关键字(keywords):SVM 支持向量机 SMO算法 实现 机器学习
假设对SVM原理不是非常懂的,能够先看一下入门的视频,对帮助理解非常实用的,然后再深入一点能够看看这几篇入门文章,作者写得挺具体,看完以后SVM的基础就了解得差点儿相同了,再然后买本《支持向量机导论》作者是Nello Cristianini 和 John Shawe-Taylor,电子工业出版社的。然后把书本后面的那个SMO算法实现就基本上弄懂了SVM是怎么一回事,最后再编写一个SVM库出来,比方说像libsvm等工具使用,呵呵,差点儿相同就这样。这些是我学习SVM的整个过程,也算是经验吧。
以下是SVM的简化版SMO算法,我将结合Java代码来解释一下整个SVM的学习训练过程,即所谓的train训练过程。那么什么是SMO算法呢?
SMO算法的目的无非是找出一个函数f(x),这个函数能让我们把输入的数据x进行分类。既然是分类肯定须要一个评判的标准,比方分出来有两种情况A和B,那么怎么样才干说x是属于A类的,或不是B类的呢?就是须要有个边界,就好像两个国家一样有边界,假设边界越明显,则就越easy区分,因此,我们的目标是最大化边界的宽度,使得很easy的区分是A类还是B类。
在SVM中,要最大化边界则须要最小化这个数值:
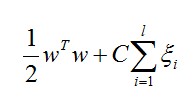
w:是參量,值越大边界越明显
C代表惩处系数,即假设某个x是属于某一类,可是它偏离了该类,跑到边界上后者其它类的地方去了,C越大表明越不想放弃这个点,边界就会缩小![]() 代表:松散变量
代表:松散变量
但问题似乎还不好解,又由于SVM是一个凸二次规划问题,凸二次规划问题有最优解,于是问题转换成下列形式(KKT条件):
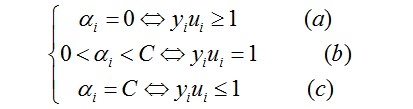 …………(1)
…………(1)
这里的ai是拉格朗日乘子(问题通过拉格朗日乘法数来求解)
对于(a)的情况,表明ai是正常分类,在边界内部(我们知道正确分类的点yi*f(xi)>=0)
对于(b)的情况,表明了ai是支持向量,在边界上
对于(c)的情况,表明了ai是在两条边界之间
而最优解须要满足KKT条件,即满足(a)(b)(c)条件都满足
下面几种情况出现将会出现不满足:
yiui<=1可是ai<C则是不满足的,而原本ai=C
yiui>=1可是ai>0则是不满足的而原本ai=0
yiui=1可是ai=0或者ai=C则表明不满足的,而原本应该是0<ai<C
所以要找出不满足KKT的这些ai,并更新这些ai,但这些ai又受到另外一个约束,即
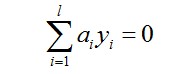
因此,我们通过还有一个方法,即同一时候更新ai和aj,满足下面等式
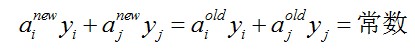
就能保证和为0的约束。
利用yiai+yjaj=常数,消去ai,可得到一个关于单变量aj的一个凸二次规划问题,不考虑其约束0<=aj<=C,能够得其解为:
 ………………………………………(2)
………………………………………(2)
这里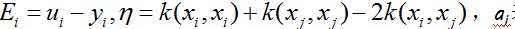 ………………(3)
………………(3)
表示旧值,然后考虑约束0<=aj<=C可得到a的解析解为:
 …………(4)
…………(4)
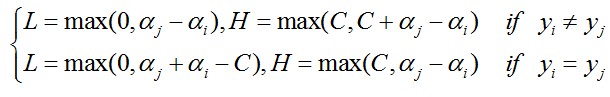
对于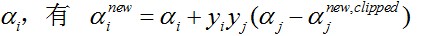
那么怎样求得ai和aj呢?
对于ai,即第一个乘子,能够通过刚刚说的那几种不满足KKT的条件来找,第二个乘子aj能够找满足条件
 …………………………………………………………………………(5)
…………………………………………………………………………(5)
b的更新:
在满足条件: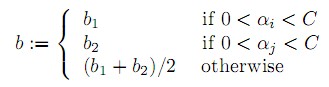 下更新b。……………(6)
下更新b。……………(6)
最后更新全部ai,y和b,这样模型就出来了,然后通过函数:
 ……………………………………………………(7)
……………………………………………………(7)
输入是x,是一个数组,组中每个值表示一个特征。
输出是A类还是B类。(正类还是负类)
下面是基本的代码段:
执行后的结果还算能够吧,測试数据主要是用了libsvm的heart_scale的数据。
预測的正确率达到73%以上。
假设我把核函数从线性的改为基于RBF将会更好点。
最后,说到SVM算法实现包,应该有非常多,包含svm light,libsvm,有matlab本身自带的svm工具包等。
另外,完整的代码,我将上传到CSDN下载地址上提供下载。
如理解有误敬请指正!谢谢!
我的邮箱:chen-hongqin@163.com
我的其它博客:
百度:http://hi.baidu.com/futrueboy/home javaeye:http://futrueboy.javaeye.com/