一、整型
在python3中只有int,包含了long;而python2中有long类型。python2中是没有布尔类型的,它用0表示False,用1表示True。到python3中,把True和False定义成关键字,但他们值还是1和0。可和数字相加。
1. 案例
(1)将i转换为二进制,统计最小有效位数
i = 128
i.bit_length()
结果:128 - 10000000 -> 8
20 - 10100 -> 5
2. 内置type()函数可以查看数据类型
(1)解包操作
a, b, c, d = 10, 5.5, True, 4+3j
>>> <class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
3. isinstance 判断数据类型
a = 111
isinstance(a, True)
>>>True
4. isinstance 和 type()区别
(1)type() 不会认为子类是一种父类类型
(2)isinstance() 会认为子类是一种父类类型
5. isinstance类中使用
>>> class A:
... pass
...
>>> class B(A):
... pass
...
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
二、浮点型
1. 定义
python提供了三种浮点值:内置的 float、complex;标准库得decimal.Decimal类型。float存放双精度浮点数,受精度限制,进行相等性比价不可靠。
科学计数:10 用e代替 1.23e10 0.000012——>1.2e-5。 整数和浮点数在计算机存储方式不同,int永远是精确的
2. 案例
(1)自定义精度,导入标准库
from decimal import *
getcontext()
getcontext().prec = 50
a = Decimal(2) / Decimal(3)
print(a)
结果:
0.66666666666666666666666666666666666666666666666667
三、布尔型
1. 相关类型转换
str => int int(str)
int => str str(int)
int => bool bool(int). 0是False 非0是True
bool => int int(bool) True是1, False是0
str => bool bool(str) 空字符串串是False, 不空是True
bool => str str(bool) 把bool值转换成相应的"值"
2. 总结
(1)想要转化成什么类型就用这个类型括起来
(2)True => 1 | False => 0
(3)可以当做False来用的数据: 0 "" [] {} () None
四、字符串
1. 字符串操作
1. 注意点
字符串进行修改时候, upper/lower/replace 操作后都需要将修改后的值赋值给原始对象,才可以把原来的字符串进行修改;因为字符串是不可变数据类型
2. 相关操作
实例: my_string = 'hellP NiuX Join'
(1)大小写转换
print(my_string)
print(my_string.swapcase())
结果:
hellP NiuX Join
HELLp nIUx jOIN
(2)首字母大写
print(my_string.capitalize())
结果:Hellp niux join
(3)居中空白填充
print(my_string.center(20, '-'))
结果:--hellP NiuX Join---
(4)全部字母大写
print(my_string.upper())
结果:HELLP NIUX JOIN
(5)全部字母小写
print(my_string.lower())
结果:hellp niux join
(6)判断是否全部是大写字母
print(my_string.isupper())
结果:False
(7)判断是否全部是小写字母
print(my_string.islower())
结果:False
(8)每个用(特殊字符或数字)隔开的单词首字母大写
print(my_string.title())
结果:Hellp Niux Join
(9)全部小写字母小写,与lower类似;但一些非英文字符也可变为小写
print(my_string.casefold())
结果:hellp niux join
(10)判断是以xxx结尾的
print(my_string.endswith('Join'))
结果:True
还可以切片,判断从[]1-10)这段里是否以i结尾
my_string.endswith('i', 1,10)
(11)判断是以xxx开头的
print(my_string.startswith('fj'))
结果:False
my_string.startswith('i', 1,10)
(12)判断字符串中是否含有空白; 空白->空白符包含:空格、制表符( )、换行(
)、回车(
)等
a. 如果字符串中只包含空格,则返回True,否则False
b. 实例
str = " "
str.isspace() - True
str = "Run example" - False
c. print ('
'.isspace()) # True
print ('�'.isspace()) # False
print (' a '.isspace()) # False
d. 空字符串不算空白
>>> print("".isspace()) False
(13)判断字符串中是否含有数字
print(my_string.isdigit())
结果:False
(14)判断字符串是否由字母组成;如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
str = "runoob"
print (str.isalpha())
结果:True
str = "Runoob example....wow!!!"
print (str.isalpha())
结果:False
汉字也返回True
>>> Str = '哈哈'
>>> print(Str, Str.isalpha())
>>> True
(15)如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
str = "runoob2016" # 字符串没有空格
print (str.isalnum())
True
str = "www.runoob.com"
print (str.isalnum())
False
(16)判断只包含十进制字符;这种方法只存在于Unicode对象中
str = "runoob2016"
print (str.isdecimal())
False
str = "23443434"
print (str.isdecimal())
True
(17)返回指定长度的字符串,原字符串右对齐,前面填充0
s = '101'
print(s.zfill(8))
结果:00000101
(18)返回指定长度的字符串,原字符串右对齐,前面填充自定义字符
s = '101'
print(s.rjust(8,'+'))
+++++101
(19)返回指定长度的字符串,原字符串左对齐,前面填充自定义字符
s = '101'
print(s.ljust(8,'+'))
101+++++
2. 字符串切片
1. 切片
my_str = "python?伟大的蟒蛇语言"
my_str[0] -> 'p'
my_str[100] -> IndexError: string index out of range
my_str[-1] -> -1表示倒数第一个; 言
my_str[-2] -> -2表示倒数第二个; 语
2. 语法(切片是左闭右开)
str[ start : end : step] # 从start开始截取. 截取到end位置. 但不包括end,step是步长(默认是1:从左往右;-1从右往左)
my_str[0:3] ->不包含索引3的值 'pyt'
my_str[4:] ->表示从索引4-切到最后 'on?伟大的蟒蛇语言'
my_str[-1:-5] -> 空字符串; 原因:这个步长还是 1 说明向有切,但是右边不存在-5
my_str[-1:] -> 同上,步长为 1 只能获取索引 -1 的值 '言'
my_str[-5:] -> 的蟒蛇语言
my_str[:-1] -> 从第一个取到倒数第一个(不包含) 'python?伟大的蟒蛇语'
my_str[:] -> 原样输出
my_str[1:5:2] ->从第一个开始取, 取到第5个,每2个取1个;1:5=> ytho => yh 1, 1+2 'yh'
my_str[:5:2] -> 从头开始到第五个. 每两个取一个 'pto'
my_str[-1:-5:-1] ->步长是-1. 这时就从右往左取值了; '言语蛇蟒'
my_str[-5::2] -> '的蛇言'
my_str[-5::-3] -> 从倒数第5个开始. 到第一个. 每3个取一个, '的?hp'
3. 反转字符串
str_new = '12345'
str_rev = str_new[::-1]
结果: '54321'
3. 字符串关键
1. len()
- 返回对象(字符、列表、元组等)长度或项目个数
my_str = "python?伟大的蟒蛇语言"
print(len(my_str))
>>>14
2. find() - 找不到返回 -1
- 检测字符串中是否包含子字符串 str
语法:str.find(str, beg=0, end=len(string))
-str 指定检索的字符串
-beg 开始索引,默认0
-end 结束索引,默认字符串长度
语法:str.rfind(str, beg=0, end=len(string))
-用法与str.find一致,这个得到的是结束的(最大的)索引值
(1) 案例
my_str = "Great minds have purpose,others have wishes minds"
print(my_str.find('minds'))
结果: 6 (返回字符串中第一个被找到字符串的第一个元素索引)
print(my_str.find('a', 5, 10)) # 从5-10元素开始查a; -1
print(my_str.rfind('minds',1)) # 从索引1->末尾 显示最后一个字符串的第一个元素索引 46
3. index() - 找不到报错
- 检查字符串中是否包含子字符串 str
语法:str.index(str, beg=0, end=len(string))
- 找不到抛出异常:ValueError: substring not found
my_str.index('english')
4. strip() - 默认去除空白
空格
- 移除字符串头尾指定的字符(默认为空格)或字符序列;注意,该方法只能删除开头或是结尾的字符,不能删除中间部分的字符;strip() 处理的时候,如果不带参数,默认是清除两边的空白符
(1)案例
my_str = " hello "
print(my_str.strip()) -> 'hello'
my_str = "+++hel+++lo+++"
print(my_str.strip('+')) -> 'hel+++lo'
addr = '123@163.com'
addr1 = addr.strip('12')
解析:以上例子因为 1 在 123@163.com 的左边第一个,所以删除了继续判断,2 也存在,所以也删除。
结果为:3@163.com
addr = '123@163.com'
addr1 = addr.strip('23')
解析:此时 2 不是第一个字符,所以无法继续
结果为:123@163.com
s2 = '*f*jei%'
print(s2.strip('*%'))
解析:从左侧检索* 在'*%'中删.中间跳过;右侧% 也在'*%'中删
s2.lstrip('*') # f*jei%
s2.rstrip('%') # *f*jei
5. count()
- 统计字符串中某个字符出现的次数
语法:str.count(sub, start= 0,end=len(string))
(1)案例
my_str = 'www.runoob.com'
print(my_str.count('o')) -> 3
my_str = 'www.runoob.com'
print(my_str.count('run')) -> 1; 它是以 'run'整体去查询
6. replace()
-把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次
语法:str.replace(old, new[, max])
-返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次
-old -- 将被替换的子字符串。
-new -- 新字符串,用于替换old子字符串。
-max -- 可选字符串, 替换不超过 max 次
(1) 案例
str = "www.w3cschool.cc"
print ("菜鸟教程旧地址:", str)
print ("菜鸟教程新地址:", str.replace("w3cschool.cc", "runoob.com"))
str = "this is string example is ....wow!!!"
print(str.replace("is", "was")) # 不加参数,全部替换
print (str.replace("is", "was", 2)) # 替换前两个
/结果:
菜鸟教程旧地址: www.w3cschool.cc
菜鸟教程新地址: www.runoob.com
thwas was string example was ....wow!!!
thwas was string example....wow!!!
(2)去除字符串中的全部空白
s.replace( ' ', '' )
7. split() - 获得的是一个列表
split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串;Python split() 方法通过指定分隔符对字符串进行分割并返回一个列表,默认分隔符为所有空字符,包括空格/换行/制表符
语法:Str.split([sep=None][,count=S.count(sep)])
-sep -- 可选参数,指定的分隔符,默认为所有的空字符,包括空格、换行(
)、制表符( )等
-count -- 可选参数,分割次数,默认为分隔符在字符串中出现的总次数
-返回分割后的字符串列表
(1) 案例
st0= ' song huan gong '
print(st0.split()) -> ['song', 'huan', 'gong']
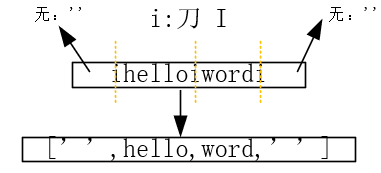
st0= 'ihelloiwordi'
解析:分隔符 i 在字符串中出现3次,ps:也就是i是刀切3次蛋糕,形成4个部分,左右没有字符以''表示
print(st0.count('i')) -> 3
print(st0.split('i')) -> ['', 'hello', 'word', '']
s = '<a href="www.test.com">test</a>'
s2 = s.split('"')[1]
解析:以"为分隔符取,形成的列表取出索引为1的值,就取出了'www.test.com'
print(s2) -> www.test.com
8. join() - 拼接列表/元组可得到字符串
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串
语法:str.join(sequence)
(1) 案例
s1 = '-'
lst = ['a','b']
s_new = s1.join(lst) ->a-b
s1 = ''
lst = ['a','b']
s_new = s1.join(lst) ->ab
4. 字符串格式化
1. format
格式化输出,基本语法是通过 {} 和 : 来代替以前的 % ,format () 函数可以接受不限个参数,位置可以不按顺序
(1)s ='我叫{},今年{},爱好{},再说一下我叫{}'.format('太白',36,'女','太白')
(2)s ='我叫{0},今年{1},爱好{2},再说一下我叫{0}'.format('太白',36,'女')
(3)name = input("please input your name:")
s ='我叫{name},今年{age},爱好{hobby},再说一下我叫{name}'.format(name = name,age = 36,hobby = '女')
2. % - %s,匹配一切类型
s = 'hello'
x = 5
"The length of %s is %d" % (s,x)
s = "I'm%s,I am %d"%{'name' = 'libai', 'age' = 19}
3. f'hello'
name = python
str_new = f"hello {python}"
5. 字符串编码
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
1. bytes.decode()
decode() 方法以指定的编码格式解码 bytes 对象.默认编码为 'utf-8'
(1)语法
bytes.decode(encoding="utf-8", errors="strict")
(2)参数
-encoding -- 要使用的编码,如"UTF-8"
-errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。
其他可能的值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
(3)案例
str = "菜鸟教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str) -> 菜鸟教程
print("UTF-8 编码:", str_utf8)
>>>UTF-8 编码: b'xe8x8fx9cxe9xb8x9fxe6x95x99xe7xa8x8b'
print("GBK 编码:", str_gbk)
>>>GBK 编码: b'xb2xcbxc4xf1xbdxccxb3xcc'
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
>>>UTF-8 解码: 菜鸟教程
print("GBK 解码:", str_gbk.decode('GBK','strict'))
>>>GBK 解码: 菜鸟教程
2.str.encode()
encode() 方法以指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案
(1)语法
str.encode(encoding='UTF-8',errors='strict')
(2)参数
-encoding -- 要使用的编码,如: UTF-8
(3)案例
str = "菜鸟教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str) -> 菜鸟教程
print("UTF-8 编码:", str_utf8)
>>>UTF-8 编码: b'xe8x8fx9cxe9xb8x9fxe6x95x99xe7xa8x8b'
print("GBK 编码:", str_gbk)
>>>GBK 编码: b'xb2xcbxc4xf1xbdxccxb3xcc'
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
>>>UTF-8 解码: 菜鸟教程
print("GBK 解码:", str_gbk.decode('GBK','strict'))
>>>GBK 解码: 菜鸟教程
6. 字符串进制转换
1. 进制转换
>>> num=10
>>> print('十六进制:%#x' % num) #使用%x将十进制num格式化为十六进制
十六进制:0xa
>>> print('二进制:', bin(num)) #使用bin将十进制num格式化为二进制
二进制: 0b1010
>>> print('八进制:%#o' % num) #使用%o将十进制num格式化为八进制
八进制:0o12
2. 上面使用格式化符号进行进制转换中,多加入了一个#号,目的是在转换结果头部显示当前进制类型,如不需要,可将#号去除
>>> print('八进制:%o' % num)
八进制:12
>>> print('十六进制:%x' % num)
十六进制:a
3. 字符串分割 - partition()
s1 = "I'm a good sutdent." # 以'good'为分割符,返回头、分割符、尾三部分
("I'm a ", 'good', ' sutdent.')
4. 统计个数,返回字典类型
from collections import Counter
Var2 = "1987262819009787718192084951"
print (Counter(Var2))
Counter({'1': 5, '9': 5, '8': 5, '7': 4, '2': 3, '0': 3, '6': 1, '4': 1, '5': 1})
5. ip掩码换算
b = '1'
bs_len = len(b)
while bs_len < 9:
#global b
b_b = b.ljust(8,'0')
d = int(b_b,2)
print('二进制 %s 相当于十进制 %s' %(b_b,d))
b = b +"1"
bs_len = len(b)
二进制 10000000 相当于十进制 128
...
6. 字符串<->列表
(1)字符串->列表
var='菜鸟教程'
list = []
list = [i for i in var]
(2)列表->字符串
var1 = ' ,'.join(list)
(3)字符串->元组
tup = tuple(var)