欢迎转载,转载请注明出处,徽沪一郎。
TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作在tridenttopology提供的api中都有类似的影射。关于TridentTopology的使用及运行原理,当前进行详细分析的文章不多。
从TridentTopology到vanilla topology(普通的topology)由三个层次组成:
- 面向最终用户的概念stream, operation
- 利用planner将tridenttopology转换成vanilla topology
- 执行vanilla topology
本文尝试TridentTopology是如何先一步步转换成普通的storm Topology(即vanila topology), 转换后的topology的执行中有哪些区别?
概述
从TridentTopology到基本的Topology有三层,下图给出一个全局的视图。
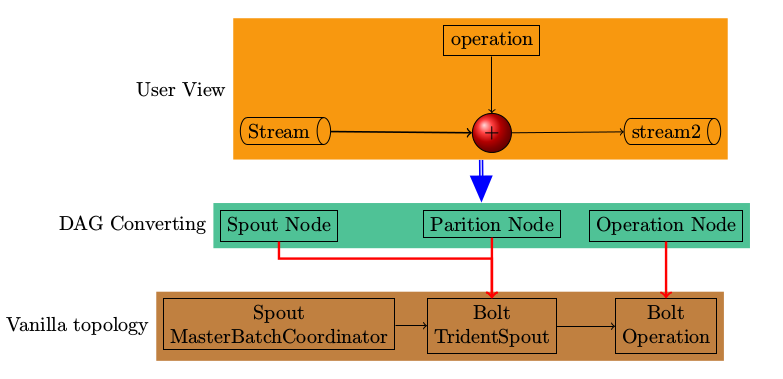
创建TridentTopology
下面的代码摘自StormStarter中的TridentWordCount.java
TridentTopology topology = new TridentTopology(); topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"), new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")).parallelismHint(16); return topology.build();
上述代码的newStream一行,分两大部分,一是使用newStream来创建一个stream对象,然后针对该Stream进行各种操作,each/shuffle/persistentAggregate等就是各种operation.
用户在使用TridentTopology的时候,只需要熟悉Stream和TridentTopology中的API函数即可。
转换TridentTopology为Vanilla Topology
上一节创建了Stream,但是如何将其与原有的Spout及Bolt联系起来呢?问题的关键就在TridentTopology::build函数和TridentTopologyBuilder::buildTopology
TridentTopology::build
newStream及其后的函数调用创建了一个含有三大类节点的List,利用该List创建了一个有向非循环图(DAG)。这三类节点分别是operation, partition, spout,在build函数将节点分类分别加入到boltNodes或spoutNodes,注意此处的spout或bolt不能等同于普通的spout和bolt.
TridentTopologyBuilder::buildTopology
利用在build函数中创建的boltNodes,spoutNodes及生成的graph来创建vanilla topology所需要的bolt及spout.
在buildTopology中会看到类似的代码片段。
builder.setBolt(spoutCoordinator(id), new TridentSpoutCoordinator(c.commitStateId, (ITridentSpout) c.spout)) .globalGrouping(masterCoordinator(c.batchGroupId), MasterBatchCoordinator.BATCH_STREAM_ID) .globalGrouping(masterCoordinator(c.batchGroupId), MasterBatchCoordinator.SUCCESS_STREAM_ID);
builder.setSpout(masterCoordinator(batch), new MasterBatchCoordinator(commitIds, batchesToSpouts.get(batch)));
for(String b: c.committerBatches) { specs.get(b).commitStream = new GlobalStreamId(masterCoordinator(b), MasterBatchCoordinator.COMMIT_STREAM_ID); } BoltDeclarer d = builder.setBolt(id, new TridentBoltExecutor(c.bolt, batchIdsForBolts, specs), c.parallelism);
最终生成的普通Topology,与普通Topology中的Spout相对应的是MasterBatchCoordinator,而在创建TridentTopology使用的spout则成了Bolt,使用于Stream上的各种Operation也存在于多个普通Bolt中。
TridentTopology的执行
TridentTopology被转换为普通的Topology(vanilla Topology)之后提交到nimbus,它的具体执行过程有什么不同呢?
主要有几点:
- MasterBatchCoordinator通过Batch_stream_id来发送通知给TridentSpoutExecutor
- TridentSpoutExecutor收到通知发送成批的tuple给下一跳的Bolt
- 下一跳的Bolt收到tuple之后,使用TridentBoltExecutor来进行处理
- TridentBoltExecutor调用SubtopologyBolt::execute
- InitialReceiver::execute被调用
- TridentProcessor::execute被调用
MasterBatchCoordinator收到ack之后,会发送success消息给Spout
MasterBatchCoordinator在commit的时候,会发送commit消息给Spout,让Spout将缓存的消息删除