接着前天的豆瓣书单信息爬取,这一篇文章看一下利用pandas完成对数据的存储。
回想一下我们当时在最后得到了六个列表:img_urls, titles, ratings, authors, details。
我们如何对这些数据进行存储:让每一本书的每一个元素可以一一对应起来,形成第一本书的书名、作者等等在一起,下一本书的书名、作者在一起。
这里我们接触一个新的数据存储形式:pandas库里的DataFrame。
pandas.DataFrame()
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。跟其他类似的数据结构相比(如R的data.frame),DataFrame中面向行和面向列的操作基本上是平衡的。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
- 简单来说,它类似于excel,是一种二维表。
- 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据);而DataFrame的单元格可以存放数值、字符串等,这和excel表很像。
- 同时DataFrame也可以设置列名columns与行名index。可以通过像matlab一样通过位置获取数据,也可以通过列名和行名定位,具体方法等我学到那里了再说哈哈哈。
看下列代码↓
1 import pandas as pd 2 result = pd.DataFrame() 3 authors=['file','edit','format','run','options'] 4 numbers=[1,2,3,4,5] 5 result['authors']=authors 6 result['numbers']=numbers
我们得到的 result,这个DataFrame对象会长这个样子:
>>> result
authors numbers
0 file 1
1 edit 2
2 format 3
3 run 4
4 options 5
它看上去是不是真的很像 excel !
而且如果如果两列数据量不同,比如上面的authors有5个值,而numbers却有6个值就会报错Length of values does not match length of index。
用DataFrame对数据进行.csv存储
进入正题,看看我们如何对爬虫的数据进行存储:
1 import pandas as pd 2 result = pd.DataFrame() 3 result['img_urls'] = img_urls 4 result['titles'] = titles 5 result['ratings'] = ratings 6 result['authors'] = authors 7 result['details'] = details 8 result.to_csv('result.csv',index=None)
- 第二行创建数据框,起名为 result 。
- 第三行~第七行,给数据框添加列(同时给列起名为img_urls, titles 等等)。
- 因为五个列表的元素数量必然是相等的,它们的DataFrame不会报错,同时实现了同一行的内容既是一本书的信息。
- 看一下这里的 result 长什么样↓(这里我为了看得更直观,把 img_urls 和 details 的 result 注释掉了)
>>> result titles ratings authors 0 白日漫游 8.2 远子/广西师范大学出版社/2019-5 1 不识字的人 9.1 [匈]雅歌塔·克里斯多夫/上海人民出版社/2019-4 2 苔 8.6 周恺/楚尘文化/中信出版集团/2019-5 3 推理时钟 8.7 [日]贵志祐介/新星出版社/2019-5-1 4 本店招牌菜 9.6 [美]斯坦利·艾林/新星出版社/2019-4 5 格雷厄姆·格林短篇小说全集 评价人数不足 [英]格雷厄姆·格林/外语教学与研究出版社/2019-4 6 大树小虫 8.8 池莉/江苏凤凰文艺出版社/2019-5 7 泽诺的意识 评价人数不足 [意]伊塔洛·斯韦沃/后浪丨四川人民出版社/2019-5 8 才不要让你知道 9.4 方小孬/浙江人民美术出版社/2019-4 9 女鼓手 评价人数不足 [英]约翰·勒卡雷/上海译文出版社/2019-4-1 10 四月在愚人船 8.2 曾铮/武汉大学出版社/2019-5-1这里选取了前十行。虽然DataFrame不会对自己进行排版,但我们仍依稀可见它的存储形式:将列表存为一列,列名是列表名。
- 到这一步,我们可以发现每一行既是一本书的信息。我们使用 result.to_csv('result.csv',index=None) 语句,就实现了csv存储。
- index=None 指不写入行索引(行名称)。在 .to_csv 方法里,index默认为True,所以在这里添加参数 None 是必要的。
- 最后的csv文件在记事本中长这个样子↓
img_urls,titles,ratings,authors,details https://img3.doubanio.com/view/subject/m/public/s32289202.jpg,白日漫游,8.2,远子/广西师范大学出版社/2019-5,青年作家远子最新力作,以十四篇彼此独立而又互有呼应的短篇小说,刻画在大都市挣扎求生的年轻人,描述一种渴望自由而又无往不在枷锁之中的生活状态。 https://img1.doubanio.com/view/subject/m/public/s32281237.jpg,不识字的人,9.1,[匈]雅歌塔·克里斯多夫/上海人民出版社/2019-4,28个虚构故事和1部自传体小说。《恶童日记》作者雅歌塔流亡记忆的隐秘回响,冷峻精简的语言质感,道尽暗涌的记忆与真实的人生痛感。 https://img1.doubanio.com/view/subject/m/public/s32323469.jpg,苔,8.6,周恺/楚尘文化/中信出版集团/2019-5,一个晚清家族,一出袍哥传奇,一场历史风暴,一曲时代挽歌。在“三千年未有之大变局”下,再现了蜀中各个阶层的人物命运。 https://img1.doubanio.com/view/subject/m/public/s32295228.jpg,推理时钟,8.7,[日]贵志祐介/新星出版社/2019-5-1,贵志祐介的推理短篇小说集,共分为四个短篇,主要描写了侦探榎本与犯罪者的头脑战。本格密室推理佳作,在日本年度推理榜单上屡次上榜。 https://img1.doubanio.com/view/subject/m/public/s32285169.jpg,本店招牌菜,9.6,[美]斯坦利·艾林/新星出版社/2019-4,美国悬疑大师斯坦利•艾林的十六篇短篇小说。 https://img1.doubanio.com/view/subject/m/public/s32322848.jpg,格雷厄姆·格林短篇小说全集,评价人数不足,[英]格雷厄姆·格林/外语教学与研究出版社/2019-4,格雷厄姆·格林一生所有的短篇作品,或讽刺乖张,或冷漠怪异,贯穿着格林特有的人性思考与道德拷问,跳动着格林作品特有的节奏感。 https://img3.doubanio.com/view/subject/m/public/s32284301.jpg,大树小虫,8.8,池莉/江苏凤凰文艺出版社/2019-5,这一场看似门当户对、一见钟情的自由恋爱,却是众人运筹帷幄、通力配合的精密部署。两个人的结合,两个家族的联姻,延展出三代人近百年的跌宕命运。 https://img1.doubanio.com/view/subject/m/public/s32311017.jpg,泽诺的意识,评价人数不足,[意]伊塔洛·斯韦沃/后浪丨四川人民出版社/2019-5,首次将精神分析运用到文学作品里的意大利心理小说,深刻影响乔伊斯《尤利西斯》的创作。 https://img3.doubanio.com/view/subject/m/public/s32279850.jpg,才不要让你知道,9.4,方小孬/浙江人民美术出版社/2019-4,有些可爱的、无法用言语表述的小心动,在脑中像一幕幕电影片段,有细微的表情变化和谁也听不见的心跳。这部作品希望能用画笔记录这须臾的美好。 https://img3.doubanio.com/view/subject/m/public/s32278296.jpg,女鼓手,评价人数不足,[英]约翰·勒卡雷/上海译文出版社/2019-4-1,以色列间谍机构为了刺杀巴勒斯坦恐怖分子哈利勒,招募了一位激进的左翼英国女演员查莉。查莉的良心在两个民族之间摇摆不停,道德观也已被撕扯成碎片。
可见csv文件直接把result原封不动地存成了文本文件,添加了逗号+没打印index。虽然粗暴,但是有用!DataFrame()+to_csv()方法很好的完成了我们的任务。
- 最后是一点题外话。如图↓



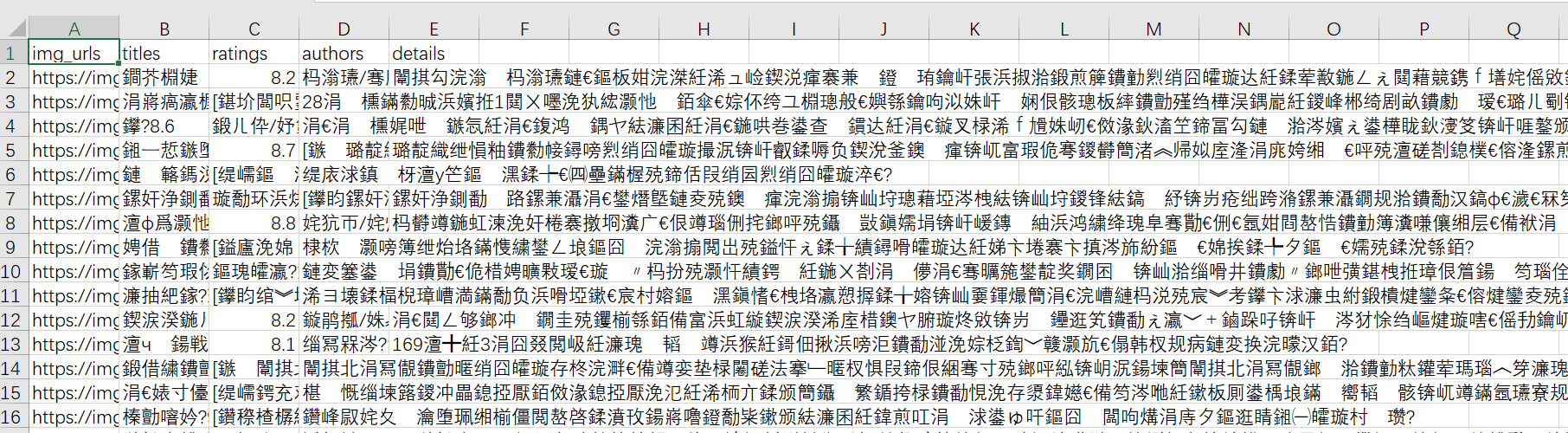
csv文件在excel中打开出现了中文编码问题,再加上这周二在python课上遇到的python2在sqlite3中输出乱码的问题,我一定要搞出个结果。暂时的感觉是:encode没有问题,问题出在了decode上。python2在写脚本时第一行加上utf-8按理就不会再出现encode的问题,utf-8会根据unicode把所有中文字符化作十六进制,这样就能以二进制的形式存储在数据库里,所以到这里都没问题。猜测sqlite3的输出没有再对二进制的中文正确解码,需要添加decode参数就能解决乱码问题。