前一段时间,给一位朋友公司做咨询,看到他们的很多的存储过程都存在动态sql语句执行,sp_executesql,即使在没有动态表名,动态字段名的情况下仍然使用sp_executesql,这个做法是不太明智的,会存在一些性能方面的问题。
先说说什么场景使用这个系统存储过程吧,sp_executesql,是sql server动态执行一段可以带有参数(内参,外参)的语句文本的系统存储过程,传入sp_executesql 的参数会以参数的形式传递,不会是以拼凑sql的形式传递,所以能够在不得不拼接sql语句的情景下使用以防止sql注入。不得不拼接sql的情景包括 传递in内参数,动态决定表列,列名,还有就是like,为防止sql注入,也不得不拼接sql。按理来说这是一个非常好的存储过程,但是,由于他本身的限制,会对查询性能有很大的影响,下面我举个例子。
使用northwind数据库,
执行:
select * from orders where customerid = 'SAVEA';
执行:
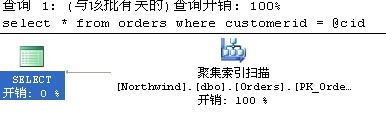
select * from orders where customerid = 'CENTC';
这两个语句的唯一不同就是客户号不一样,一个在订单表内有31个重复值,一个没有重复值。
然后咱们再来对比当这个语句放在了一个动态执行的sql语句内部的情况如何。
创建如下存储过程:
![]()
![]() Code
Code
USE [Northwind]
GO
/****** 对象: StoredProcedure [dbo].[testexecutesql] 脚本日期: 10/15/2009 20:09:45 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [dbo].[testexecutesql](@customerid nchar(5))
as
begin
exec sp_executesql N'select * from orders where customerid = @cid ',
N'@cid as nchar(5)',@cid = @customerid ;
end
然后执行这个存储过程:
exec testexecutesql 'SAVEA';
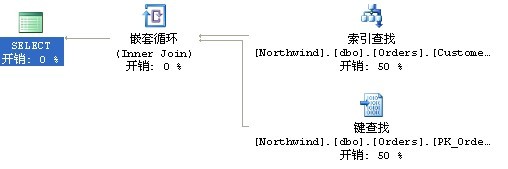
其执行计划如下图,是个聚集索引扫描:
(31 行受影响)
表 'Orders'。扫描计数 1,逻辑读取 22 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用聚集索引扫描是个很明智的选择,咱们可以来看看customerid上的非聚集索引的统计信息,orders表共830行,其中客户'SAVEA'就有31个订单,所以优化器选择使用聚集索引扫描而不是嵌套循环的book mark look up。
然后咱们再来执行一个:
exec testexecutesql 'CENTC';
区别仅仅是传入的customerid参数不一样,再看看执行计划,仍然是一样,io也是一样,就是返回的行数只有一行,按理来说,只返回一行,优化器应该会选择使用非聚集索引,嵌套查找数据,但是优化器却没有好好利用customerid上的统计信息,仍然使用了聚集索引扫描,为什们?难道是索引上的统计信息不及时吗?不,在手动使用fullscan后的统计信息仍然是一样的查询计划,为什么呢?
因为sp_executesql本身就是一个存储过程,他执行动态语句的参数是不会被利用上的,所以当第一次编译的时候产生的计划,存储过程testexecutesql 是无法嗅探到的,即无法去引用customerid上的统计信息来做查询计划参考的,所以第一次编译的查询计划是聚集索引扫描就是扫描,即使第二次执行的时候应该是查找。
如何才能改变这一现状呢?
可以使用提示符,recompile强制让存储过程在执行的时候重新编译,来获得最好的执行计划,不过这也是有代价的,就是每次都需要编译,不过相比那些被浪费掉的IO,对一些大表的性能低下的查询计划还是很值得的。于是,我们把存储过程改写如下:
USE [Northwind]
GO
/****** 对象: StoredProcedure [dbo].[testexecutesql] 脚本日期: 10/15/2009 20:09:45 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [dbo].[testexecutesql](@customerid nchar(5))
as
begin
exec sp_executesql N'select * from orders where customerid = @cid option(recompile) ',
N'@cid as nchar(5)',@cid = @customerid ;
end
这样再次执行exec testexecutesql 'CENTC'; exec testexecutesql 'SAVEA';
都能获得一个最优的查询计划。
sql server能够支持语句级的重编译,自动嗅探重编译环境,阀值,使得绝大部分情况下能够很好的利用编译后的查询计划,提高数据库整体性能。我在08年初写过的一个ppt,是关数据库于重编译的,大家可以下载看看,http://img.cyzone.cn/temp/SQL SERVER 高级技巧系列之二:重编译详解.ppt
如果有朋友关注数据库性能方面的东西,可以加入我创建的一个小组,http://home.cnblogs.com/group/sql/ 欢迎提出自己遇到的性能问题。