欢迎转载,转载请注明出处,徽沪一郎。
本文详细分析TridentTopology的可靠性实现, TridentTopology通过transactional spout与transactional state相结合,能够做到tuple“只被处理一次,不多也不少”。也就是做到事务性处理exactly-once,要么成功,要么失败。
而一般的storm topology是无法保证eactly-once的处理的,它们要么是at-least-once(至少被处理一次,有可能被处理多次);要么是at-most-once(最多被处理一次,这样就存在遗漏的可能).
TridentTopology在设计中借鉴和保留了目前已经过期的transactional topology的设计思想。
Storm Topology的ack机制
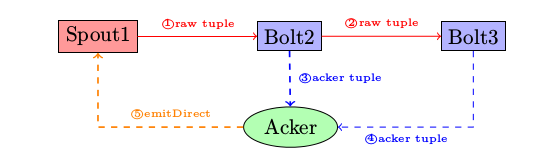
在进行TridentTopology的可靠性分析之前,我们先回顾一下在storm topology中的ack机制。ack bolt是在提交到storm cluster中,由系统自动产生的,一般来说一个topology只有一个ack bolt(当然可以通过配置参数指定多个)。
当bolt处理并下发完tuple给下一跳的bolt时,会发送一个ack给ack bolt。ack bolt通过简单的异或原理(即同一个数与自己异或结果为零)来判定从spout发出的某一个bolt是否已经被完全处理完毕。如果结果为真,ack bolt发送消息给spout,spout中的ack函数被调用并执行。如果超时,则发送fail消息给spout,spout中的fail函数被调用并执行,spout中的ack和fail的处理逻辑由用户自行填写。
如在github上的kerstel spout就能做到只有当某一个tuple被成功处理之后,它才会从缓存中移除,否则继续放入到处理队列再次进行处理。
TridentTopology的可靠性机制
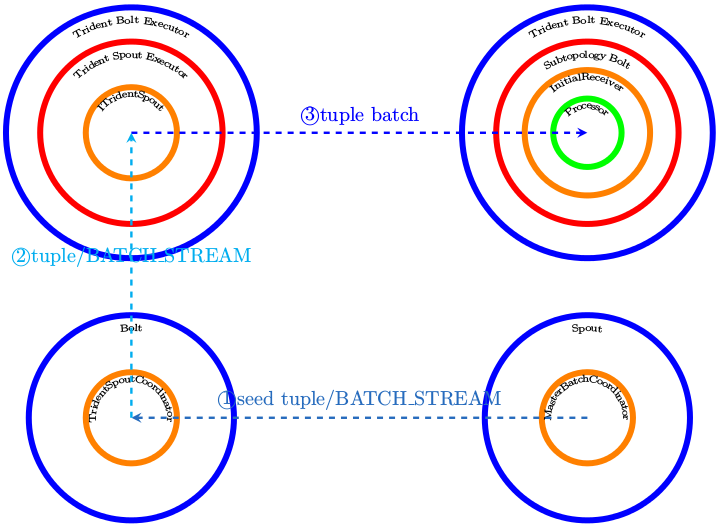
在“走读之6”一文中分析了一个tridenttopology是如何转换成storm topology的,我想用上面这幅图再次阐述一下转变后的结果。
- 一个tridenttopoloy会至少引入一个MasterBatchCoordinator,这个MBC就类似于storm topology中的spout
- newStream时使用的入参spout会裂变成两个bolt,一是TridentSpoutCoordinator,另一个是TridentSpoutExecutor
- 针对stream的各种操作则被分散到各个Bolt中,它们的执行上下文是TridentBoltExecutor
可以看出使用TridentTopology Api进行操作时,所有的东西其实都运行在bolt context中,而真正的spout是在调用TridentTopologyBuilder.buildTopology()的时候被添加的。
- MasterBatchCoordinator使用batch_stream发送一个类似于seeder tuple的东西给tridentspoutcoordinator,tridentspoutcoordinator将该信号继续下发给TridentSpoutExecutor, TridentSpout是如何一步步被调用到的呢。
- TridentBoltExecutor::execute
- TridentSpoutExecutor::execute
- BatchSpoutExecutor::execute
- ITridentSpout::emitBatch
- BatchSpoutExecutor::execute
- TridentSpoutExecutor::execute
- TridentBoltExecutor::execute
emitBatch是产生真正需要被处理的tuple的,这些tuple会被各个Operation所在的bolt所接收。它们的调用顺序是
- TridentBoltExecutor::execute
- SubtopologyBolt::execute
- InitialReceiver::receive
- TridentProcessor::execute
- InitialReceiver::receive
- SubtopologyBolt::execute
处理结束的判断依据
在TridentSpout中是如何判断所有的tuple都已经被处理的呢。
- 在每跳中认为自己处理完毕的时候,它都会告诉下一跳,即下游,我给你发送了多少tuple,如果下游将上游发送过来的确认消息与自身确实已经处理的消息比对一致的话,则认为处理都完成,于是发送ack.
- 问题的关键变成每一个bolt是如何判断自己已经处理完毕的呢,请看步骤3
- 总有一个bolt是没有上游的,即TridentSpoutExecutor,它只会收到启动指令,但不接收真正的业务数据,于是它会告诉下一跳,我发了多少tuple给你。
STREAM
在MasterBatchCoordinator中定义了三种不同的stream,这三种stream分别是
- BATCH_STREAM
- COMMIT_STREAM
- SUCCESS_STREAM
这些stream分别在什么时候被使用呢,下图给出一个大概的时序
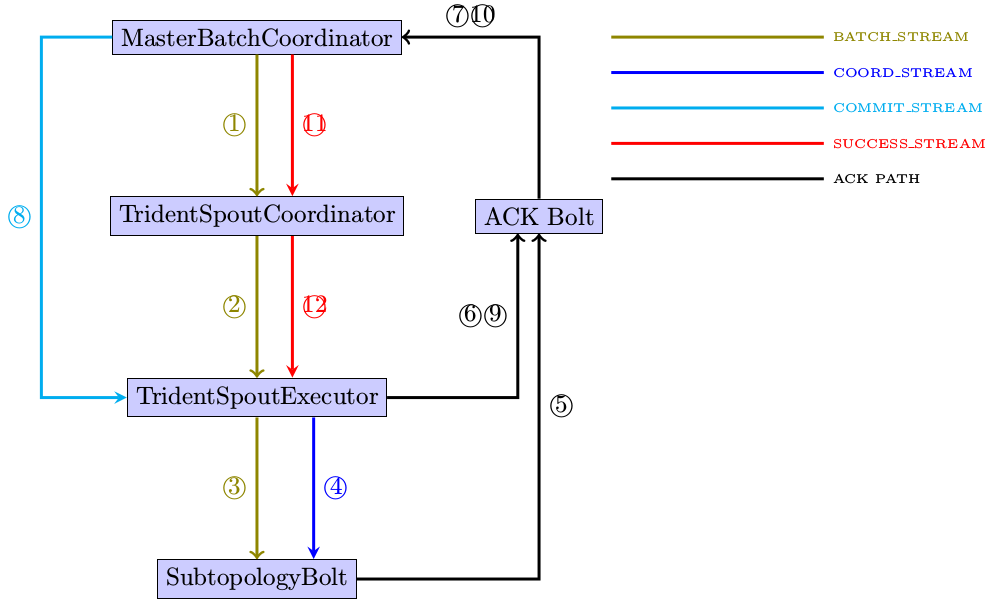
简要说明:
- masterbatchcoordinator通过batch_stream发送seeder tuple给tridentspoutcoordinator
- tridentspoutcoordinator给tridentspoutexecutor继续传递该指令
- TridentSpoutExecutor在收到启动指令后,调用ITridentSpout接口的实现类进行emitBatch
- TridentSpoutExecutor在发送完一批batch后,finishBatch被调用,通过emitDirect会给下一跳通过coord_stream发送trackedinfo,即我已经发送了多少消息给你
- TridentSpoutExecutor紧接着还会给ack bolt发送ack消息,ack bolt将其传达到MasterBatchCoordinator
- MasterBatchCoordinator在收到第一个ack后,将状态置为processed
- 当MasterBatchCoordinator再次收到ack后,会将状态转为committing,同时通过commit_stream发送tuple给TridentSpoutExecutor
- 收到commit_stream上传来的tuple后,TridentSpoutExecutor会调用ITridentSpout中的emmitter, emmitter::commit()被执行,TridentSpoutExecutor会再次ack收到tuple
- MasterBatchCoordinator在收到这个tuple之后,会认为针对某一个seeder tuple的处理已经完全实现,于是通过SUCCESS_STREM告知TridentSpoutCoordinator,所有的活都已经都完成了,收工。
- 收到Success_stream上传来的信号后,ITridentSpout中的内嵌子类Emmit和Coordinator中相应的success方法会被调用执行。
注意:
- 为了描述方便,将TridentTopology进行了简化,认为其在转换成真正的storm topology时,只有一个TridentProcessor所在的bolt。真实的情况可能比这复杂,但消息的传递路径还是差不多的。
- 注意在TridentTopology中ack会被多次反复调用,这不同于普通的storm topology
状态机
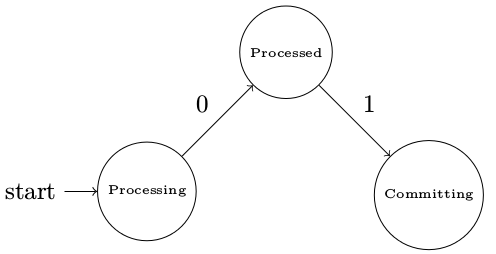
在MasterBatchCoordinator中,针对每一个seeder tuple,其状态机如下图所示。注意这些状态是会被保存到zookeeper server中的,使用的api定义在TransactionalState中。
总结
通过上面的分析可以看出,TridentTopology实现了一个比较好的框架,但真正要做到exactly-once的处理,还需要用户自己去实现ITridentSpout中的两个重要内嵌类,Emmitter和Coordinator。
具体如何实现该接口,可以查看storm-core/src/jvm/storm/trident/testing目录下的FixedBatchSpout.java和FeederCommitterBatchSpout.java