1.用Chrome浏览器重新检查网站元素:切换到Network界面
选择右边的XHR过滤(XHR时XMLHttpRequest对象,一般Ajax请求的数据都是结构化数据),这样就剩下了为数不多的几个请求,剩下的就靠我们自己一个一个的检查吧
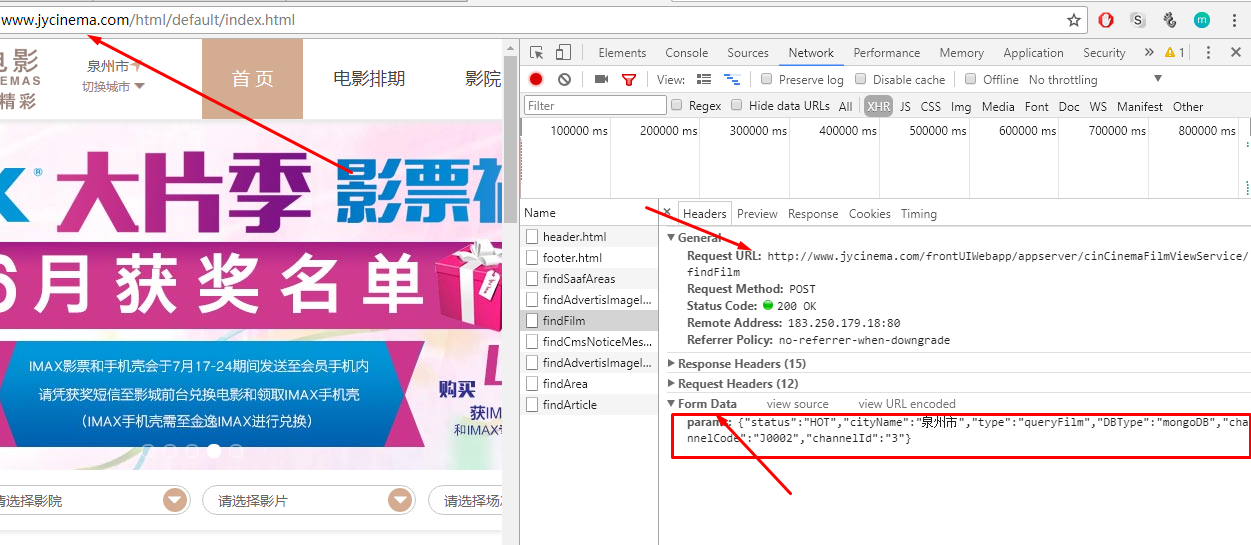
通过分析每个接口返回的request和response信息,检查发现findFilm接口,是我们需要的接口!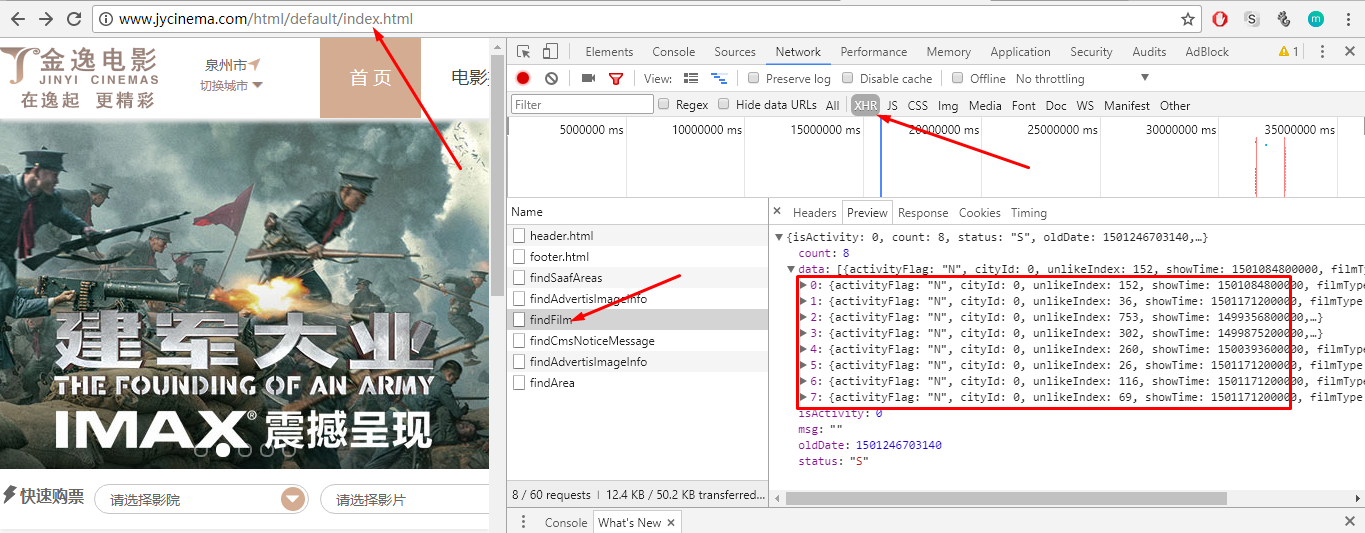
2.XMLHttpRequest Level 2添加了一个新的接口FormData.利用FormData对象,我们可以通过JavaScript用一些键值对来模拟一系列表单控件,我们还可以使用XMLHttpRequest的send()方法来异步的提交这个"表单".比起普通的ajax,使用FormData的最大优点就是我们可以异步上传一个二进制文件.

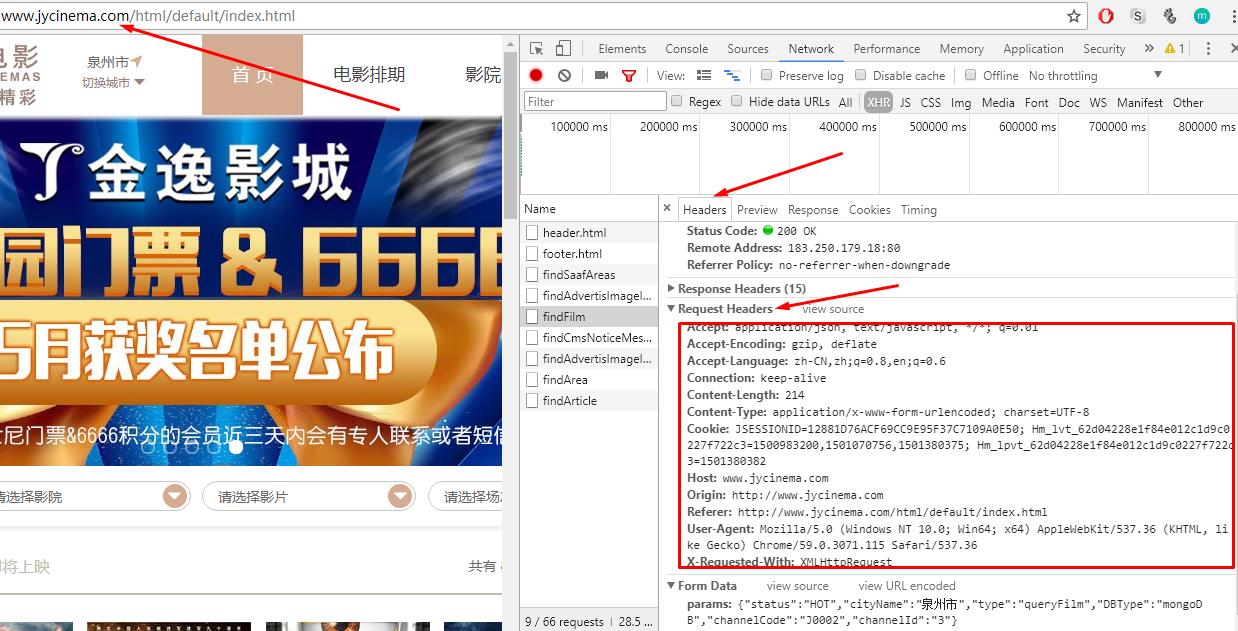
3.Request中得参数很简单,根据英文意思就可以猜出意义,由于我们要抓取所有电影的信息,所以不需要定制这些参数,后面直接将这些参数post给接口就行了
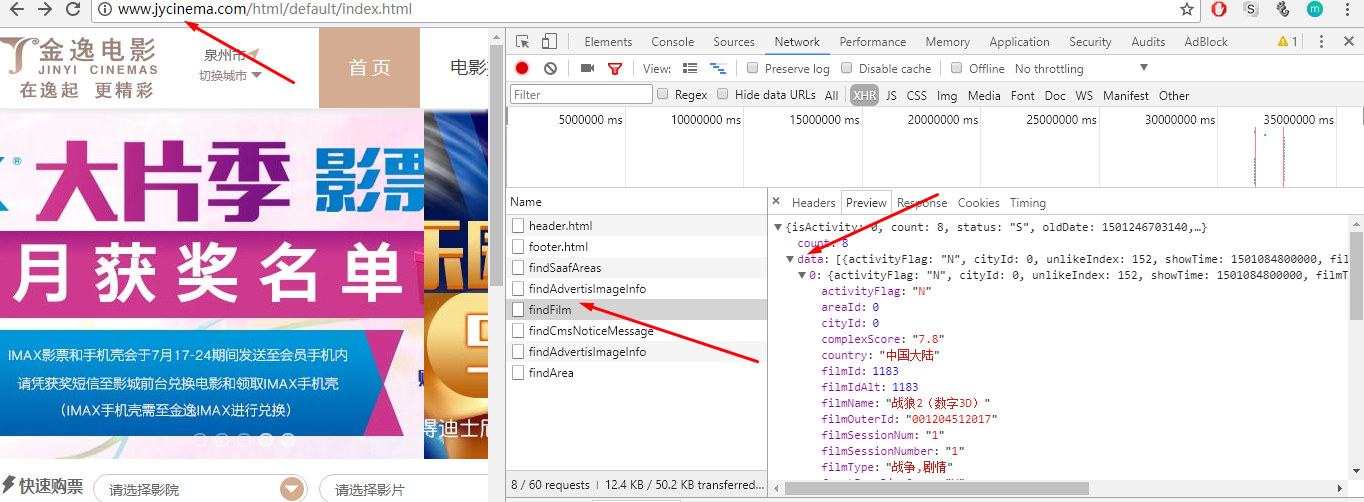
在Response中可以获得到的有用数据有两个:所有电影信息的列表data,data列表中得对象都有如下图所示的json格式,它也正是我们需要的电影信息的数据
4.Scrapy编码:
(1)定义Item:
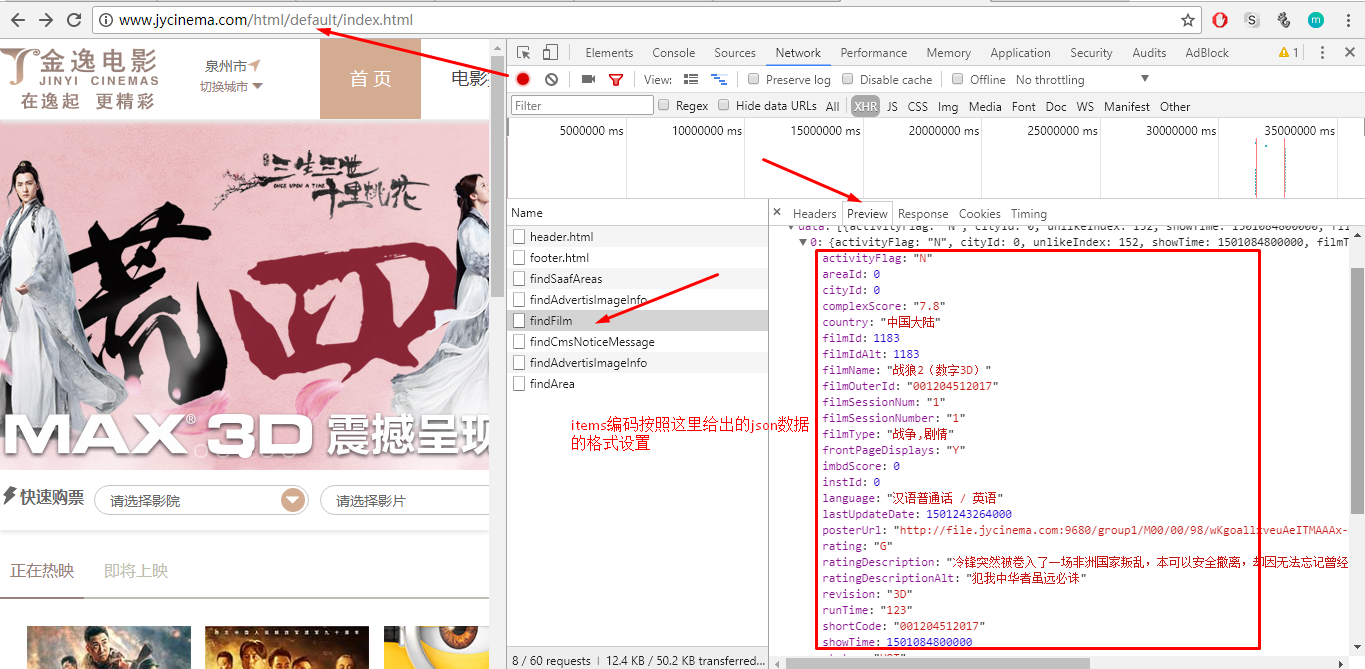
如下:我只选择了一些我认为有用的key(也就是有用的信息)
import scrapy
class TodaymovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
filmName=scrapy.Field() #电影名字
filmType=scrapy.Field()
language=scrapy.Field()
ratingDescription=scrapy.Field()
status=scrapy.Field()
revision=scrapy.Field()
(2)Spider编写:
# -*- coding: utf-8 -*-
import urllib2
import os
import re
import sys
import codecs
import json
from scrapy import Spider
from scrapy.selector import Selector
from todayMovie.items import TodaymovieItem
from scrapy.http import FormRequest
from scrapy.http import Request
from scrapy.utils.response import open_in_browser
reload(sys)
sys.setdefaultencoding('utf8')
class HqumoviespiderSpider(Spider):
name = 'HQUMovieSpider'
allowed_domains = ['jycinema.com']
custom_settings = {
"DEFAULT_REQUEST_HEADERS":{
'authority':'www.jycinema.com',
'accept':'application/json, text/javascript, */*; q=0.01',
'accept-encoding':'gzip, deflate',
'accept-language':'zh-CN,zh;q=0.8,en;q=0.6',
'origin':'http://www.jycinema.com',
'referer':'http://www.jycinema.com/html/default/index.html',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'x-requested-with':'XMLHttpRequest',
'cookie':'JSESSIONID=3E90F1084862B8B2F08DB25D1008BD2E; Hm_lvt_62d04228e1f84e012c1d9c0227f722c3=1500983200,1501070756; Hm_lpvt_62d04228e1f84e012c1d9c0227f722c3=1501246698'
},"ITEM_PIPELINES":{
'todayMovie.pipelines.TodaymoviePipeline':300
#ITEM_PIPELINES,自定义管道模块,当item获取到数据后会调用你指定的管道处理命令,这个后面会贴上代码,因为这个不影响本文的内容,数据的处理可以因人而异。
}
}
def start_requests(self):
url="http://www.jycinema.com/frontUIWebapp/appserver/cinCinemaFilmViewService/findFilm"
requests = []
for i in reload(1,8):
formdata={
"status":"HOT",
"cityName":"泉州市",
"type":"queryFilm",
"DBType":"mongoDB",
"channelCode":"J0002",
"channelId":"3"
}
request = FormRequest(url,callback=self.parse_movie,formdata=formdata)
requests.append(request)
return requests
def parse_movie(self, response):
jsonBody=json.loads(response.body.decode('gbk').encode('utf-8'))
movies=jsonBody['isActivity']['data']
movieItems=[]
for dict in movies:
movieItem=TodaymovieItem()
movieItem['filmName']=dict['filmName']
movieItem['filmType']=dict['filmType']
movieItem['language']=dict['language']
movieItem['ratingDescription']=dict['ratingDescription']
movieItem['status']=dict['status']
movieItem['revision']=dict['revision']
movieItems.append(movieItem)
return movieItems
Spider部分代码解析:
(1)

(2)

(3)

5.数据后处理:数据后处理的代码写在pipelines.py文件中
import time
class TodaymoviePipeline(object):
def process_item(self, item, spider):
now=time.strftime('%Y-%m-%d',time.localtime())
fileName='HQU'+now+'.txt'
with open(fileName,'a') as fp:
fp.write(item['filmName'][0].encode('utf-8')+' ')
return item
代码详解:
这个脚本没什么,比较简单,就是把当日的年月日抽取出来当成文件名的一部分,然后把HQUMovieSpdier.py中获取项的内容输入到该文件中,这个脚本只需要注意两点:
(1)open函数创建文件时必须是以追加的形式创建,也就是说open函数的第二个参数必须是a,因为HQUMovieSpider返回的是一个item列表items,
这里写入的文件只能是一个一个iten写入,如果open函数第二个参数是w,造成的后果就是先擦除前面写入的内容
(2)保存文件中的内容如果含有汉字就必须转换为utf-8码,汉字的unicode码保存到文件中正常后无法识别
6.分派任务的settings.py:

7.执行这个Scrapy爬虫:只要在todayMovie项目下的任意目录下执行如下命令:
scrapy crawl HQUMovieSpider
8.执行报错!!!!这是一个关于获取json数据的错误?这篇博文中解决不了,请看下一篇博文吧,哎哎哎哎!!!!好难啊,好烦啊!
