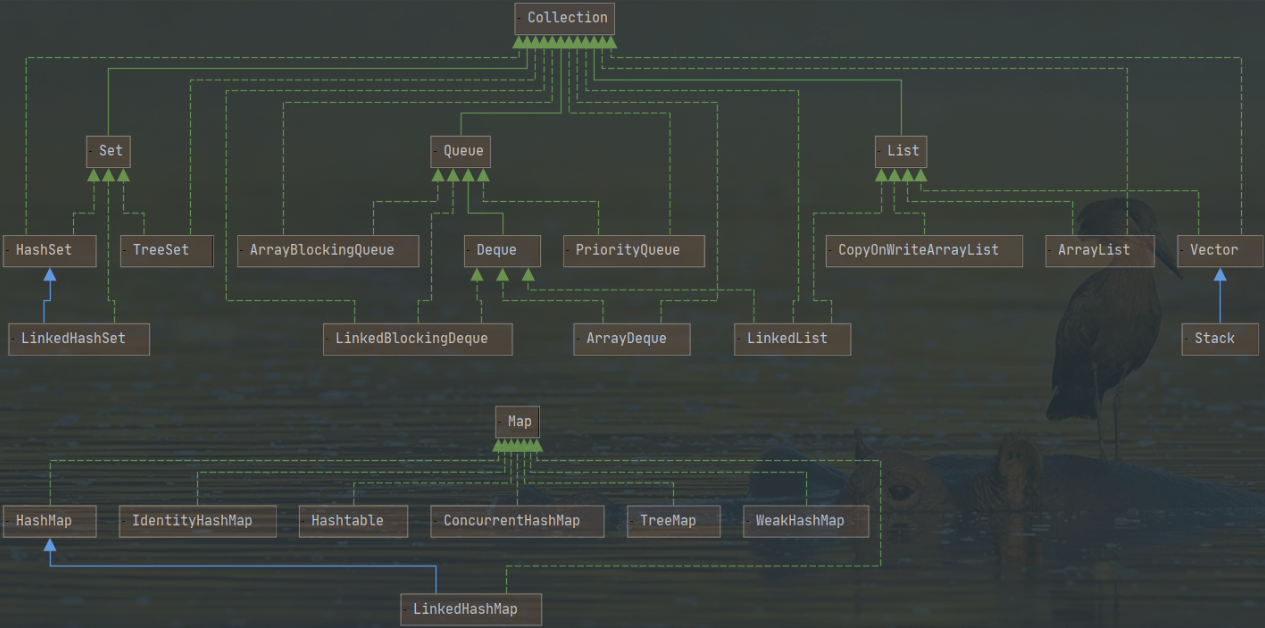
总体架构图
本节内容架构要掌握,总体来看这就是架构图,其中实线是继承部分,虚线是实现部分
为了节省时间和空间,API只是简单的过一遍,更重要的还是在于源码分析
Collection
- 位于
Java.util包下- Collection,单列集合,类似数组一般,不过集合的长度是可以动态扩展的
API
-
增
boolean add(E e);//将元素添加到集合中 boolean addAll(Collection<? extends E> c);//将指定集合中的所有元素添加到集合中 -
删
boolean remove(Object o);//删除指定元素 boolean removeAll(Collection<?> c);//删除所有指定集合中包含的元素 default boolean removeIf(Predicate<? super E> filter);//删除所有满足指定正则的元素 void clear();//清空集合内容 -
改
-
查
int size();//返回集合大小 Iterator<E> iterator();//迭代器,用于遍历 -
断言
boolean isEmpty();//是否为空 boolean contains(Object o);//是否包含指定内容 boolean containsAll(Collection<?> c);//是否包含指定集合中的全部内容 boolean retainAll(Collection<?> c);//集合保留与指定集合相同的内容(保留交集)
boolean equals(Object o);//是否和指定元素相等
- 转换
```java
Object[] toArray();//转为Object数组
<T> T[] toArray(T[] a);//转换为你输入数组类型的数组
Stream<E> stream();//转换为流
//一个新的Collection
Collection<Integer> list = new ArrayList();
//赋值10个
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//假如不为空
if (!list.isEmpty()) {
//转换为Object数组
Object[] objects = list.toArray();
//输出Object数组:12345678910
Arrays.stream(objects).forEach(System.out::print);
//换行
System.out.println();
//转换为指定类型的数组
Integer[] array = list.toArray(new Integer[0]);
//输出:12345678910
Arrays.stream(array).forEach(System.out::print);
}
//换行
System.out.println();
Collection<Integer> list2 = new ArrayList();
//根据指定的集合数据,添加到集合中
list2.addAll(list);
list2.add(11);
//转换为stream流,输出:1234567891011
list2.stream().forEach(System.out::print);
//删除
list.remove(9);
//保留交集
list2.retainAll(list);
System.out.println();
//1234567810
list2.stream().forEach(System.out::print);
//清空
list2.clear();
List
List介绍
- List最大的特点就是有序,可重复
- 有序:指的是进入和输出的顺序是确定的
- 可重复:List中的元素可以有多个重复值
API
-
增
boolean add(E e);//将元素添加到集合中 boolean addAll(Collection<? extends E> c);//将指定集合中的所有元素添加到集合中 boolean addAll(int index, Collection<? extends E> c);//将指定集合从集合的指定位置插入进去 void add(int index, E element);//根据指定的下标添加值到对应的位置中 -
删
boolean remove(Object o);//删除指定元素 boolean removeAll(Collection<?> c);//删除所有指定集合中包含的元素 default boolean removeIf(Predicate<? super E> filter);//删除所有满足指定正则的元素 void clear();//清空集合内容 E remove(int index);//根据指定的下标删除对应的内容 -
改
void replaceAll(UnaryOperator<E> operator);//用函数式接口的返回值替代原来的值 void sort(Comparator<? super E> c);//排序,使用Comparator进行排序 E set(int index, E element);//根据指定的下标将值修改为指定的内容 -
查
int size();//返回集合大小 Iterator<E> iterator();//迭代器,用于遍历 E get(int index);//根据指定下标查询值 int indexOf(Object o);//返回对象在集合中首次出现的位置 int lastIndexOf(Object o);//返回对象在集合中最后一次出现的位置 ListIterator<E> listIterator();//迭代器的升级,不仅可以从前向后遍历,也可以从后向前遍历,还可以自由增删元素 -
断言
boolean isEmpty();//是否为空 boolean contains(Object o);//是否包含指定内容 boolean containsAll(Collection<?> c);//是否包含指定集合中的全部内容 boolean retainAll(Collection<?> c);//集合保留与指定集合相同的内容(保留交集) boolean equals(Object o);//是否和指定元素相等 -
转换
Object[] toArray();//转为Object数组 <T> T[] toArray(T[] a);//转换为你输入数组类型的数组 Stream<E> stream();//转换为流 List<E> subList(int fromIndex, int toIndex);//将指定索引范围(不包含右边)转换为新的List,相当于截取一小部分出来
- 不难看到,我其实是先将Collection中的方法和List中新增的方法使用回车进行了隔离
- 我们其实不难看出来,这些新增加的方法都是一些对索引的操作,或者说是只能由索引带来的操作
Collection<Integer> collection = new ArrayList();
for (int i = 1; i <= 10; i++) {
collection.add(i);
}
List<Integer> list = new ArrayList<>();
//给指定的位置添加内容
list.add(0, 0);
//从集合的指定位置开始插入指定集合的内容
list.addAll(0, collection);
//输出:123456789100
list.stream().forEach(System.out::print);
System.out.println();
//将所有数据替换为所有数据-1
list.replaceAll(integer -> integer - 1);
list.stream().forEach(System.out::print);
System.out.println();
//删除指定位置的元素
list.remove(10);
//转为List的迭代器,可以向前和向后遍历:0123456789
ListIterator<Integer> iterator = list.listIterator();
while (iterator.hasNext()) {
System.out.print(iterator.next());
}
System.out.println();
List<Integer> subList = list.subList(0, 1);
//0
subList.forEach(System.out::print);
ArrayList
特点
- ArrayList底层是使用数组来存储的数据结构,是数组列表
- ArrayList只能装载引用类型,也就是说当我们使用基本类型的时候只能使用它的包装类
- 因为基于数组,所以ArrayList查找快,增删慢
- ArrayList是非线程安全的
深入理解
构造
- 首先我们来看一下它的构造方法
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList() {
//无参构造方法,直接让方法为默认的对象数组,默认的对象集合是一个空的对象数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//指定内容的构造方法
public ArrayList(int initialCapacity) {
//假如容量>0,那么让elementData缓冲数组为新的对象数组,新的对象数组的容量为指定的容量
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//假如容量==0,那么就和无参构造方法一样
this.elementData = EMPTY_ELEMENTDATA;
} else {
//假如容量<0,直接抛异常
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}
//指定集合的构造方法
public ArrayList(Collection<? extends E> c) {
//collection.toArray(),来自Collection集合,具体的作用是将集合转换为数组,这里的缓冲数组就成为了转换的数组
elementData = c.toArray();
//假如长度不为0
if ((size = elementData.length) != 0) {
//假如缓冲数组的类别和Object[]的类别不同,那么直接利用Arrays.copy方法复制过去
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
//假如长度为0,那么还是和无参构造方法一样
this.elementData = EMPTY_ELEMENTDATA;
}
}
我们可以看到,无参构造,集合长度为0的构造,指定长度为0的构造其实在这个时候并没有指定集合的容量大小,只是创建了
- 构造方法的BUG
我们看指定长度的构造方法,当我们指定了长度的构造方法之后,但是size没有改变,size可以说明,就是ArrayList的大小。
ArrayList arrayList = new ArrayList(10);
//0
System.out.println(arrayList.size());
添加
- 接下来我们来看一下增加的方法
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//假如是空的,那么就返回 DEFAULT_CAPACITY和指定的数据的较大值,DEFAULT_CAPACITY为10
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
/*
这是一个比较重要的变量,作用是来记录对象的修改次数,当增删改的时候我们一定会看到这个对象
在单线程的条件下,这个对象貌似没有什么用,但是在多线程的情况下可以检测这个变量抛出异常,确保数据安全性
*/
modCount++;
/*
我们刚才已经知道,缓冲数组和我们的集合一样的
那么在这里就是判断传递过来的数值如果比我们的数组长度大,那么就要进行扩容
*/
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
从
calculateCapacity我们可以看到,初始值假如小于10的话,按照10来,假如比10大,那么就按照指定的值
//重点的扩容方法
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//位运算没忘记吧,右移一位就相当于除2,这里也就相当于新的数组容量大小为老的容量的1.5倍,也就是扩容1.5倍数
int newCapacity = oldCapacity + (oldCapacity >> 1);
//假如新的容量值还比指定的容量值要小,那么新的容量值就是指定的容量值,这个情况一般在自己指定大小的时候会用到
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//经历了以上的方法,假如新的容量值竟然要比最大值还要大,将会导致数据溢出,那么直接使用解决策略
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//将旧的数组复制到新的数组中,旧的数组不要了,作为垃圾回收
elementData = Arrays.copyOf(elementData, newCapacity);
}
//ArrayList的溢出解决策略
private static int hugeCapacity(int minCapacity) {
//当值小于0,直接抛出异常
if (minCapacity < 0) throw new OutOfMemoryError();
//假如数据溢出,直接为Integer的最大值,没有溢出就是为设定的最大值,设定的最大值为MAX_ARRAY_SIZE=Integer减8
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
public boolean add(E e) {
//看看是不是要扩容
ensureCapacityInternal(size + 1);
//数组的下一个值增加
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
//超范围直接抛异常
rangeCheckForAdd(index);
//看看是不是要扩容
ensureCapacityInternal(size + 1);
//System.arraycopy(上一个数组,上个数组的起始位置,目标数组,目标数组的起始位置,复制的长度);
System.arraycopy(elementData, index, elementData, index + 1,size - index);
//目标位置
elementData[index] = element;
//size,ArrayList的大小
size++;
}
这就是底层,一般来讲数组的复制最终都会跑到这个
System.arraycopy()下
public boolean addAll(Collection<? extends E> c) {
//转数组
Object[] a = c.toArray();
//得到数组长度
int numNew = a.length;
//判定,size(ArrayList)默认的话是0,但是如果之前加过会改变
ensureCapacityInternal(size + numNew);
//再一次拷贝
System.arraycopy(a, 0, elementData, size, numNew);
//size更改
size += numNew;
//只要加入的集合长度不为0,就是真的
return numNew != 0;
}
//指定位置,添加所有
public boolean addAll(int index, Collection<? extends E> c) {
//超范围直接抛异常
rangeCheckForAdd(index);
//转数组
Object[] a = c.toArray();
//获取长度
int numNew = a.length;
//是否要扩容
ensureCapacityInternal(size + numNew);
//集合长度-目标位置,获得的结果就是长度
int numMoved = size - index;
//假如长度>0
if (numMoved > 0)
//最终要到数组的拷贝,这里是先把原数组进行拷贝,中间现在空出了一部分
System.arraycopy(elementData, index, elementData, index + numNew,numMoved);
//把空出来的部分补上
System.arraycopy(a, 0, elementData, index, numNew);
//ArrayList的长度更改
size += numNew;
//返回结果
return numNew != 0;
}
删除
学习了添加,其实删除也是一样的,底层都是调用了数组的拷贝方法
其他
如果我要使用线程安全的集合应该怎么办
两种方法,一个是使用Vector,一个是使用Collections.synchronizedList把集合包装成一个线程安全的数组容器。
这两种方法都是将所有的方法全都加上一层synchronized
为啥默认起始容量为10
没有什么必须,可能就是当时程序员头脑一排得出来的
删除
删除的时候并不会删除容量,如果要移除多余的容量就要使用方法trimToSize
public void trimToSize() {
//修改次数增加
modCount++;
//假如集合的容量比预计的小,那么缩小(重新拷贝)
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
API使用
属于List的方法
- 添加
| 方法 | 说明 |
|---|---|
boolean add(E) |
添加 |
void add(int,E) |
指定位置添加 |
boolean addAll(Collection<? extends E>) |
添加所有指定集合中的元素 |
boolean addAll(int,Collection<? extends E>) |
指定位置添加所有集合中的元素 |
- 查询
| 方法 | 说明 |
|---|---|
E get(int) |
获得 |
int indexOf(Object) |
查询指定对象在集合中的位置 |
Iterator<E> iterator() |
迭代器 |
ListIterator<E> listIterator() |
获得列表迭代器 |
int lastIndexOf(Object) |
获得指定元素在集合中最后出现的位置 |
int size() |
获取集合的长度 |
列表迭代器和迭代器不同的一点是:列表迭代器可以从后向前遍历,而迭代器只能从前向后遍历
- 删除
| 方法 | 说明 |
|---|---|
void clear() |
清空 |
E remove() |
删除最后一个元素 |
boolean remove(Object o) |
移除指定的元素 |
boolean removeAll(Collection<?> c) |
移除和指定集合产生交集的元素 |
boolean retainAll(Collection<?> c) |
只保留和指定集合产生交集的元素 |
- 修改
| 方法 | 说明 |
|---|---|
E set(int index, E element) |
直接设置指定位置的值 |
- 断言
| 方法 | 说明 |
|---|---|
boolean contains(Object) |
是否包含 |
- 排序
| 方法 | 说明 |
|---|---|
sort(Comparator<? super E> c) |
指定排序规则排序 |
- 转换
| 方法 | 说明 |
|---|---|
List<E> subList(int fromIndex, int toIndex) |
截取指定范围的元素形成一个新的List,不包括右边的范围 |
Object[] toArray() |
转换为Object数组,底层是System.arraycopy |
T[] toArray(T[] a) |
转换为指定类型的数组 |
属于Object的方法
- 转换
| 方法 | 说明 |
|---|---|
Object clone() |
浅克隆 |
属于AbstractList的方法
- 删除
| 方法 | 说明 |
|---|---|
void removeRange(int fromIndex, int toIndex) |
指定范围删除 |
属于Iterable的方法
- 查询
| 方法 | 说明 |
|---|---|
void forEach(Consumer<? super E> action) |
遍历 |
属于Collection的方法
- 删除
| 方法 | 说明 |
|---|---|
boolean removeIf(Predicate<? super E> filter) |
根据正则删除 |
Vector
深入理解
线程安全
Vector基本和ArrayList差不多,基本就是复制版的ArrayList,但是它的方法都是线程安全的
比如给你们看一个添加操作:
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}
扩容
扩容的话和ArrayList还是有些区别的
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//capacityIncrement:扩容增量,有一个构造方法可以指定,假如扩容增量>0就用扩容增量,没有就扩容一倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
扩容增量默认1倍和同步方法的出现导致Vector性能比不上ArrayList,但是在多线程方面是比ArrayList安全的
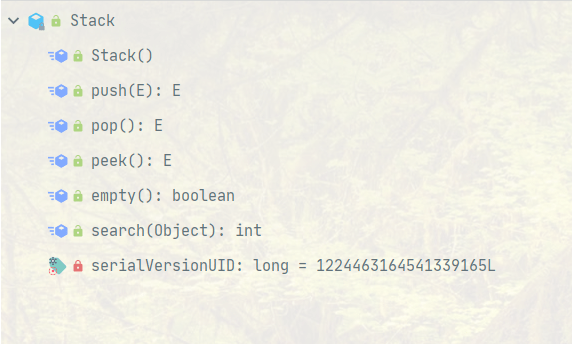
Stack
class Stack<E> extends Vector<E>
首先看这个源码,Stack继承Vector,说明Vector有的Stack也有
然后看方法
标准的栈结构,入栈,出栈
LinkedList
链表
在讲解LinkedList之前,需要和各位先讲解一下链表的内容
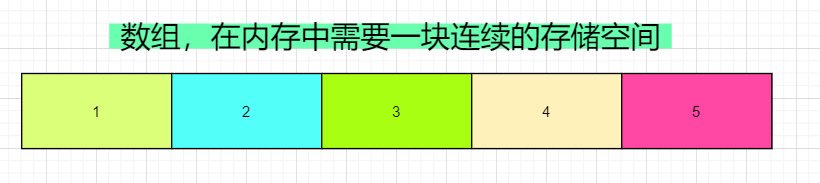
数组
我们先看数组,我们知道,数组我们之前用过,它在内存中需要的是一块连续的存储空间。
因为这个特点,使得数组出现了索引(下标)这种东西,使得它在进行查找的时候特别高效。
那么假如数组的容量超出了还要增加,就要重新创建一个新的数组用来增加
数组的删除有时候不仅仅是单纯的删除,基本类型不可以为null,那么就必须重新创建一个新的数组进行删除
如果是集合必须为引用类型的话,删除没有这么多讲究,但是如果调用
trimToSize也是要进行数组的重新部署
链表
作为数据结构之一的链表,有着明确的分类
假如按照方向分类,分为单向链表和双向链表
假如按照是否循环分类,分为普通链表和循环链表
| 单向链表 | 双向链表 | |
|---|---|---|
| 普通链表 | 单向链表 | 双向链表 |
| 循环链表 | 单向循环链表 | 双向循环链表 |
下面我们就依次来介绍一下
单向链表
作为最为普通的链表,用来介绍一下概念再好不过了
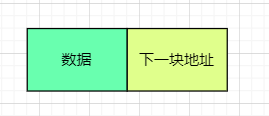
最普通的链表的一块节点的结构是这样的:
这个节点由两部分组成:数据区,地址区。
其中数据区域负责存放数据,而地址区负责存放下一块节点在内存中的地址
因为链表的这种结构,导致和链表和数组不同的特性:
- 它只需要一块地址空间,是否连续是无所谓的。这保证了空间更高效的利用率。
- 因为存放着一块地址空间,所以每一个节点的容量要比数组的每一个节点大一些。
当然了,凡事有利有弊,解决了这个问题,我们就会出现新的问题,我们只需要在不同情况下确保最优选择即可
那么链表的具体结构图是这样的:
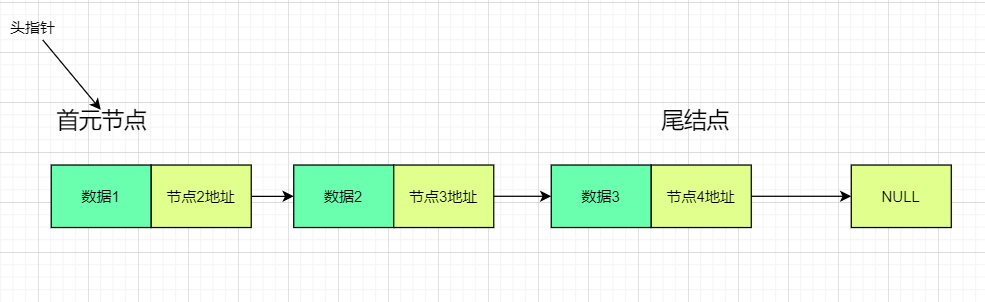
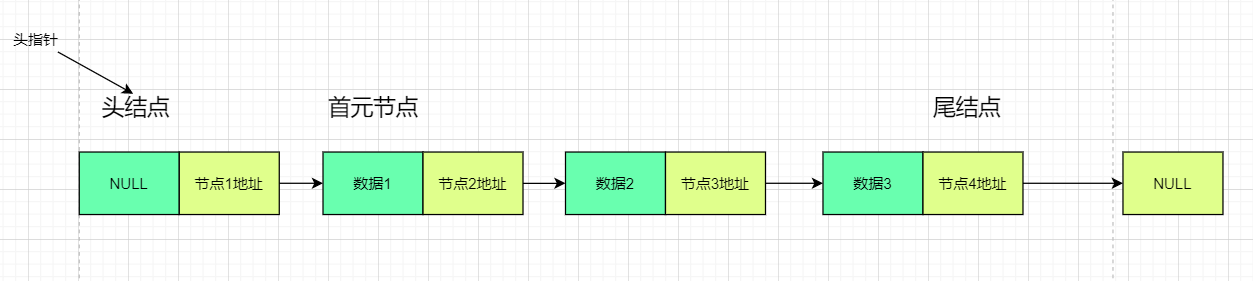
为什么有两张图呢,因为这是要分情况的
首先解释一下头结点和首元结点(首结点)和头指针
头指针:指向第一个结点
首元结点:第一个存有有效值的结点
头结点:头结点可以设立可以不设立,设立的时候地址就指向结点1,没有结点1就指向NULL
为什么要设立头结点
- 有了头结点之后,插入和删除操作就和其他的元素一致了
- 一般来说,头结点的名字就是这条链表的名字
不论那张图,都是前一个节点的地址指向后一个节点,最后一个结点指向NULL
双向链表
为了表述方便,我们不使用头结点的结构,并且不再画出指针
它的结构是这样的:
除了刚才单向链表的特性,双向链表还有指向上一个结点地址的特点
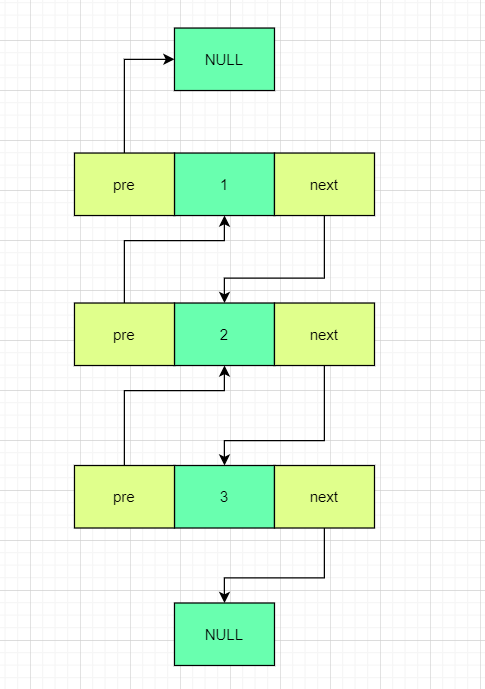
单向循环链表
简单来说,就是构成了一个圆环,让最后一个指针不再指向NULL而是指向第一个结点
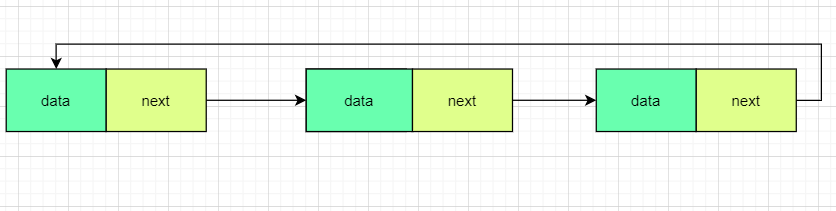
双向循环链表
我想,这个结构应该也很容易理解,第一个结点前一个是最后一个结点,最后一个结点的下一个是第一个结点
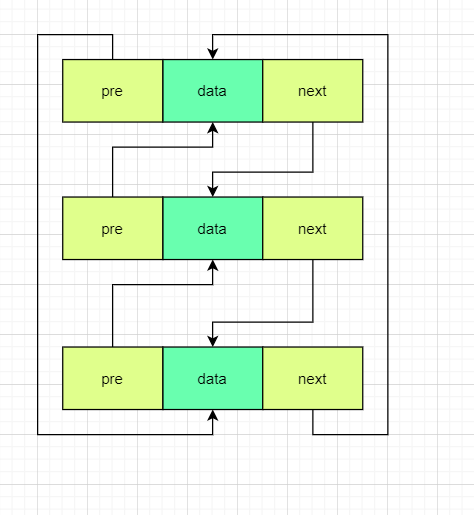
深入理解
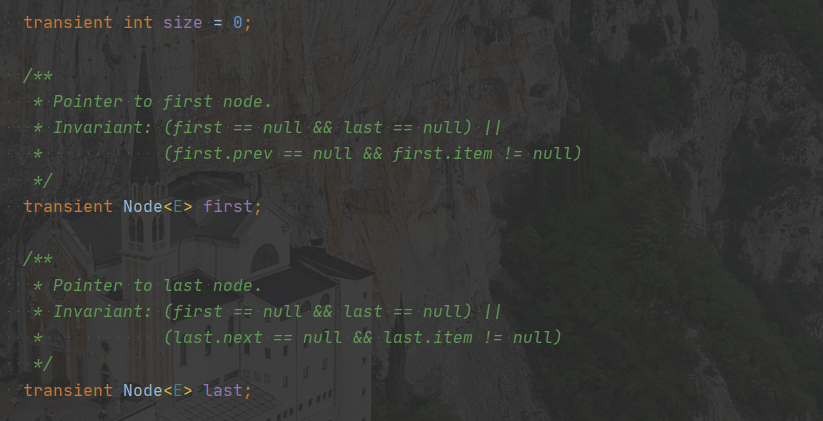
首先看一下字段
没错,就这三个
第一个很容易理解,长度
第二个和第三个我们看注释:一个是始终指向头结点,一个始终指向尾结点
Node
我们接下来看看Node
//Node,静态内部类,其中有几个属性
private static class Node<E> {
//值
E item;
//指向下一个节点
Node<E> next;
//指向上一个结点
Node<E> prev;
//构造器:上一个结点,值,下一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
从这个结点中我们就可以看到,Node,双向链表
为什么要先讲这个呢,因为这个是LinkedList的基础
first和last
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
看源码非常重要的一点就是看注释
如果单看代码你可能会对这两个代码一头雾水,但是如果看注释你就非常清除
first永远指向第一个节点,last永远指向最后一个节点
构造方法
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
有参无参的构造方法是差不多的,有参的是先调用无参的,然后再调用
addAll方法但是我们看到addAll里面又调用了一个新的addAll,老套娃了
检查异常
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
这个主要是用来检查异常的,看到这里没懂不要紧,往后看
获取
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
看到这是不是懂了,用来检查异常的,用到了刚才的检查异常方法
Node<E> node(int index) {
//假如传入的值小于size/2,也就是说假如传入的值小于链表的一半
if (index < (size >> 1)) {
//新建一个节点,让这个节点为开始节点
Node<E> x = first;
//进行循环,从头开始遍历,一直到指定的位置
for (int i = 0; i < index; i++)
//直到遍历到最后
x = x.next;
return x;
} else {
//假如传入的值比size/2大,也就是说传入的值大于链表的一半,从尾部开始遍历
Node<E> x = last;
//从尾部开始向前遍历,一直到指定的值
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这个方法注释写的很清楚:返回指定元素索引处的(非空)节点
那么我们之前在讲数据结构的时候曾经讲过,链表在查找数据的时候是非常慢的,必须从一端开始查
可能之前在看图的时候没有感觉,但是是不是一看到代码立刻就有感觉了
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
前面的都明白了,这个代码就没什么好讲的了
添加
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
检查异常用的,查看传过来的数值是否>=0并且<=size(链表长度)否则直接抛出异常
- 向后添加
public boolean add(E e) {
linkLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
上面这两个是add和addLast,其实我们可以看到最终调用linkLast,向链表最后添加数据
void linkLast(E e) {
//新建一个节点,让这个节点地址指向最后的节点
final Node<E> l = last;
//新建一个新的节点,这个节点的前一个节点指向刚才的最后的节点,值为e,后一个地址指向null
final Node<E> newNode = new Node<>(l, e, null);
//last节点永远指向最后的节点
last = newNode;
//假如新的节点为null,这也是只有一种情况会出现:刚刚创建节点的时候
if (l == null)
//让first节点为新的节点
first = newNode;
else
//在一般情况下,也就是插入的情况下,刚才的最后的节点的下一个地址指向新的最后的节点
l.next = newNode;
//链表长度+1
size++;
//修改次数+1
modCount++;
}
需要修改次数,因为这样可以保证在并发情况下数据安全
- 向前添加
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
向前添加,套路基本和向后添加差不多,不BB了
- 添加所有
public boolean addAll(int index, Collection<? extends E> c) {
//上面的检查异常用的方法,超过了范围直接抛出越界
checkPositionIndex(index);
//首先将集合转成数组
Object[] a = c.toArray();
//获取集合的长度
int numNew = a.length;
//假如集合没有长度,也就是没有集合内容,直接返回false
if (numNew == 0)
return false;
//定义两个临时节点
Node<E> pred, succ;
/*
假如指定的索引位置等于链表的长度,也就是直接向链表最后添加
注意了,这个非常秒
因为 链表长度 = 最终索引+1,而现在当链表长度=索引位置
而只有一种情况,那就是向链表的最后添加内容,当然了,在初始化添加的时候也是一样,都是向链表最后添加内容
*/
if (index == size) {
succ = null;
//pred = last,在这里想一下之前我画的链表结构,现在就是让临时的这个节点赋值为最后一个节点
pred = last;
} else {
//假如指定的索引长度不等于链表的长度,也就是在中间插入或者在开始插入,反正不是在最后插入
//遍历链表,获取到对应位置的节点值
succ = node(index);
//给这个节点赋值为对应位置节点的前一个节点
pred = succ.prev;
}
//接下来对集合转变为的数组进行遍历,然后进行依次的添加操作
for (Object o : a) {
//这个注解是忽略警告的,后面学到注解再来讲
@SuppressWarnings("unchecked")
//这句简单,无非是弄一个临时变量然后赋值
E e = (E) o;
//定义一个新的节点,这个节点的前一个节点是我们指定的节点的前一个节点,值为刚才遍历出来的值,后一个节点为null
Node<E> newNode = new Node<>(pred, e, null);
/*
假如前一个节点为null,就让first节点(始终指向开始节点的节点)初始化
这行代码只有一种情况会执行,就是初始化LinkedList的时候
*/
if (pred == null)
//初始化first节点
first = newNode;
else
/*
其他,也是一般情况,让我们刚刚创建的节点接上之前的节点
注意,我们是在for循环中,这句和pred = newNode的操作就是一直创建新的节点
然后我们所在的节点和新创建的节点相连接
*/
pred.next = newNode;
//临时节点为我们刚才创建的节点
pred = newNode;
}
//也就是index=size的情况(最后插入),那么假如succ为null,就说明pred是最后一个节点
if (succ == null) {
//last始终指向最后一个节点
last = pred;
} else {
//假如是在中间插入,就让pred的下一个指针指向succ
pred.next = succ;
//然后succ的上一个指针指向pred
succ.prev = pred;
}
//链表长度增加
size += numNew;
//链表的修改次数增加
modCount++;
return true;
}
这就是上面的那个老套娃的addAll,可以看出来,指定好插入的位置然后将元素全部添加,后端的元素直接往后排
还记得我们说过的链表结构么?这就是了
当然,我带领你们看的基本都是常用的,其他的源码你们自己去看,套路很清楚,只要思路清晰就没有问题
API使用
来自双端队列的操作
- 增
| 方法 | 说明 |
|---|---|
addFirst(E e) |
向头添加 |
addLast(E e) |
向尾添加 |
- 删
| 方法 | 说明 |
|---|---|
E removeFirst() |
检索并删除第一个元素 |
E removeLast() |
检索并删除最后一个元素 |
- 查
| 方法 | 说明 |
|---|---|
E getFirst() |
获取链表头元素 |
E getLast() |
获取链表尾元素 |
E peek() |
检索不删除第一个元素 |
关于双端队列的其他方法确实也有,但是我并不想多bb,因为它们调用的要么向前添加,要么向后添加
来自List的操作
- 增
| 方法 | 说明 |
|---|---|
add(E e) |
向尾添加 |
boolean addAll(Collection<? extends E> c) |
添加指定集合中的所有数据 |
boolean addAll(int index, Collection<? extends E> c) |
向链表的指定位置添加指定集合的所有数据,时间复杂度高 |
add(int index, E element) |
向指定位置添加,时间复杂度高 |
int indexOf(Object o) |
查询元素在链表中的位置,时间复杂度高 |
int lastIndexOf(Object o) |
查询元素在链表中最后出现的位置,时间复杂度高 |
- 删
| 方法 | 说明 |
|---|---|
boolean remove(Object o) |
删除指定元素,要遍历,时间复杂度高 |
void clear() |
清空所有 |
- 改
| 方法 | 说明 |
|---|---|
E set(int index, E element) |
设置指定位置的元素,时间复杂度高 |
- 查
| 方法 | 说明 |
|---|---|
int size() |
获取链表长度 |
E get(int index) |
获取指定位置的元素,时间复杂度高 |
- 断言
| 方法 | 说明 |
|---|---|
boolean contains(Object o) |
链表中是否包含指定元素 |
- 转换
| 方法 | 说明 |
|---|---|
Object[] toArray() |
转为数组 |
T[] toArray(T[] a) |
转为指定类型的数组 |
来自Object的方法
- 转换
| 方法 | 说明 |
|---|---|
Object clone() |
浅克隆 |
CopyOnWriteArrayList
在这里请允许我卖个关子,因为这个东西要到JUC里面去讲
Map
Map介绍
前言
在这里我们可以看到顺序,没有先讲Set,而是直接讲了Map
这个顺序是有理由的,往后看就可以了
Map结构
如果说Collection家族的数据结构还可以让你让你想象一下,那么Map的结构肯定也可以让你脑补一下
简单来讲,Map家族的结构是key-value形式的,这个意思是说一个键对应一个值
这个和Collection不同,Collection是一种值排成了一串,而Map是一一对应。
对于Map,或者你也可以理解为身份证号和名字的对应关系
key是不可以重复的,但是value是可以重复的。这就和身份证号和名字一样
key只能映射到一个值,就像身份证号一样,一次只能映射到一个人身上。
总结起来就是Map的特点
- Map是键值对对象,一个键对应一个值
- 键不可以重复,但是值可以重复
- Map的数据结构与键有关,和值无关
hash,hashcode
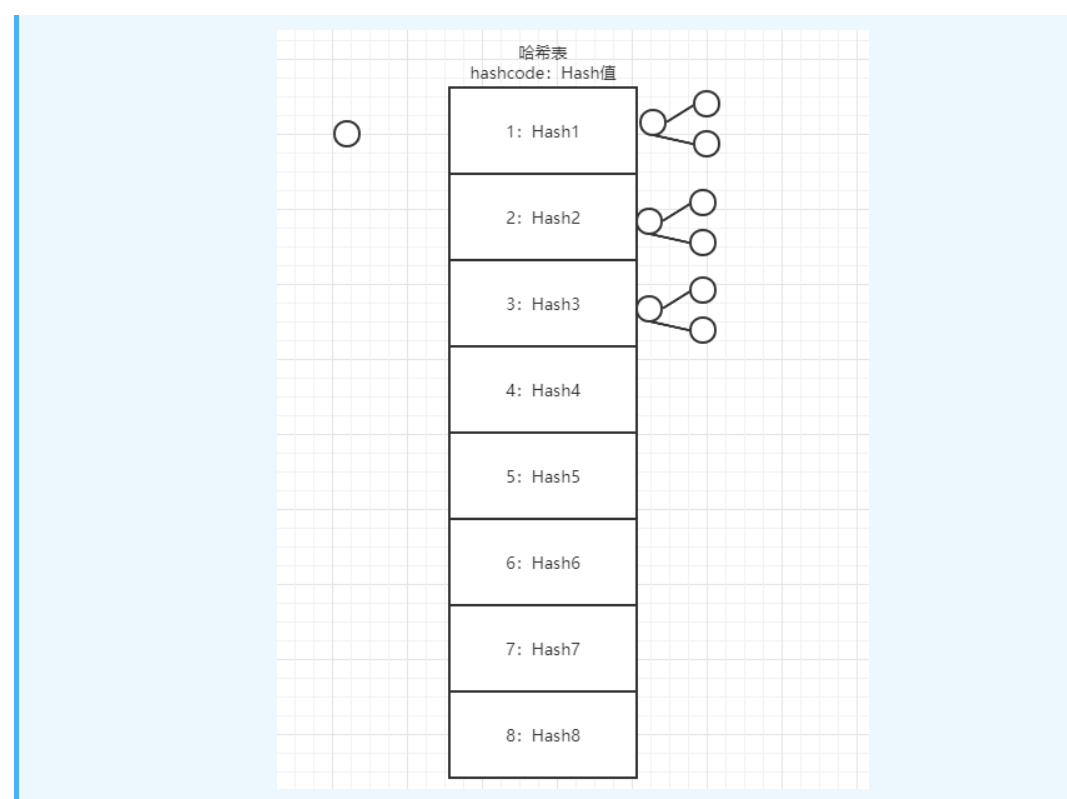
哈希,也叫散列表,其实这个哈希在之前的博客中已经讲过

JDK7的HashMap
简单介绍
首先有一个大体的印象,带着这个印象去看源码会比较好理解:
1、JDK7中的HashMap的结构是使用数组+链表进行实现的
2、当我们使用put操作向HashMap中添加数据的时候,我们添加的是key-value的形式,但其实会将这个key-value封装为一个Entry对象,所以数组中存储的其实是一个引用地址,而不是真正的值
3、HashMap的put操作根据key来取,首先根据key取hashcode,得到hashcode的值,然后将值进行缩减,得到一个小的值,算出要存放的数组的下标,如果数组下标处有元素了,那就使用头插法形成一个链表
而且使用头插法的时候,插入的效率会比较快
4、get操作和put方式有些类似,首先根据key获取hashcode(输入值固定,hashcode固定),然后进行缩减,然后就获得了数组的下标,如果有链表,就进行遍历
当我们回顾ArrayList的添加操作的话,我们可以知道直接让数组的下一个位置增加了,也就是说不论扩容,单纯的增加元素是没什么技术含量的,但是这样的插入方式无疑是最快的。并且ArrayList的取值也不慢,因为直接通过下标来取值。
但是HashMap不可以这样增加数据,我们想象一下,假如HashMap像ArrayList一样,增加数据只是简单地放到下一位,这样插入的效率确实会高很多,但是查询的效率会非常低,因为HashMap的取值是使用key来取而不是下标。
深入理解
- 首先看一下HashMap中比较重要的的属性
//默认数组的初始化容量,16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//HashMap的存放最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//一个空的Entry数组
static final Entry<?,?>[] EMPTY_TABLE = {};
//表示HashMap中的数组,一开始就是一个空数组,是Entry类型
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//HashMap中所有元素的多少
transient int size;
//阈值,根据加载因子算出
int threshold;
//负载因子,这个是到时候用到的负载因子
final float loadFactor;
//HashMap的改变次数,多线程下可以保证安全性
transient int modCount;
//哈希种子
transient int hashSeed = 0;
- 构造方法
public HashMap() {
//传递的参数为:初始化容量大小16,默认负载因子0.75
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity) {
//调用下面的构造方法,传递的参数为:初始化容量大小,默认负载因子0.75
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 不论哪个HashMap,最终都要调用这个构造方法
*
* @param initialCapacity 初始化的容量大小
* @param loadFactor 负载因子
*/
public HashMap(int initialCapacity, float loadFactor) {
//初始化容量<0,直接抛异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始化容量大与最大容量,还是最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子小于0或者负载因子根部不是个数字,也抛异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//负载因子初始化
this.loadFactor = loadFactor;
//阈值初始化为容量大小
threshold = initialCapacity;
//init在HashMap中是空的,但是在LinkedHashMap中是有用的
init();
}
- put方法
/**
* 对HashMap中存值
*
* @param key 键
* @param value 值
* @return null
*/
public V put(K key, V value) {
//假如HashMap中的数组是一个空的数组,说明HashMap还是空的
if (table == EMPTY_TABLE) {
//初始化,传递了阈值进去
inflateTable(threshold);
}
//假如key是null,没有抛异常,这说明HashMap中,key是可以为null的
if (key == null)
return putForNullKey(value);
//返回一个hash值
int hash = hash(key);
/*
拿hash值和数组的下标进行与运算,得到要插入进去的数组下标
这里需要说明一下:当length是一个2的幂次方数时,hash & (length-1)其实就是 hash%length
所以数组的长度必须为2的幂次方
顺便说一下,indexFor里面其实就是返回hash & (length-1),下面就不贴函数了
*/
int i = indexFor(hash, table.length);
/*
循环,从table[i]开始,也就是从新元素要插入数组的索引位置开始
只要要插入数组的索引位置不为空,也就是说只要有这个地方有元素就开始死循环
只要循环一次,链表节点+1
总之,这个for循环就是遍历数组对应位置中的链表用的
*/
for (HashMap.Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
/*
元素的输入相同,hash值就会相同,但是hash值相同,输入不一定相同
但是e.hash==hash,e.key==key,key.equals(k)
这三者加起来就是明明白白地确认输入是相同的
也就是确认这个节点里key是不是一样
*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//新的值替换掉老的值
V oldValue = e.value;
e.value = value;
//这是个空的,LinkedHashMao中用
e.recordAccess(this);
//返回老的值
return oldValue;
}
//也就是说这个for循环其实就干了一件事:替换掉老的值并返回
}
//HashMap的修改数+1,这里需要注意,假如在上面替换掉了老的值,在上面就已经将数据返回了,这里的修改数是不增加的
modCount++;
//那么我们说,假如这个值以前没有增加过,那么就在这里增加一个新的元素
addEntry(hash, key, value, i);
//新的元素,返回的肯定就是null了
return null;
}
总结:put方法做了这么几件事情:
1、判断key是否为null,如果为null那么就将这个值放到固定位置上
2、假如不为null,那么使用key获取到hash值并且使用与操作将值缩减为数组大小范围内的值
3、使用for循环来遍历数组下标中的链表,如果有对应的key,那么新的值覆盖老的值,然后返回老的值。假如没有对应的key,那么modCount+1,并且在链表上插入一个新的Entry
/**
* 将传过来的key进行一个hash运算
*
* @param k HashMap中,传过来的key
* @return 进行完hash运算后的结果
*/
final int hash(Object k) {
//我们的hashSeed,哈希种子默认为0
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
/*
这里使用哈希种子和键的哈希值进行一个异或运算
我们知道,异或运算是相同为0,不同为1
所以在这里进行异或运算的时候h也会进行变化
*/
h ^= k.hashCode();
//然后又进行向右位移,然后进行异或,得到后来的结果
h ^= (h >>> 20) ^ (h >>> 12);
//最后返回的时候继续移动,然后进行异或运算
return h ^ (h >>> 7) ^ (h >>> 4);
}
所以,这里的结果其实不是我们直接调用了hashcode()返回的结果,而是进行运算得到的结果
/**
* HashMap初始化
*
* @param toSize 传递了阈值进来
*/
private void inflateTable(int toSize) {
//求2的幂次方,数组的容量必须是2的幂次方,这个原因在前面讲了
int capacity = roundUpToPowerOf2(toSize);
/*
阈值为
1、容量*负载因子
2、HashMap存放的最大容量+1。
这两个取一个小值,当然一般情况是容量*负载因子
*/
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//对HashMap的数组进行了初始化
table = new HashMap.Entry[capacity];
initHashSeedAsNeeded(capacity);
}
/**
* 寻找一个最近的2的幂次方数,将其转换
*
* @param number 传进来的数字
* @return 2的幂次方数
*/
private static int roundUpToPowerOf2(int number) {
/*
1 0000 0001
2 0000 0010
4 0000 0100
8 0000 1000
16 0001 0000
....
所以规律是:只有bit位置上一个为1的才是2的幂次方数
那么在这里,首先判断是不是大于最大容量
- 大于最大容量,那么就返回最大容量
- 没有大于最大容量,判断传进来的数字是否>1
- 不大于1,返回1
- 大于1,那么进行Integer.highestOneBit((number - 1) << 1)
(number - 1) << 1,这个很有讲究
左移一位,再去调用highestOneBit,因为这个方法的作用是返回小于等于给定数字的最接近的2的幂次方数
而-1就更好了,因为我们以16为例,16-1=15,15进行翻倍是30,然后去调用highestOneBit,得到的结果还是16
假如是highestOneBit(number<<1),16翻倍是32,32然后去调用highestOneBit,得到的结果是32,整整大了一倍
*/
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
/**
* 传进来的数字转换为小于等于我们传进来的数的2的幂次方数
*
* @param i 数字
* @return 小于i的2的幂次方数
*/
public static int highestOneBit(int i) {
/*
比方说我们传了个17进来:0001 0001
0001 0001
>>1 0000 1000
| 0001 1001
>>2 0000 1100
| 0001 1101
>>4 0000 0111
| 0001 1111
>>8 0000 0000
| 0001 1111
....
| 0001 1111
在最后,return的时候,再次右移一位,也就是说
i - (i >>> i)
0001 1111 - 0000 1111 = 0001 0000 = 16
从上面的代码我们可以得到一个规律,我们所在的最高位有一个1,然后我们右移,让我们数字的最高位后面的所有数字都改成1
然后最后一减,最后只剩下了最高位的那个1,这就是2的幂次方,只不过是小于等于我们传进来的数
*/
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
因为int类型是4字节,32个bit位,1+2+4+8+16=32,这样就可以覆盖全部的int
/**
* 假如key是null,同样也能push进去
* @param value 值
* @return
*/
private V putForNullKey(V value) {
/*
hashmap要push一个键为null的Entry,直接就放在了数组第一个位置上
这里对链表进行遍历,替换掉旧数据并返回
*/
for (HashMap.Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//修改次数+1
modCount++;
//假如没有null的键,直接就添加一个新的元素
addEntry(0, null, value, 0);
return null;
}
这里就是具体的,假如传入的key-value中,key为null的解决方式
/**
* 增加元素
*
* @param hash hash值
* @param key 键
* @param value 值
* @param bucketIndex 要插入的数组下标位置
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断HashMap的总元素是不是大于阈值,以及这个数组的位置上不为空的时候,重新进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//进行扩容,我们看到扩容的时候也是扩容为了2*table.length,扩容二倍的原因我们之前已经讲过了,数组容量必须为2的幂次方
resize(2 * table.length);
//重新hash,如果这个键为null,那么就是0
hash = (null != key) ? hash(key) : 0;
//数组索引重新进行运算
bucketIndex = indexFor(hash, table.length);
}
//进行元素的添加
createEntry(hash, key, value, bucketIndex);
}
这里需要注意一点,我们之前都以为只要HashMap的数值长度高于阈值就要扩容,其实不是,其实还有一个条件,就是当前数组的位置不为空的时候才会进行扩容操作
而且我们要注意,size的意思是hashmap中存入了多少数据
/**
* 扩容操作
*
* @param newCapacity 新的数组容量
*/
void resize(int newCapacity) {
//获得老的数组,和老的数组的长度
HashMap.Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//假如老的数组最大长度为HashMap所允许的最大长度,不进行扩容
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//扩容时,定义一个新的数组,新数组的大小为原来数组的二倍
HashMap.Entry[] newTable = new HashMap.Entry[newCapacity];
//进行数据的转移,将原来数组的数据转移到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//重新对阈值进行计算
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 将原数组的所有值都放到新数组中
*
* @param newTable 新数组
* @param rehash 是否要重新进行hash计算,我们大部分情况下是false
*/
void transfer(HashMap.Entry[] newTable, boolean rehash) {
//获得新的容量大小啊
int newCapacity = newTable.length;
//进行数据的转移,我们可以看到一个for嵌套一个while,是双重循环
for (HashMap.Entry<K, V> e : table) {
while (null != e) {
HashMap.Entry<K, V> next = e.next;
//这一步十分重要,是否要进行rehash,我们一般传过来的都是false
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//假如没有进行rehash,那么得到的值只有两个结果:
//1、元素下标还是原来的 2、元素下标改变为原来的下标+原来的数组长度
int i = indexFor(e.hash, newCapacity);
/*
来看一下这个元素节点,JDK7中的HashMap扩容存在很大的问题
首先我们要明确,扩容的目的不仅是为了增大数组的容量,还要让链表的长度变短
简单来说是将一个长长的链表转换为一些短链表,所以它必须对链表进行循环,使用重新添加的方式重新将链表的结点一个一个拿出来,然后存到新数组的下标位置
但是因为头插法的原因,这样就会造成一些问题:
1、扩容之前和扩容之后链表的顺序将会反转,比如原来是1->2->3,扩容后是3->2->1
2、多线程下会造成链表循环指向的问题
所以其实根源是在于链表的头插法,将链表的顺序进行了改变
*/
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
下面的一切结论都是建立在没有进行rehash的情况下: 假如没有进行rehash,那么得到的结果有两种可能: 1、得到的数组下标是原数组的下标 2、得到的数组下表是原数组下标 + 原数组长度 这一段你们可能很难理解,举个例子就行了,比如说: 1)假如我们的hash值为0101 0101 1. 扩容前: 我们要进行indexFor,得到数组的下标 根据key得到的hash值为 0101 0101 数组的长度length为16 进行indexFor运算:0101 0101 & (16-1) 得到结果:0000 0101:数组下标为5 2.扩容后 我们要进行indexFor,得到数组的下标 根据key得到的hash值为 0101 0101 数组的长度length为32 进行indexFor运算:0101 0101 & (32-1) 得到结果:0001 0101:数组下标为5+16,也就是原数组索引+原数组长度 2)假如我们的hash值为0100 0101 1. 扩容前: 我们要进行indexFor,得到数组的下标 根据key得到的hash值为 0100 0101 数组的长度length为16 进行indexFor运算:0101 0101 & (16-1) 得到结果:0000 0101:数组下标为5 2.扩容后 我们要进行indexFor,得到数组的下标 根据key得到的hash值为 0100 0101 数组的长度length为32 进行indexFor运算:0101 0101 & (32-1) 得到结果:0000 0101:数组下标为5,也就是和原数组的下标相同所以其实我们只需要看最高位是0还是1,假如我们扩容的高位为0,那么就是原来的,假如为1,那就是原来下标+原数组长度
/**
* 添加元素
*
* @param hash hash值
* @param key 键
* @param value 值
* @param bucketIndex 要添加的数组下标
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
//下面即将使用头插法
//首先获取到这个数组中存放的地址值,也就是链表的头结点
HashMap.Entry<K, V> e = table[bucketIndex];
/*
数组存放的地址值为一个新的HashMap的Entry,也就是说链表的头结点变为了这个新的节点
同时这里注意,最后传递了原来的头结点,这个最后的e就是节点的next
头插法完成
*/
table[bucketIndex] = new HashMap.Entry<>(hash, key, value, e);
//HashMap总长度+1
size++;
}
可以看到,头插法的效率就是如此之高,如果使用尾插法,那么首先要对这个链表进行一层遍历,然后才能在最后插入数据
但是在HashMap中,只要使用put方法,那么就要对这整个链表进行遍历,那么遍历完成之后肯定会得到尾部的节点,从这一点来看,在HashMap中头插法和尾插法好像没有什么太大的区别
- put总要遍历一遍链表

JDK8的HashMap
红黑树
红黑树是一颗平衡树,它在算法导论中是这样定义的:
1、每一个节点是红色的或者是黑色的
2、根节点(第一个节点)必须是黑的
3、每一个叶子节点必须是黑色的,你可以理解为指向null的都是黑色的
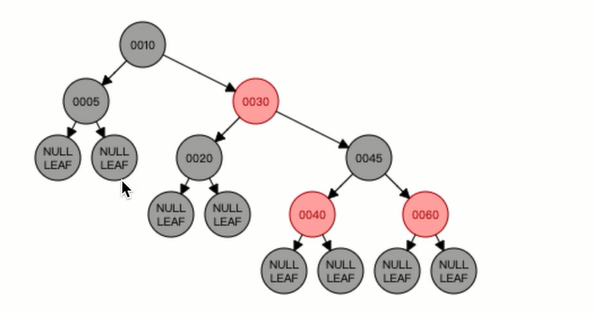
4、不能有两个连续的红节点(红色节点的子节点必须是黑色的)
5、黑节点平衡(从任何一个节点到达它的子孙节点中的任何一个叶子节点中,黑节点拥有相同的数量)
比如在上面这张图中,比如30到叶子节点(NULL)中,都是两个黑色节点
红黑树插入新节点改如何判断是红色还是黑色
第五条是最难遵守的,所以我们默认插入的就是红色的节点,然后判断是否遵守其他的四个定义。
因为我们插入红色节点的时候,没有破坏黑节点平衡这个条件。假如我们插入了黑色的节点,很容易就会破坏黑节点平衡这个条件。
红黑树的左旋和右旋
平衡树想要平衡,需要旋转。红黑树就是一颗典型的平衡树,所以它也是需要旋转的。
举个例子:
现在有一颗红黑树(没有画叶子节点):
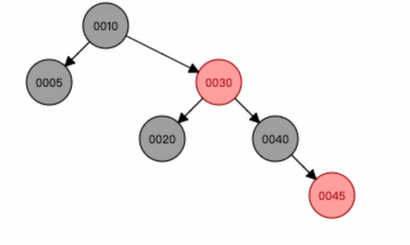
现在我们要向树中添加一个数字:60
根据我们的计算,最后的结果应当是:30指向45,45下面的左节点位40,右节点为60
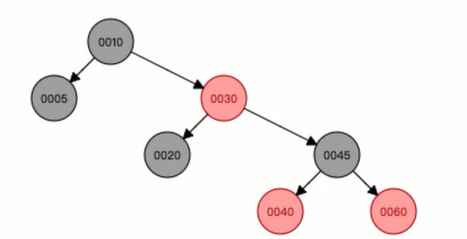
我们对比两张图片可以开电脑,原来的30是指向了40,但是现在指向了45,这种情况就是红黑树的左旋。
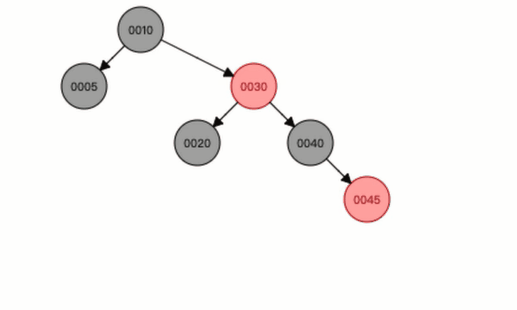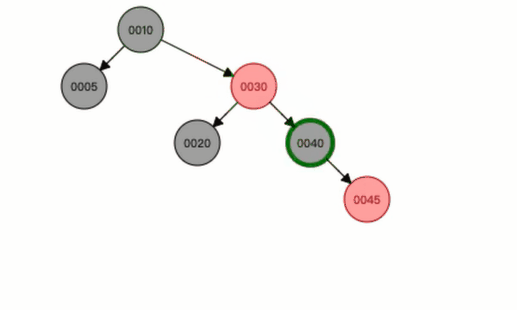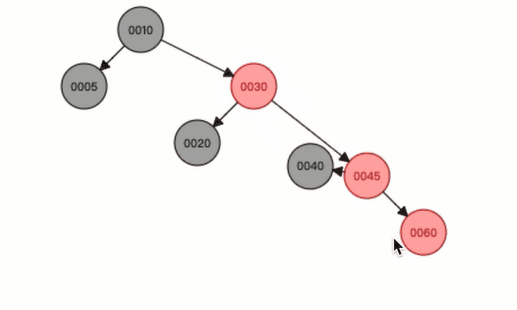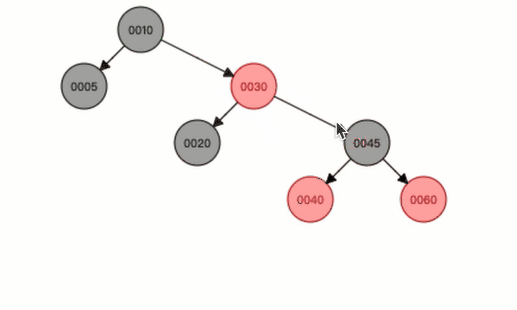
右旋也是一样的,就类似这种结果。
那么现在来总结一下,在红黑树插入新节点的过程中,是如何进行改变的:``
1、假如父节点是黑色的,不用进行调整
2、假如父节点是红色的
- 假如叔叔为空,旋转+变色
- 叔叔为黑色,旋转+变色
- 叔叔为红色,父节点+叔叔节点变为黑色,祖父节点变为红色(进行递归,直到整个红黑树满足规则即可结束)
HashMap的理解
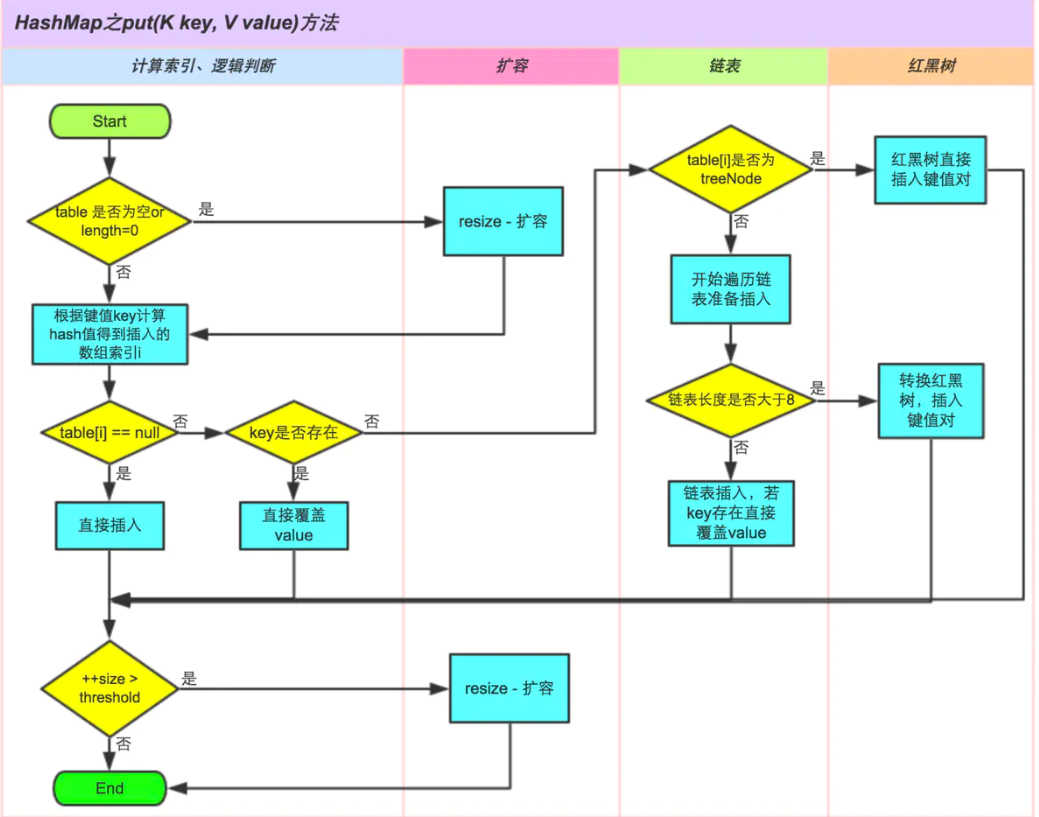
public V put(K key, V value) {
/*
四个参数
第一个hash值
第四个参数表示如果该key存在值如果为null的话,则插入新的value
最后一个参数,在hashMap中没有用,可以不用管,使用默认的即可
*/
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
//tab为哈希数组,p为该哈希桶(数组桶)的首节点,n为hashMap的长度,i为计算出的数组下标
Node<K,V>[] tab; Node<K,V> p; int n, i;
//获取长度并进行扩容,使用的是懒加载,table一开始是没有加载的,等put后才开始加载
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
/*
如果计算出的该哈希桶的位置没有值,则把新插入的key-value放到此处
此处就算没有插入成功,也就是发生哈希冲突时也会把哈希桶的首节点赋予p
*/
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
//发生哈希冲突的几种情况
else {
// e 临时节点的作用, k 存放该当前节点的key
Node<K,V> e; K k;
//第一种,插入的key-value的hash值,key都与当前节点的相等,e = p,则表示为首节点
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) e = p;
//第二种,hash值不等于首节点,判断该p是否属于红黑树的节点
else if (p instanceof TreeNode)
/*
为红黑树的节点,则在红黑树中进行添加
如果该节点已经存在,则返回该节点(不为null)
该值很重要,用来判断put操作是否成功,如果添加成功返回null
*/
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//第三种,hash值不等于首节点,不为红黑树的节点,则为链表的节点
else {
//遍历该链表
for (int binCount = 0; ; ++binCount) {
//如果找到尾部,则表明添加的key-value没有重复,在尾部进行添加
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
/*
判断是否要转换为红黑树结构(或者进行扩容),这里的TREEIFY_THRESHOLD为8
但是注意binCount是从0开始增加的,这就代表着加到7的时候就已经是8条数据了
*/
if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); break;
}
//如果链表中有重复的key,e则为当前重复的节点,结束循环
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) break;
p = e;
}
}
//有重复的key,则用待插入值进行覆盖,返回旧值。
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//到了此步骤,则表明待插入的key-value是没有key的重复,因为插入成功e节点的值为null
//修改次数+1
++modCount;
//实际长度+1,判断是否大于临界值,大于则扩容
if (++size > threshold) resize();
afterNodeInsertion(evict);
//添加成功
return null;
}
/*
我们在上面说,当数组中的链表大于8的时候,就要进行判断是否要进行扩容,或者是转换为红黑树
*/
final void treeifyBin(HashMap.Node<K,V>[] tab, int hash) {
int n, index; HashMap.Node<K,V> e;
// 如果Map为空或者当前存入数据n(可以理解为map的size())的数量小于64便进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize();
// 如果size()大于64则将正在存入的该值所在链表转化成红黑树
else if ((e = tab[index = (n - 1) & hash]) != null) {
HashMap.TreeNode<K,V> hd = null, tl = null;
do {
HashMap.TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
数组扩容只需要满足以下两个条件之一即可:
1、HashMap的容量超过了负载因子的限制容量(默认为0.75)时,扩容。比如数组有16个,填满了12个就开始扩容
2、某个数组桶中,链表的长度大于8并且HashMap数组长度小于64,进行扩容
数组中的链表转换为红黑树的条件:当前数组桶中的链表长度大于等于8并且数组长度大于等于64,开始转换为红黑树。
假如红黑树的节点小于6,那么转换回链表