baseline 复现
我们选择的 baseline 是 CodeNet。CodeNet 的模型可以用如下的图描述:
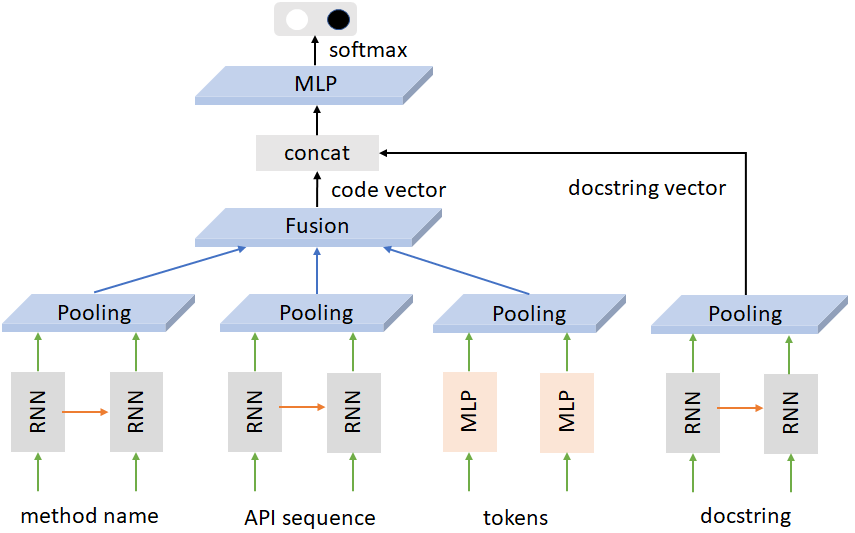
模型的输入由两个主要的分支组成。一支接受代码信息(方法名、API 序列、tokens 等),另一只则接受文档描述信息。我们的任务是将两种输入转化成为相似的 vector (即图中的 code vector 和 docstring vector)。模型使用了 RNN/MLP 的结构对输入做特征抽取。在网络的最后,CodeNet 将代码匹配视为二分类任务(匹配上与未匹配上),对提取出的 code vector 和 docstring vector 做监督。
CodeNet 是基于 CodeNN 做改进的。它们最大的不同之处是,CodeNN 使用余弦相似度计算 vector 的 loss,而 CodeNet 则将匹配任务视为二分类问题。CodeNet 这种改进可以提高匹配的准确率,但随之而来的是搜索时计算量的提高。CodeNN 在训练完成后只需对 code 和 docstring 分别做特征提取,即可抛开 model 投入生产环境,预测时用余弦相似度作为标准进行搜索即可。但 CodeNet 在生产环境中还需保留最后的 MLP 层,这里有额外的计算开销。
复现时遇到的最大问题是 CodeNet 的代码不完整,同时 README 与实际代码有若干不一致的地方。具体而言,CodeNet 的代码库中缺少了 transformer.py 这个文件,我们于是模仿 ·cleaner.py` 的写法将其恢复出来。README 与代码主要是参数的名字有些不一致,这些都不是什么大问题。
我们复现时使用 py_github 数据集。训练时我们使用 1e-3 作为学习率,并在单卡上训练 200 epochs,花费 6 个小时。我们最终性能如下:
| dataset | precision | auc | acc@top5 | acc@top10 |
|---|---|---|---|---|
| val(pool=200) | 0.8926 | 0.9519 | 0.5060 | 0.6942 |
| val(pool=800) | 0.2199 | 0.3549 | ||
| test(pool=200) | 0.8918 | 0.9507 | 0.5151 | 0.6959 |
| test(pool=800) | 0.3615 | 0.2255 |
基本达到 README 中提到的性能(甚至超过)。但奇怪的是 test 上的性能居然比 validation set 的性能还要好。此处我们还要细究原因。
对伙伴的评价
本次结对编程的伙伴是和纪言同学。结对编程时我们都比较忙,因此没有花太多额外的时间,同时线下交流比较少,我们的工作主要时线上完成的。个人感觉伙伴对ML有许多自己的想法,同时代码能力也很强。