0X00:起因
想背些俄语,用了沪江,鳄鱼这些app,但总感觉不舒服。还是喜欢像墨墨背单词这种的逻辑(总词数=旧词+新词。没错就是懒,一天就想背二十几个就好)。就准备按照自己舒服的逻辑写一个。
0X01:思路
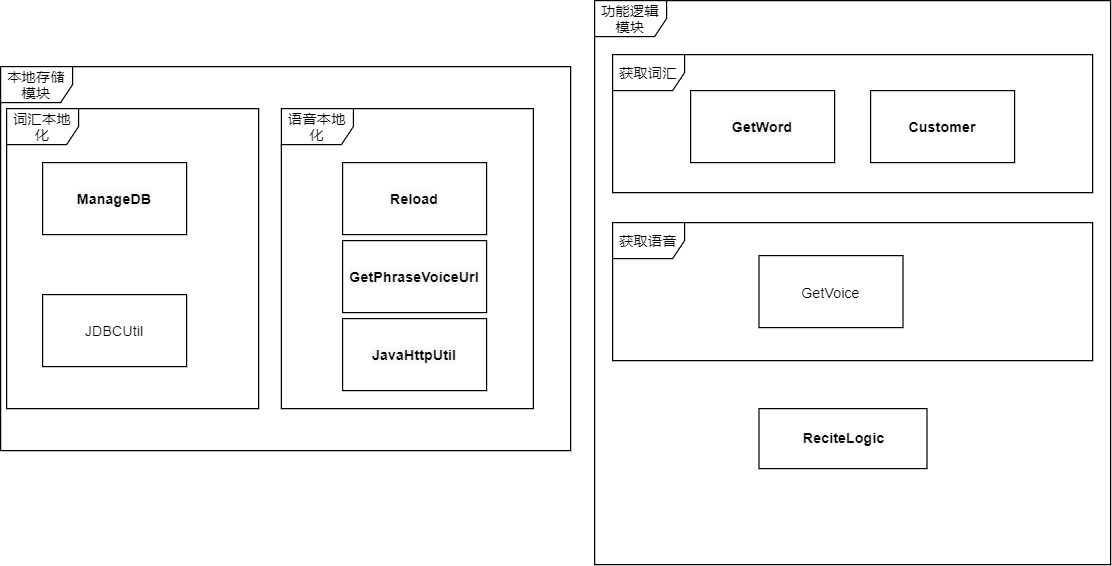
1:整个项目分2模块:本地化模块+功能逻辑模块
1.1:本地化模块:分为单词本地化和语音本地化
1.1.1:单词本地化主要涉及从数据库中操作数据
1.1.2:语音本地化主要涉及生成俄语的语音。这里尝试过Sapi,marrytts,rhvoice这些本地文本转语音,然鹅都失败了.....sapi只支持中英文(甚至想找俄语windows系统拷贝一份),marrytts最新版没有俄语发音包(老版有但下载页面404唉。最后的rhvoice安装后一脸懵逼)。最后还是转向在线生成。原本想申请百度tts接口,结果百度没俄语(如果我没看错。。。)最后无意找到一个在线生成俄语语音的网站,分析了下post,自己写个函数拼一拼参数。再处理下response,请求目标url拿到MP3文件
1.2:功能逻辑主要分为新词+旧词的处理。按照平常在墨墨背单词的习惯。
1.2.1:先将要复习的元素拿出来确定下会不会(元素我设置了grade字段,对应艾宾浩斯遗忘曲线)会的话就按设置下一次复习时间(1,2,3,5,7,15,30,60,180设置),不会就设置为回到明天复习(即1)会的话就提示一个grade。
1.2.2:复习后开始学习新词,有可能要复习的词太多导致新词为0。新词统一grade置1。
1.2.3:复习或者学新词都会先放语音然后有1,2,3,4四种选项,选0说明很熟直接不用背。选1:进入拼写验证,若正确则权重-3(初始为5)选2,3:说明不会,放到队列第三个词后(免得词太多前面记得后面忘了,很重要以防心态爆炸(╯‵□′)╯︵┻━┻)
0X02:关键问题
1.俄语单词数据库:网上找了很久没有现成的,只能自己从网页上扒拉下来再定规则导入数据库,所以很烂,原词译文都糊到一起了,打算以后做成web项目再好好修。
2.俄语语音:本来想用开源的tts,后来试了一圈还是用爬虫在线搞了,所以必需要联网(除非今天不学新词)爬下来的MP3都放在本地了,不手动删的话可以复用。
3.数据库提取每天要复习的单词:一开始懵逼了好久后来才想到在表里加入时间戳属性,用add_date()函数为每个grade的词添加未来不同的复习时间。取出的时候用datediff(day,date,now())函数,取出相隔小于等于0的行(有可能漏了一天没背所以差可能为负数)
4.播放问题。要播放MP3文件一开始不知道怎么弄,网上找了圈导入了jl1.0.1.jar,把里面play()接口重新简单包装了下。
0X03:总体结构与对应的类名

0X04:很多麻烦
1.因为判定逻辑为输入1才会进入验证拼写功能,所以如果输入的是字母就会触发input异常导致会直接进入下一函数。得加上while (!read.hasNextInt())和read.next()配合使用强迫必须输入的是数字。
2.如果对数据库进行数据不变的update(即执行update这条sql语句数据前后一样)时间戳不会变化,这会导致grade为1的复习词时间戳不会在今天的基础上+1而是之前的时间戳上+1。所以将时间戳延长前先要将时间戳设为当前时间
3.数据库driver异常,找了一圈才找到mysql5.5.53对应的包。如果你的sql不是这个版本最好自己百度对应的包。
4.等 等等**
0X05:依旧没解决的麻烦
1.音频播放有时候会放两次....如果是带着耳机的话有时候会没声音。因为可以循环播放也不算大问题就不管了。
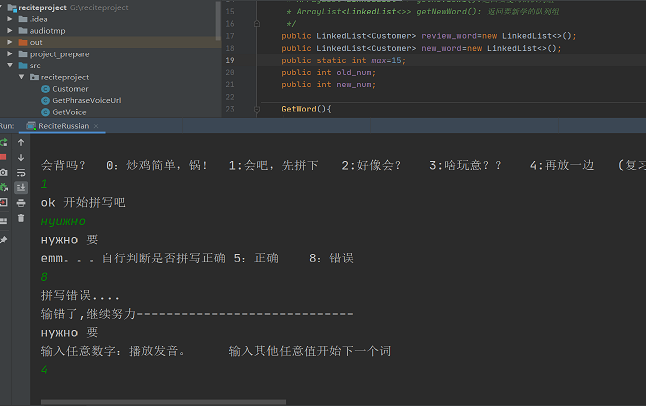
0X06: 结果截图
0X07:改进方向
1.新加一个进程,处理新词语音本地化模块。从而可以一边复习一边自动下载新词语音。不用等爬虫下载了。
2.写个UI做成客户端程序,或者用springboot+vue把程序换成web项目,再买个服务器部署到云端,有钱再说。。。
0X08:代码
链接:https://share.weiyun.com/0FHuKbP4 密码:29p8bq