1.目标分析:http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8
说明浏览器接受的是utf8的编码
(1)在浏览器上单击下一页,pn就会增加50:http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8&pn=50
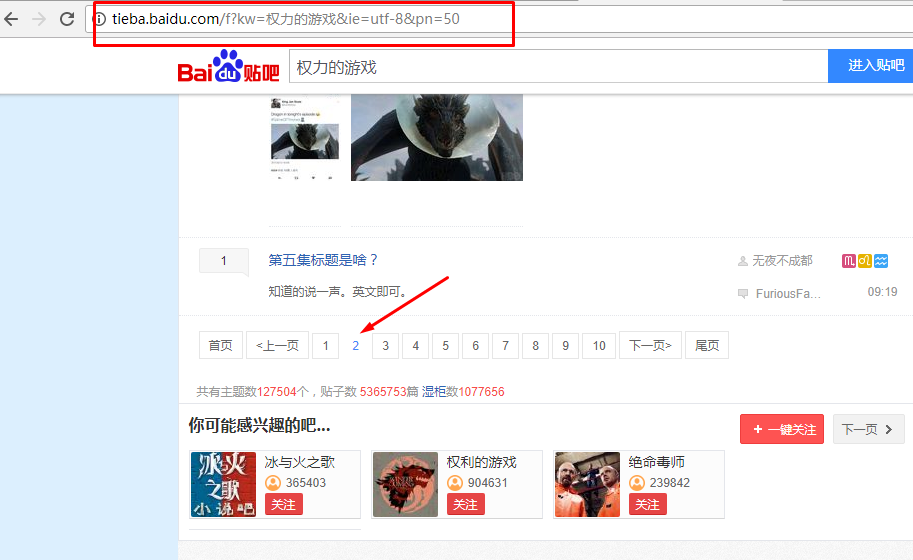
(2)查看帖子和源代码:
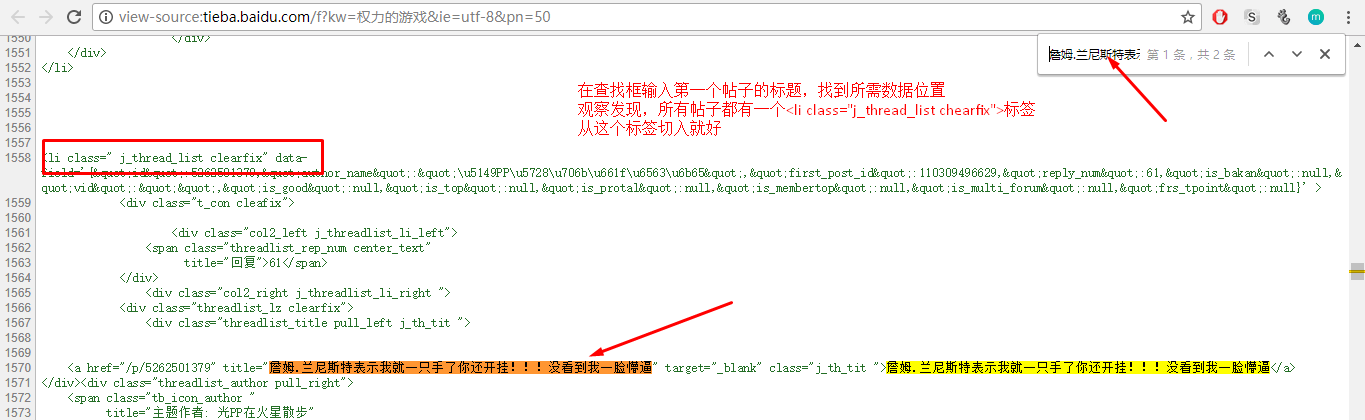
2.项目实施:
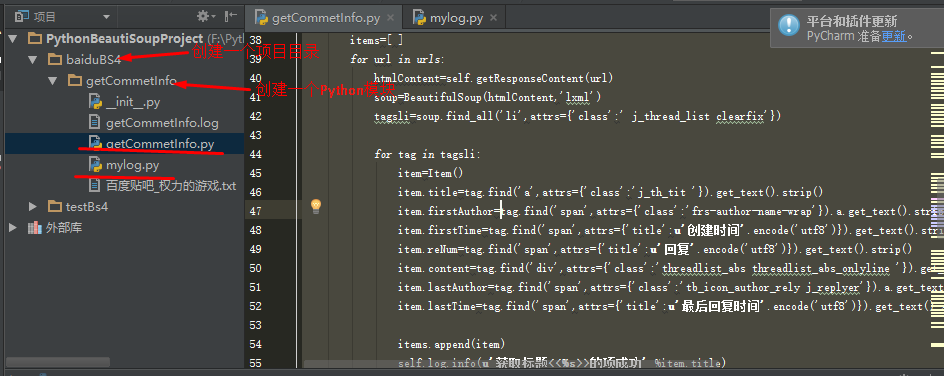
(1)创建项目:查看项目所需的标签项:


(3)项目源代码,文件 getCommetInfo.py:
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import urllib2
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
class Item(object):
title=None #帖子标题
firstAuthor=None #帖子创建者
firstTime=None #帖子创建时间
reNum=None #总回复数
content=None #最后回复内容
lastAuthor=None #最后回复者
lastTime=None #最后回复时间
class GetTiebaInfo(object):
def __init__(self,url):
self.url=url
self.log=mylog()
self.pageSum=5
self.urls=self.getUrls(self.pageSum)
self.items=self.spider(self.urls)
self.pipelines(self.items)
def getUrls(self,pageSum):
urls=[ ]
pns=[str(i*50) for i in range(pageSum)]
ul=self.url.split('=')
for pn in pns:
ul[-1]=pn
url='='.join(ul)
urls.append(url)
self.log.info(u'获取URLS成功')
return urls
def spider(self,urls):
items=[ ]
for url in urls:
htmlContent=self.getResponseContent(url)
soup=BeautifulSoup(htmlContent,'lxml')
tagsli=soup.find_all('li',attrs={'class':' j_thread_list clearfix'})
for tag in tagsli:
item=Item()
item.title=tag.find('a',attrs={'class':'j_th_tit '}).get_text().strip()
item.firstAuthor=tag.find('span',attrs={'class':'frs-author-name-wrap'}).a.get_text().strip()
item.firstTime=tag.find('span',attrs={'title':u'创建时间'.encode('utf8')}).get_text().strip()
item.reNum=tag.find('span',attrs={'title':u'回复'.encode('utf8')}).get_text().strip()
item.content=tag.find('div',attrs={'class':'threadlist_abs threadlist_abs_onlyline '}).get_text().strip()
item.lastAuthor=tag.find('span',attrs={'class':'tb_icon_author_rely j_replyer'}).a.get_text().strip()
item.lastTime=tag.find('span',attrs={'title':u'最后回复时间'.encode('utf8')}).get_text().strip()
items.append(item)
self.log.info(u'获取标题<<%s>>的项成功' %item.title)
return items
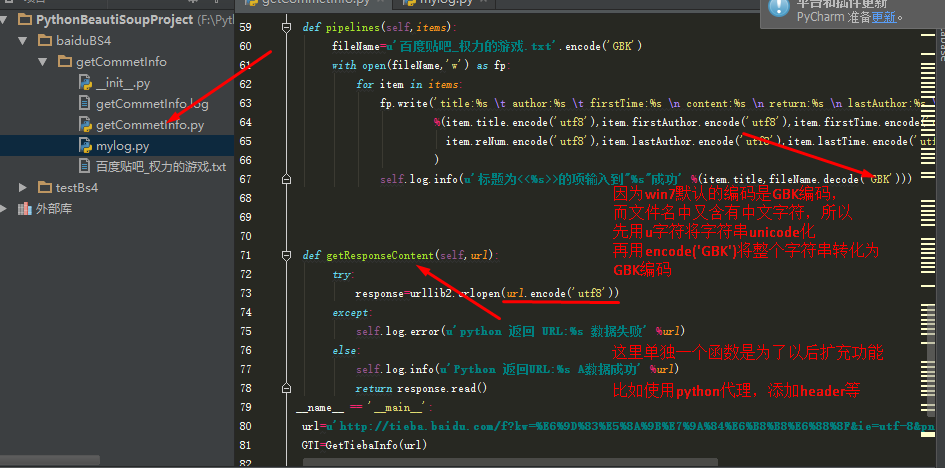
def pipelines(self,items):
fileName=u'百度贴吧_权力的游戏.txt'.encode('GBK')
with open(fileName,'w') as fp:
for item in items:
fp.write('title:%s author:%s firstTime:%s content:%s return:%s lastAuthor:%s lastTime:%s '
%(item.title.encode('utf8'),item.firstAuthor.encode('utf8'),item.firstTime.encode('utf8'),item.content.encode('utf8'),
item.reNum.encode('utf8'),item.lastAuthor.encode('utf8'),item.lastTime.encode('utf8'))
)
self.log.info(u'标题为<<%s>>的项输入到"%s"成功' %(item.title,fileName.decode('GBK')))
def getResponseContent(self,url):
try:
response=urllib2.urlopen(url.encode('utf8'))
except:
self.log.error(u'python 返回 URL:%s 数据失败' %url)
else:
self.log.info(u'Python 返回URL:%s A数据成功' %url)
return response.read()
if __name__ == '__main__':
url=u'http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8&pn=50'
GTI=GetTiebaInfo(url)
(4)项目源代码,文件mylog.py:
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import logging
import getpass
import sys
class MyLog(object):
###########类MyLog的构造函数
def __init__(self):
self.user=getpass.getuser()
self.logger=logging.getLogger(self.user)
self.logger.setLevel(logging.DEBUG)
#########日志文件名
self.logFile=sys.argv[0][0:-3]+'.log'
self.formatter=logging.Formatter('%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12s ')
#########日志显示到屏幕并输出到日志文件中
self.logHand=logging.FileHandler(self.logFile,encoding='utf8')
self.logHand.setFormatter(self.formatter)
self.logHand.setLevel(logging.DEBUG)
self.logHandSt=logging.StreamHandler()
self.logHandSt.setFormatter(self.formatter)
self.logHandSt.setLevel(logging.DEBUG)
self.logger.addHandler(self.logHand)
self.logger.addHandler(self.logHandSt)
#####日志的5个级别对应以下5个函数
def debug(self,msg):
self.logger.debug(msg)
def info(self,msg):
self.logger.info(msg)
def warn(self,msg):
self.logger.warn(msg)
def error(self,msg):
self.logger.error(msg)
def critical(self,msg):
self.logger.critical(msg)
if __name__ == '__main__':
mylog=MyLog()
mylog.debug(u"I'm debug 测试中文")
mylog.info("I'm info")
mylog.warn("I'm warn")
mylog.error(u"I'm error 测试中文 ")
mylog.critical("I'm critical")
(5)右击文件运行结果:
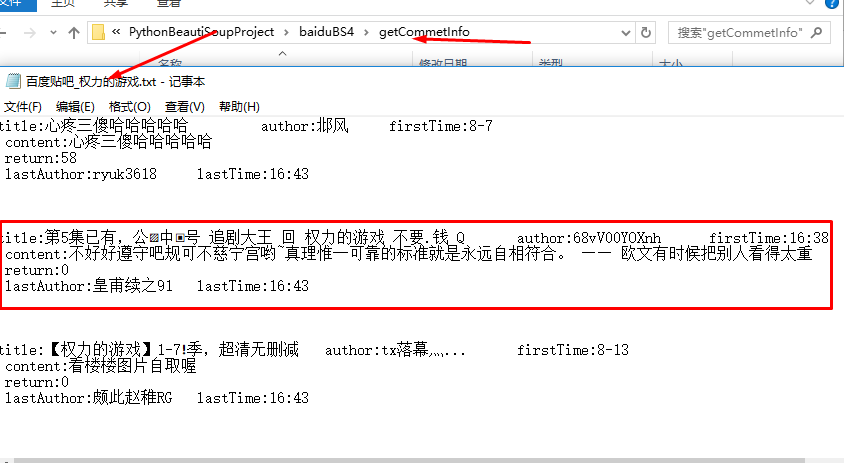
3.代码分析:
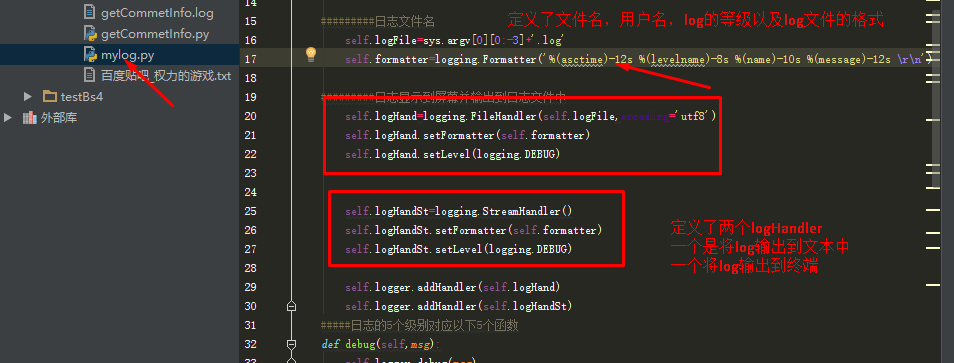
主程序getCommetInfo.py部分解析: