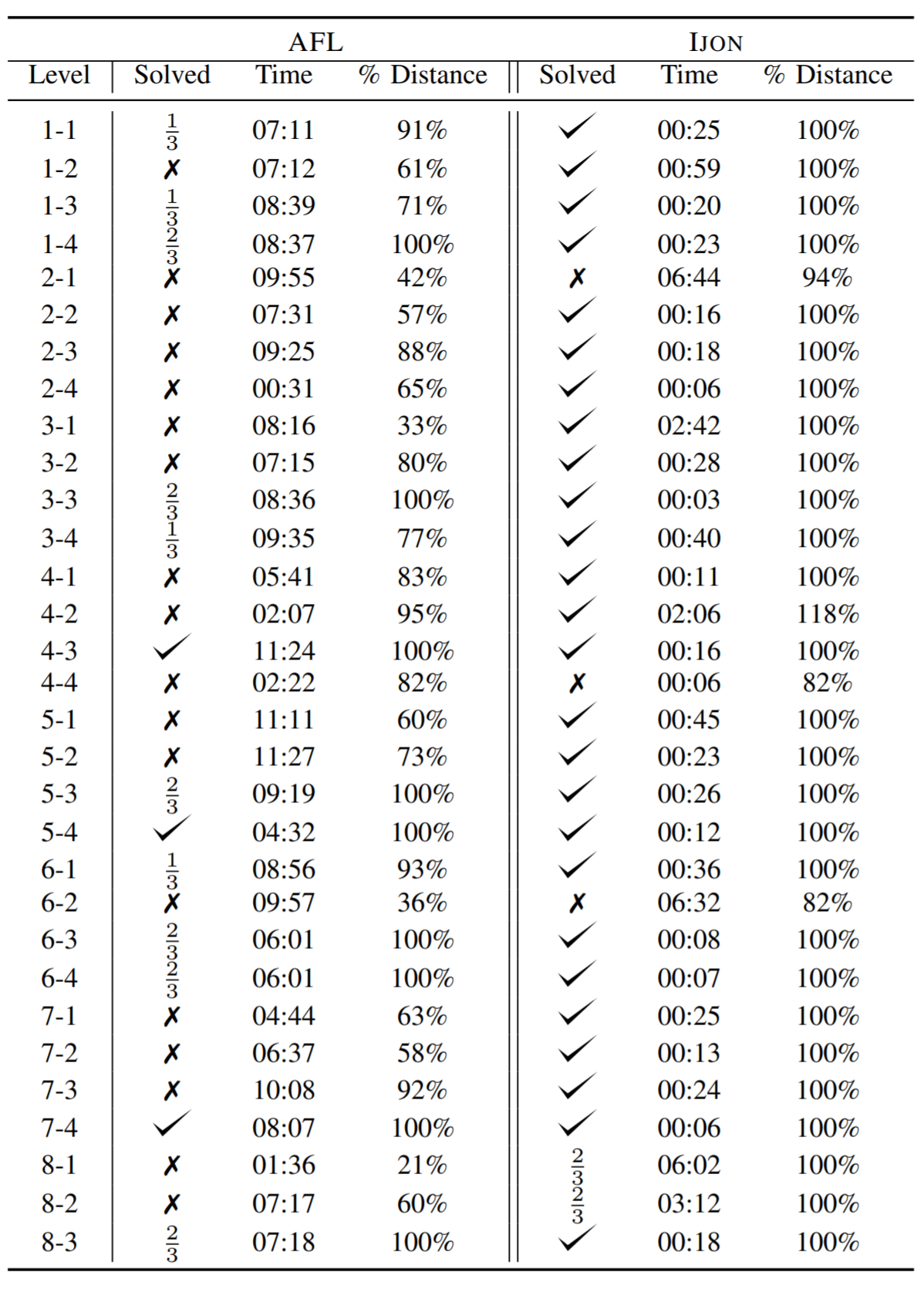
图16-表Ⅲ
作者通过从stdin读取所有键盘命令的方式,并对游戏进行了修改,使游戏角色Mario始终向右跑且停止移动时会被杀死。该修改是为了在较短的执行时间下产生结果。作者将AFL和AFL与IJON注释结合使用来玩游戏并观察游戏的进度。
在没有注释的情况下运行了AFL 12小时,并观察了Mario可以达到的不同关卡。作者添加了一个使用ijon_max原语的简单注释,并为每个可能的高度(以图块为单位)创建一个slot。在每个slot中,最大化玩家的x坐标。通过这一简单的单行注释(list-9),fuzzer可以在几分钟内解决几乎所有级别。实际上,使用IJON的AFL可以解决除3个级别之外的所有级别。应该注意的是,这些级别(级别6-2)中只有一个可以解决。它仍未解决是因为fuzzing固有的随机性。常规AFL表现很挣扎:花费更长的时间,解决的关卡少得多,而未解决的关卡的进度也更少。
2.8.4 Structured Input Formats – State Change Logging
为了演示使用状态更改日志记录探索结构化输入格式的能力,作者在三个示例中对带有IJON的AFL进行了评估。前两个摘自AFLSMART的评估,在他们的论文中提出多个案例研究,并对libpng和WavPack进行了详细的讨论。作者选择了两个示例,并添加了一个简单的state_change_log注释。
作者还提供了随机wav/png文件的前1024个字节作为种子,并使用了源代码中的字符串字典。通过这个简单的注释,能够发现两个目标中的错误,而AFL找不到任何错误。此外,作者在libpng中发现了另一个out-of-bounds read,在最新版本的libpng中仍然存在(但已报告)。这表明对于这些结构化的输入格式,发现这些安全问题实际上并不需要语法。在解析器代码中添加一个小的注释有时可以为分析人员提供完全相同的好处,而成本却要低得多。
为了进一步证实这一发现,作者选择了另一个示例来演示具有相同state_change_log注释的AFL如何探索比普通AFL更大的功能组合。 LIBTPMS是用于可信平台模块(TPM)安全协处理器的软件仿真器。它通常用于虚拟化解决方案中以创建虚拟化模块。 TPM指定了可用于与协处理器进行交互的协议。该协议由各种可能的消息组成,每个消息都有一个特定的解析器。在这个实验中作者并不关心解决单个约束,而是关注探索的不同消息序列的数量,所以只评估AFL和带有IJON的AFL。
a)初始运行:运行AFL 24小时,并绘制找到的路径的子集。为了可视化,我们还包含了一次运行中发现的所有消息的图表。每个节点都是已成功解析和处理的消息。如果成功地彼此处理消息A和消息B,则在节点A和B之间添加一条边。
b)IJON:添加了一个基于更改日志的注释,该注释存储了最近4个成功解析和处理的消息ID。然后使用这些ID来创建其他反馈。注释的代码显示在list-7中。使用此注释,又进行了24小时的运行。可以在表IV的“ IJON”列中找到发现的路径数。显然,IJON导致交互更加复杂。
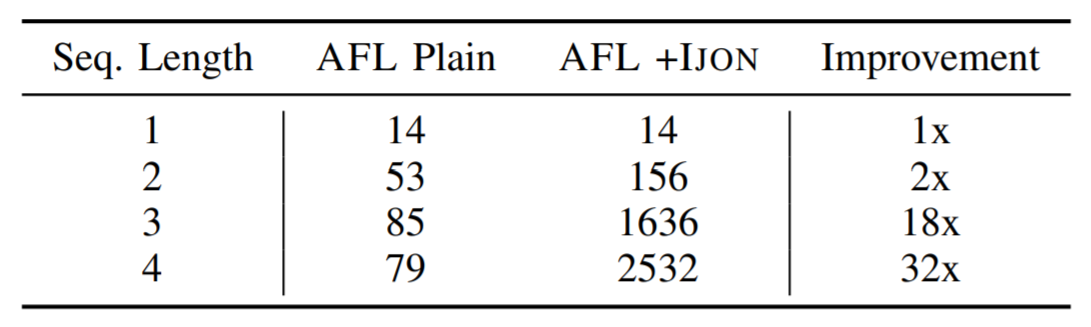
图17-表Ⅳ
从AFLSMART示例和TPM的实验中,可以看出,使用状态更改日志注释可以极大地提高探索不同消息链的能力,而这是当前技术无法涵盖的。尤其是,在libpng和WavPack上进行的实验表明,这个以前未开发的空间包含一些关键错误,之前的方法很难找到。
2.8.5 Binutils Hash map - Missing Intermediate States
作者从前面介绍的哈希图示例中提取了相关的代码(listing-3)。为了提供IJON注释,作者在哈希图中使用了可用的迭代函数。对于哈希图中的每个条目,执行一个IJON字符串比较。listing-11中可以看到修改后的结果。哈希映射查找是一对多的字符串比较,作者在查找函数中创建一个字符串比较操作的显式循环,然后尝试在所有比较中最大化匹配字节的最大数量。

图18-Listing 11: Annotated version of the hash map example.
作者使用带有和不带有IJON自定义注释的各种fuzzer进行了实验。结果显示在表V和表VI中。
a)初始运行:在初始运行期间,实验中的任何fuzzer都无法解决未修改形式的约束。
b)IJON:用一个小的注释扩展了目标(三行,如上所述)。应用此注释后,所有的fuzzer都可以在几分钟内解决约束,只有AFLFAST在三分之二的测试中失败了。但是其唯一成功的那次在6分钟内解决了约束。

图19-表Ⅴ
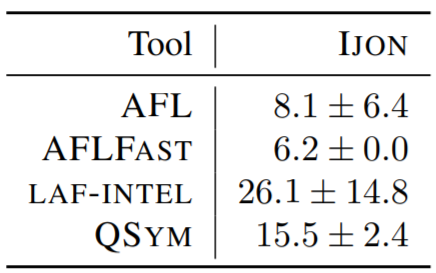
图20-表Ⅵ
2.8.6 Cyber Grand Challenge
为了进一步证实fuzzing目标有助于发现安全问题,作者在DARPA CGC数据集的Linux端口上进行了实验。作者选择了30个CGC目标的随机子集。对于其中的八个目标,即使用提供的PoV也不会导致崩溃。作者手动检查了剩下的22个挑战,并使用AFL和IJON进行了fuzz,设法在10个目标中产生了崩溃,结果显示在表VII中。
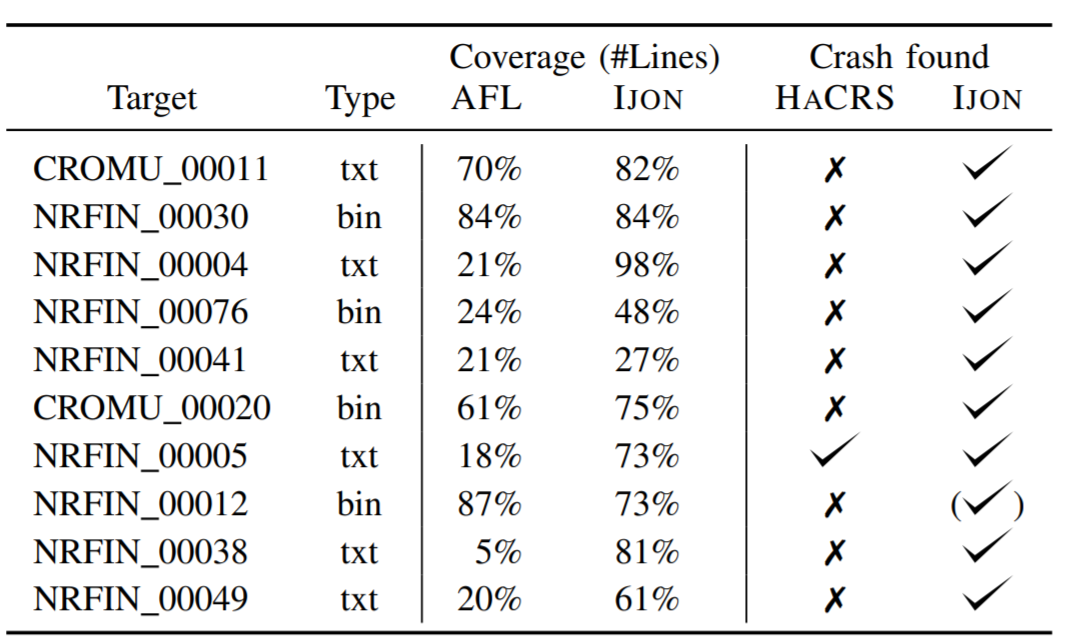
图21-表Ⅶ
由于多种原因,无法使剩余的12个目标崩溃:三个目标仅包含不会导致崩溃的信息泄漏漏洞,因此它们这项工作的范围之内。其中两个目标包含的崩溃过于复杂而无法发现(需要触发一系列不同的错误才能导致可观察到的崩溃)。尽管可以设计出触发这些崩溃的IJON注释,但作者认为如果没有对bug的事先了解难以做到这一点。因此将这两个目标视为失败。在其余的7个目标中,有2个在作者的覆盖跟踪程序中几乎所有输入崩溃,其中3个需要非常大的输入,而AFL无法有效生成这些输入,另外2个运行非常缓慢,或者导致除少数输入之外的所有输入都超时。
2.8.7 Real-World Software
除了在状态日志实验中发现的内存损坏以及在CGC数据集中发现的新颖崩溃之外,作者还对其他软件进行了实验,以进一步证明IJON对于发现安全性漏洞有帮助。 特别是,选择了dmg2im,这个工具最近被WEIZZ的作者fuzz过。作者为发现的漏洞应用了补丁,并继续使用IJON进行fuzz,结果在dmg2img中发现了另外三个内存损坏漏洞,其中两个是WEIZZ发现的错误的变体,需要满足其他约束条件才能实现的危险字符串操作函数的不安全使用。 第三个错误是整数溢出,导致大小为零的分配。 稍后,将偏移量减一的字节设置为零,从而破坏了malloc元数据,如listing-12所示。
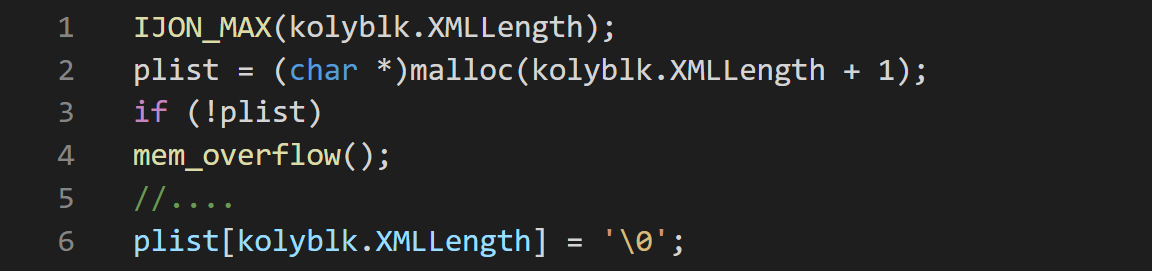
图22-Listing 12: Bug #3 in dmg2img
3 实验结论
在本文中,作者描述了一种和fuzzer的交互式方法。尽管这提供了指导fuzzing的新方法,但它需要手动检查测试范围、了解约束难以解决的原因并手动创建合适的注释。手动操作会给分析人员带来一定的成本,但该方法可以克服当前fuzzing的一些障碍。
当前在IJON中使用的注释是手动添加的,未来或许可以设计针对单个的困难约束条件自动推断添加注释的方法。一些现有的fuzzing方法使用了作者描述的注释的子集。例如,可以通过在比较中注释相等的字节数来表示LAF-INTEL。同样,ANGORA已经为所有覆盖范围实现了基于调用堆栈的虚拟状态。但是,所有这些工具都会不加选择地使用其他反馈。因此,它们仅限于低信息增益反馈机制。以类似的方式使用更精确的反馈将导致更大的队列并降低性能。最后,现在的注释需要有权限访问源码,作者认为未来是可以拓展到二进制文件中的。
实际上,分析人员通常习惯于手动选择解决覆盖率的种子文件或设计解决约束的自定义mutator(例如,通过提供字典或语法),又或者是尝试手动删除诸如校验和之类的困难约束。
作者实际上引入了“注释机制”来为分析人员提供与fuzzer更有效的交互方式,通过简单的几行注释就能解决现有fuzzer无法解决的困难问题。
4 总结体会
在寻找有码源的顶会论文时,不记得自己翻阅了多少篇,但是觉得都像天书一样完全不知在讲什么。当我看到介绍这篇论文《用 AFL 玩超级玛丽:通过Fuzzing探索程序空间状态以发现更多执行路径》的时候,终于感觉找到了,其实超级玛丽这四个字是我选择这篇论文来做作业的主要原因。我深知自己的基础知识和资质能力不足以支撑我复现一篇顶会论文,而且对网络攻防的兴趣也不足以支撑我在这段时间就有显著的进步。因为疫情的影响,上课的方式,作业的方式,考试的方式都受到了限制,在家里进行学习让我非常没有紧迫感,但是无论如何我都想认真的对待这次的作业。所以在选题上着重选了让自己感兴趣的文章,以期让自己更有动力。在阅读这篇论文的过程中,我学到了很多新的知识,也增强了看论文的能力,但是当我看到作者所使用的实验环境时,我懵了,我这台小笔记本好像不足以支撑他的实验。所以我把我的这次作业着重放在了理解论文上,我知道这样完成度会比较低,但是有多大力使多大力,完成所有在自己能力范围内的事,并开阔眼界,也是老师给我们留这项作业的一个原因吧。
5 参考资料
论文原文:https://www.syssec.ruhr-uni-bochum.de/media/emma/veroeffentlichungen/2020/02/27/IJON-Oakland20.pdf
https://cloud.tencent.com/developer/article/1594931
部分翻译:https://blog.csdn.net/m0_38110128/article/details/104651804
http://www.hackdig.com/03/hack-77659.htm