Git不仅是一款开源的分布式版本控制系统,而且有其独特的功能特性,例如大多数的分布式版本控制系统只会记录每次文件的变化,说白了就是只会关心文件的内容变化差异,而Git则是关注于文件数据整体的变化,直接会将文件提交时的数据保存成快照,而非仅记录差异内容,并且使用SHA-1加密算法保证数据的完整性。
使用Git服务程序
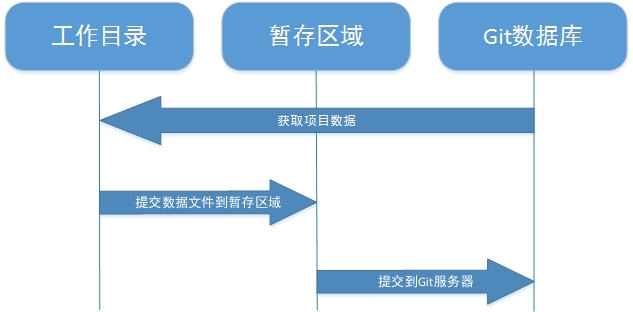
Git的三种重要模式,分别是已提交、已修改和已暂存:
已提交(committed):表示数据文件已经顺利提交到Git数据库中。
已修改(modified):表示数据文件已经被修改,但未被保存到Git数据库中。
已暂存(staged):表示数据文件已经被修改,并会在下次提交时提交到Git数据库中。
提交前的数据文件可能会被随意修改或丢失,但只要把文件快照顺利提交到Git数据库中,那就可以完全放心了,流程为:
1.在工作目录中修改数据文件。
2.将文件的快照放入暂存区域。
3.将暂存区域的文件快照提交到Git仓库中。
下面我们开始安装git服务程序。yum -y install git
首次安装Git服务程序后需要设置下用户名称、邮件信息和编辑器,这些信息会随着文件每次都提交到Git数据库中,用于记录提交者的信息,而Git服务程序的配置文档通常会有三份,针对当前用户和指定仓库的配置文件优先级最高:
| 配置文件 | 作用 |
| /etc/gitconfig | 保存着系统中每个用户及仓库通用配置信息。 |
| ~/.gitconfig ~/.config/git/config |
针对于当前用户的配置信息。 |
| 工作目录/.git/config | 针对于当前仓库数据的配置信息。 |
第一个要配置的是你个人的用户名称和电子邮件地址,这两条配置很重要,每次 Git 提交时都会引用这两条信息,记录是谁提交了文件,并且会随更新内容一起被永久纳入历史记录:
Git 提供了一个叫做 git config 的工具(译注:实际是 git-config 命令,只不过可以通过 git 加一个名字来呼叫此命令。),专门用来配置或读取相应的工作环境变量。而正是由这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方
/etc/gitconfig文件:系统中对所有用户都普遍适用的配置。若使用git config时用--system选项,读写的就是这个文件。~/.gitconfig文件:用户目录下的配置文件只适用于该用户。若使用git config时用--global选项,读写的就是这个文件。- 当前项目的 Git 目录中的配置文件(也就是工作目录中的
.git/config文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以.git/config里的配置会覆盖/etc/gitconfig中的同名变量。
在 Windows 系统上,Git 会找寻用户主目录下的 .gitconfig 文件。主目录即 $HOME 变量指定的目录,一般都是 C:Documents and Settings$USER。此外,Git 还会尝试找寻 /etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
用户信息
第一个要配置的是你个人的用户名称和电子邮件地址,这两条配置很重要,每次 Git 提交时都会引用这两条信息,记录是谁提交了文件,并且会随更新内容一起被永久纳入历史记录:

如果用了 --lobal 选项,那么更改的配置文件就是位于你用户主目录下的那个,以后你所有的项目都会默认使用这里配置的用户信息。如果要在某个特定的项目中使用其他名字或者电邮,只要去掉 --global选项重新配置即可,新的设定保存在当前项目的 .git/config 文件里。
文本编辑器
接下来要设置的是默认使用的文本编辑器。Git 需要你输入一些额外消息的时候,会自动调用一个外部文本编辑器给你用。默认会使用操作系统指定的默认编辑器,一般可能会是 Vi 或者 Vim。如果你有其他偏好,比如 Emacs 的话,可以重新设置:

差异分析工具
还有一个比较常用的是,在解决合并冲突时使用哪种差异分析工具。比如要改用 vimdiff 的话:

查看配置信息
要检查已有的配置信息,可以使用 git config --list 命令:

-----------------------------------------------------------------------------------------------------------------------
提交数据
接下来我们进行提交数据
我们可以简单的把工作目录理解成是一个被Git服务程序管理的目录,Git会时刻的追踪目录内文件的改动,另外在安装好了Git服务程序后,默认就会创建好了一个叫做master的分支,我们直接可以提交数据到主线了。
创建本地的工作目录:

然后用git init将该目录初始化转成Git的工作目录:

Git只能追踪类似于txt文件、网页、程序源码等文本文件的内容变化,而不能判断图片、视频、可执行命令等这些二进制文件的内容变化,所以先来尝试往里面写入一个新文件吧。

将该文件添加到暂存区:

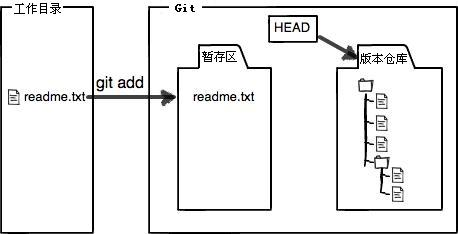
添加到暂存区后再次修改文件的内容:

将暂存区的文件提交到Git版本仓库,命令格式为“git commit -m "提交说明”:

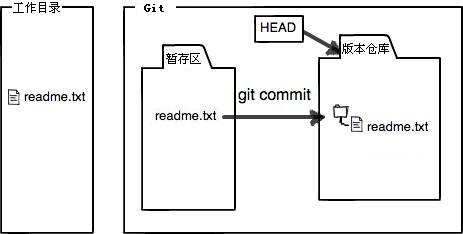
查看当前工作目录的状态(咦,为什么文件还是提示被修改了?):
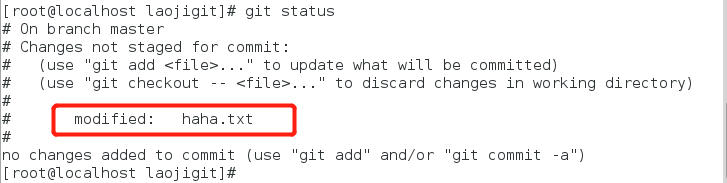
因为提交操作只是将文件在暂存区中的快照版本提交到Git版本数据库,所以当你将文件添加到暂存区后,如果又对文件做了修改,请一定要再将文件添加到暂存区后提交到Git版本数据库:
第一次修改 -> git add -> 第二次修改 -> git add -> git commit
查看当前文件内容与Git版本数据库中的差别:

那么现在把文件提交到Git版本数据库吧:

再来查看下当前Git版本仓库的状态:

有些时候工作目录内的文件会比较多,懒的把文件一个个提交到暂存区,可以先设置下要忽略上传的文件(写入到"工作目录/.gitignore"文件中),然后使用"git add ."命令来将当前工作目录内的所有文件都一起添加到暂存区域。
//忽略所有以.a为后缀的文件。
*.a
//但是lib.a这个文件除外,依然会被提交。
!lib.a
//忽略build目录内的所有文件。
build/
//忽略build目录内以txt为后缀的文件。
build/*.txt
//指定忽略名字为git.c的文件。
git.c
先在工作目录中创建一个名字为git.c的文件:

然后创建忽略文件列表:


添加将当前工作目录中的所有文件快照上传到暂存区:

经过刚刚的实验,大家一定发现“添加到暂存区”真是个很麻烦的步骤,虽然使用暂存区的方式可以让提交文件更加的准确,但有时却略显繁琐,如果对要提交的文件完全有把握,我们完全可以追加-a参数,这样Git会将以前所有追踪过的文件添加到暂存区后自动的提交,从而跳过了上传暂存区的步骤,再来修改下文件:

文件被直接提交到Git数据库:

比如想把git.c也提交上去,便可以这样强制添加文件:

然后重新提交一次(即修改上次的提交操作):

移除数据
有些时候会想把已经添加到暂存区的文件移除,但仍然希望文件在工作目录中不丢失,换句话说,就是把文件从追踪清单中删除。
先添加一个新文件,并上传到暂存区:

查看当前的Git状态:
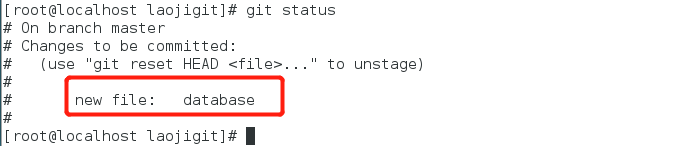
将该文件从Git暂存区域的追踪列表中移除(并不会删除当前工作目录内的数据文件):

此时文件已经是未追踪状态了:

而如果我们想将文件数据从Git暂存区和工作目录中一起删除,可以这样操作:
再将database文件提交到Git暂存区:

使用git rm命令可以直接删除暂存区内的追踪信息及工作目录内的数据文件:
但如果在删除之前数据文件已经被放入到暂存区域的话,Git会担心你勿删未提交的文件而提示报错信息,此时可追加强制删除-f参数。

查看当前Git的状态:

移动数据
Git不像其他版本控制系统那样跟踪文件的移动操作,如果要修改文件名称,则需要使用git mv命令:

发现下次提交时会有一个改名操作:
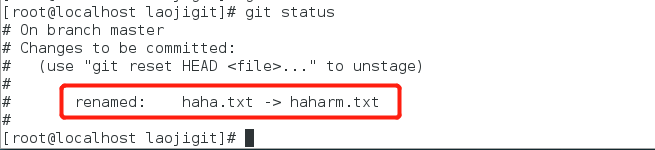
提交文件到Git版本仓库:

其实我们还可以这样来修改文件名,首先将工作目录下的数据文件改名:

然后删除Git版本仓库内的文件快照:

最后再将新的文件添加进入:

历史记录
在完成上面的实验后,我们已经不知不觉有了很多次的提交操作了,可以用git log命令来查看提交历史记录:
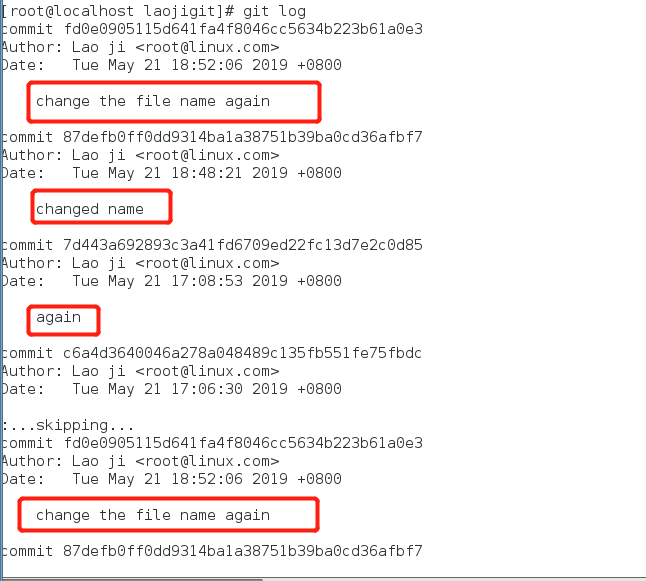
像上面直接执行git log命令后会看到所有的更新记录(按时间排序,最近更新的会在上面),历史记录会除了保存文件快照,还会详细的记录着文件SHA-1校验和,作者的姓名,邮箱及更新时间,如果只想看最近几条记录,可以直接这样操作:
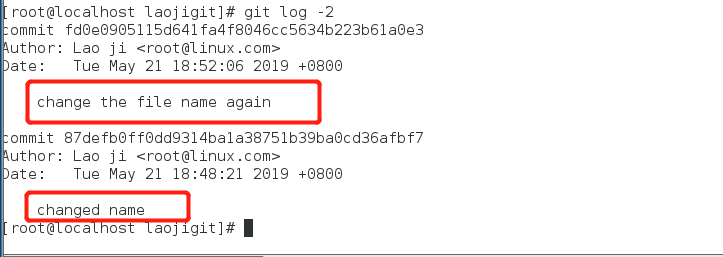
我也常用-p参数来展开显示每次提交的内容差异,例如仅查看最近一次的差异:
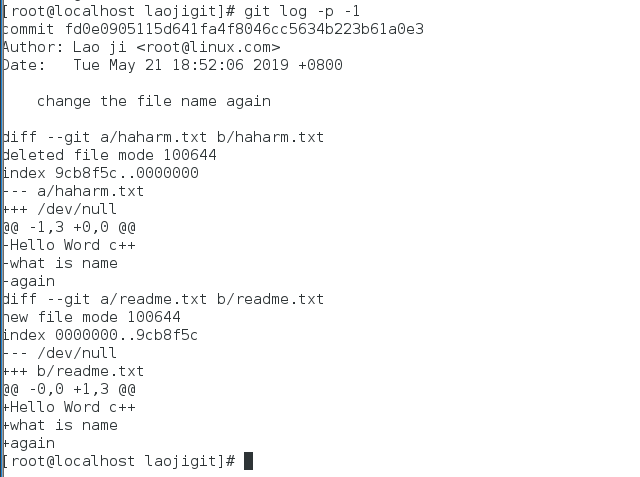
我们还可以使用--stat参数来简要的显示数据增改行数,这样就能够看到提交中修改过的内容、对文件添加或移除的行数,并在最后列出所有增减行的概要信息(仅看最近两次的提交历史):
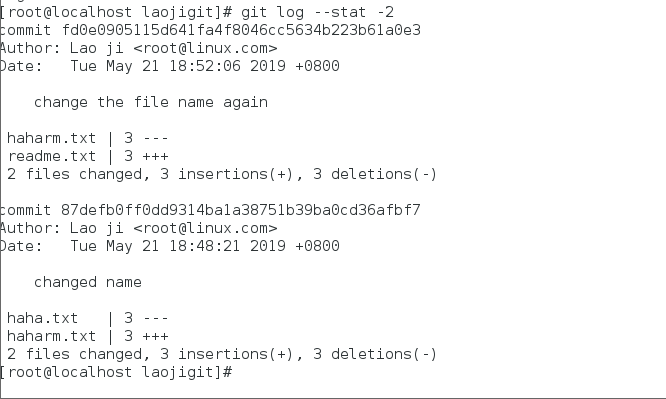
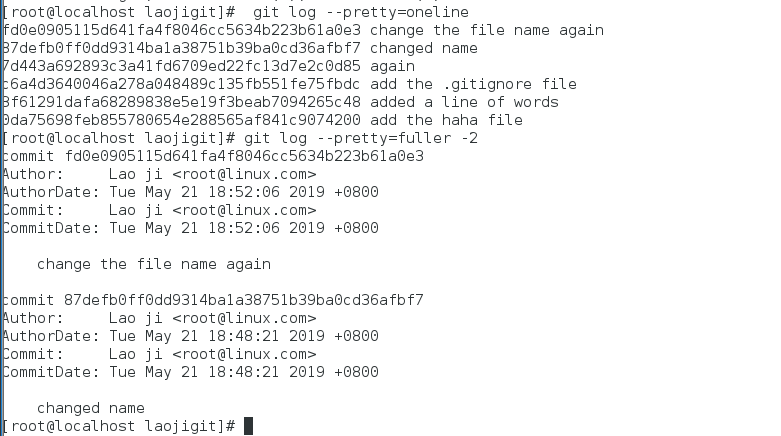
还有一个超级常用的--pretty参数,它可以根据不同的格式为我们展示提交的历史信息,比如每行显示一条提交记录:

以更详细的模式输出最近两次的历史记录:
还可以使用format参数来指定具体的输出格式,这样非常便于后期编程的提取分析,常用的格式有:
| %s | 提交说明。 |
| %cd | 提交日期。 |
| %an | 作者的名字。 |
| %cn | 提交者的姓名。 |
| %ce | 提交者的电子邮件。 |
| %H | 提交对象的完整SHA-1哈希字串。 |
| %h | 提交对象的简短SHA-1哈希字串。 |
| %T | 树对象的完整SHA-1哈希字串。 |
| %t | 树对象的简短SHA-1哈希字串。 |
| %P | 父对象的完整SHA-1哈希字串。 |
| %p | 父对象的简短SHA-1哈希字串。 |
| %ad | 作者的修订时间。 |
另外作者和提交者是不同的,作者才是对文件作出实际修改的人,而提交者只是最后将此文件提交到Git版本数据库的人。
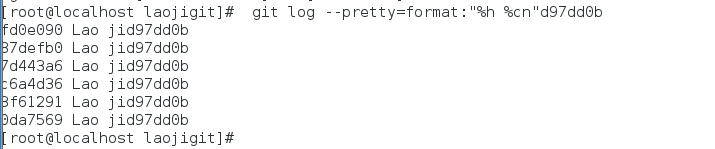
查看当前所有提交记录的简短SHA-1哈希字串与提交者的姓名:
还原数据
还原数据是每一个版本控制的基本功能,先来随意修改下文件吧:

然后将文件提交到Git版本数据库:

此时觉得写的不妥,想要还原某一次提交的文件快照:

Git服务程序中有一个叫做HEAD的版本指针,当用户申请还原数据时,其实就是将HEAD指针指向到某个特定的提交版本而已,但是因为Git是分布式版本控制系统,所以不可能像SVN那样使用1、2、3、4来定义每个历史的提交版本号,为了避免历史记录冲突,故使用了SHA-1计算出十六进制的哈希字串来区分每个提交版本,像刚刚最上面最新的提交版本号就是2377979c14c74ed8f430c04fa667882bfe8906c8,另外默认的HEAD版本指针会指向到最近的一次提交版本记录哦,而上一个提交版本会叫HEAD^,上上一个版本则会叫做HEAD^^,当然一般会用HEAD~5来表示往上数第五个提交版本哦~。
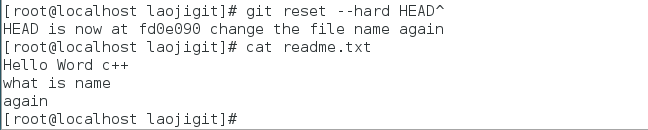
好啦,既然我们已经锁定了要还原的历史提交版本,就可以使用git reset命令来还原数据了:

再来看下文件的内容吧(怎么样,内容果然已经还原了吧~):
刚刚的操作实际上就是改变了一下HEAD版本指针的位置,说白了就是你将HEAD指针放在那里,那么你的当前工作版本就会定位在那里,要想把内容再还原到最新提交的版本,先查看下提交版本号吧:
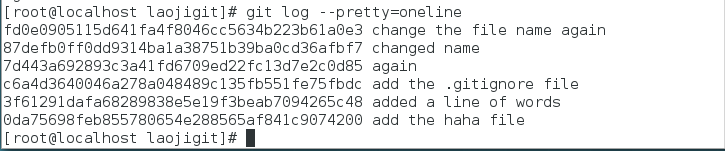
怎么搞得?竟然没有了Introduction software这个提交版本记录??
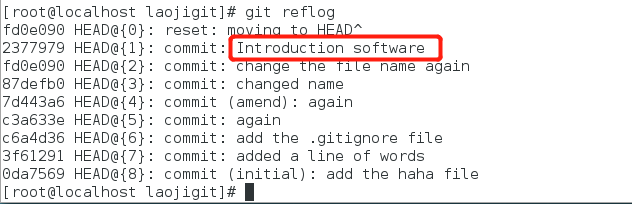
原因很简单,因为我们当前的工作版本是历史的一个提交点,这个历史提交点还没有发生过Introduction software更新记录,所以当然就看不到了,要是想“还原到未来”的历史更新点,可以用git reflog命令来查看所有的历史记录:
找到历史还原点的SHA-1值后,就可以还原文件了,另外SHA-1值没有必要写全,Git会自动去匹配:x


如是只是想把某个文件内容还原,就不必这么麻烦,直接用git checkout命令就可以的,先随便写入一段话:

我们突然发现不应该写一句话的,可以手工删除(当内容比较多的时候会很麻烦),还可以将文件内容从暂存区中恢复:

checkou规则是如果暂存区中有该文件,则直接从暂存区恢复,如果暂存区没有该文件,则将还原成最近一次文件提交时的快照。
管理标签
当版本仓库内的数据有个大的改善或者功能更新,我们经常会打一个类似于软件版本号的标签,这样通过标签就可以将版本库中的某个历史版本给记录下来,方便我们随时将特定历史时期的数据取出来用,另外打标签其实只是向某个历史版本做了一个指针,所以一般都是瞬间完成的,感觉很方便吧。
在Git中打标签非常简单,给最近一次提交的记录打个标签:

查看所有的已有标签:

查看此标签的详细信息:
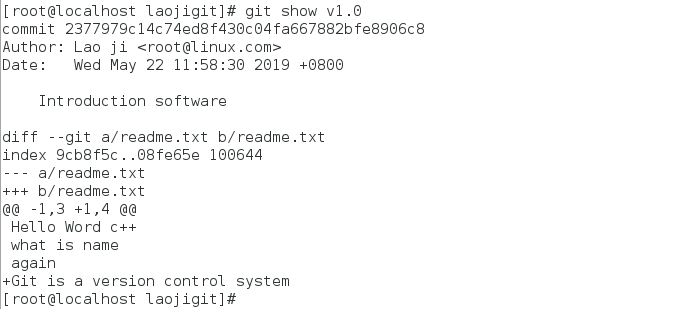
还可以创建带有说明的标签,用-a指定标签名,-m指定说明文字:

我们为同一个提交版本设置了两次标签,来把之前的标签删除吧:

管理分支结构
分支即是平行空间,假设你在为某个手机系统研发拍照功能,代码已经完成了80%,但如果将这不完整的代码直接提交到git仓库中,又有可能影响到其他人的工作,此时我们便可以在该软件的项目之上创建一个名叫“拍照功能”的分支,这种分支只会属于你自己,而其他人看不到,等代码编写完成后再与原来的项目主分支合并下即可,这样即能保证代码不丢失,又不影响其他人的工作。
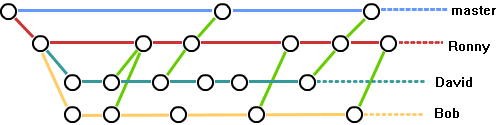
一般在实际的项目开发中,我们要尽量保证master分支是非常稳定的,仅用于发布新版本,平时不要随便直接修改里面的数据文件,而工作的时候则可以新建不同的工作分支,等到工作完成后在合并到master分支上面,所以团队的合作分支看起来会像上面图那样。
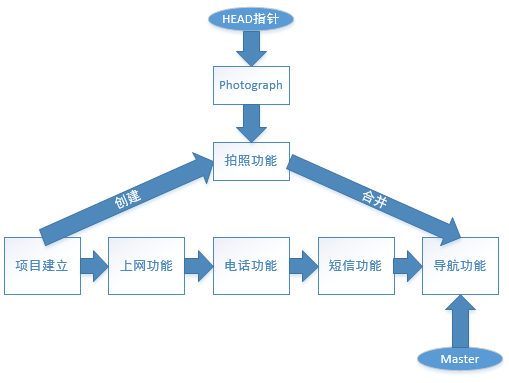
另外如前面所讲,git会将每次的提交操作串成一个时间线,而在前面的实验中实际都是在对master分支进行操作,Git会在创建分支后默认创建一个叫做Photograph的指针,所以我们还需要再将HEAD指针切换到“Photograph”的位置才正式使用上了新分支哦,这么说起来可能比较抽象,赶紧学习下面的实验吧。
创建分支
首先创建分支:

切换至分支:

查看当前分支的情况(会列出该仓库中所有的分支,当前的分支前有*号)

我们对文件再追加一行字符串吧:

将文件提交到git仓库:

为了让大家更好理解分支的作用,我们在提交文件后再切换回master分支:

然后查看下文件内容,发现并没有新追加的字符串哦:

合并分支
现在,我们想把laojigit的工作成果合并到master分支上了,则可以使用"git merge"命令来将指定的的分支与当前分支合并:
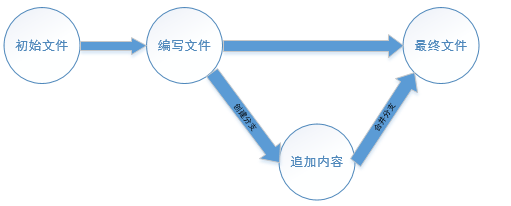

查看合并后的readme.txt文件:

确认合并完成后,就可以放心地删除laojigit分支了:

删除后,查看branch,就只剩下master分支了:(那个laoji开始就有,自动忽略)

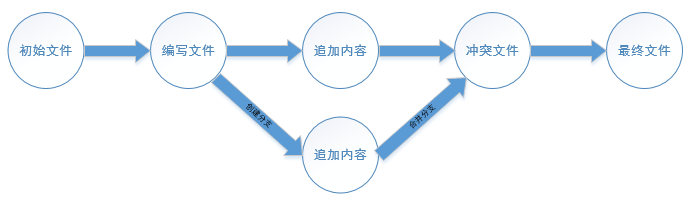
内容冲突
但是Git并不能每次都为我们自动的合并分支,当遇到了内容冲突比较复杂的情况,则必须手工将差异内容处理掉,比如这样的情况:
创建分支并切换到该分支命令:git checkout -b 分支名称
创建一个新分支并切换到该分支命令:

修改readme.txt文件内容:
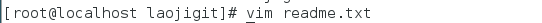
在laojigit分支上提交:

切换到master分支:

在master分支上修改readme.txt文件同一行的内容:


提交至Git版本仓库:

那么此时,我们在master与laojigit分支上都分别对中readme.txt文件进行了修改并提交了,那这种情况下Git就没法再为我们自动的快速合并了,它只能告诉我们readme.txt文件的内容有冲突,需要手工处理冲突的内容后才能继续合并:
冲突的内容为:


Git用< <<<<<<,=======,>>>>>>>分割开了各个分支冲突的内容,我们需要手工的删除这些符号,并将内容修改为:
Hello Word c++
what is name
again
Git is a version control system
wahhaha a wa hahaha and simple
解决冲突内容后则可顺利的提交:

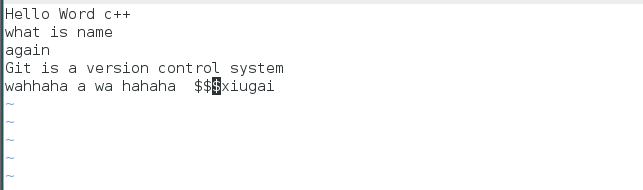
查看Git历史提交记录(可以看到分支的变化):
最后,放心的删除laojigit分支吧:

-----------------------------------------------------------------------------------------------------------------------------------------------------
部署Git服务器
Git是分布式的版本控制系统,我们只要有了一个原始Git版本仓库,就可以让其他主机克隆走这个原始版本仓库,从而使得一个Git版本仓库可以被同时分布到不同的主机之上,并且每台主机的版本库都是一样的,没有主次之分,极大的保证了数据安全性,并使得用户能够自主选择向那个Git服务器推送文件了,其实部署一个git服务器是非常简单的事情,我们需要用到两台主机,分别是:
| 主机名称 | 操作系统 | IP地址 |
| Git服务器 | 红帽RHEL7操作系统 | 192.168.10.10 |
| Git客户端 | 红帽RHEL7操作系统 | 192.168.10.20 |
首先我们分别在Git服务器和客户机中安装Git服务程序(刚刚实验安装过就不用安装了):
然后创建Git版本仓库,一般规范的方式要以.git为后缀:

修改Git版本仓库的所有者与所有组:

初始化Git版本仓库:

其实此时你的Git服务器就已经部署好了,但用户还不能向你推送数据,也不能克隆你的Git版本仓库,因为我们要在服务器上开放至少一种支持Git的协议,比如HTTP/HTTPS/SSH等,现在用的最多的就是HTTPS和SSH,我们切换至Git客户机来生成SSH密钥:
将客户机的公钥传递给Git服务器:
此时就已经可以从Git服务器中克隆版本仓库了(此时目录内没有文件是正常的):