一 概述
String由final修饰,是不可变类,即String对象也是不可变对象.这意味着当修改一个String对象的内容时,JVM不会改变原来的对象,而是生成一个新的String对象
主要考虑以下原因:
- 为了实现字符串池(提升效率)
只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现,因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。 - 为了线程安全
同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的String被广泛用作许多java类的参数,例如网络连接、打开文件等。如果对string的某一处改变一不小心就影响了该变量所有引用的表现,则连接或文件将被更改,这可能导致严重的安全威胁。 - 为了实现String可以创建HashCode不可变性
因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这样更有效率。因为当向集合中插入对象时,是通过hashcode判别在集合中是否已经存在该对象了(不是通过equals方法逐个比较,效率低)这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串
二 常量池
Java中的常量池分为三种类型:
- 类文件中常量池(The Constant Pool):
存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)
| 字面量 | 符号引用 |
|---|---|
| 文本字符串 | 类和接口的全限定名 |
| 八种基本类型的值 | 字段的名称和描述符 |
| 被声明为final的常量等 | 方法的名称和描述符 |
- 运行时常量池(The Run-Time Constant Pool)
诞生时间:JVM运行时
内容概要:class文件元信息描述,编译后的代码数据,引用类型数据,类文件常量池。
所谓的运行时常量池其实就是将编译后的类信息放入运行时的一个区域中,用来动态获取类信息。
运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。 - String常量池(String Pool)
- JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,即字符串池(String Pool)。字符串池由String类私有的维护
JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代. - JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是hotspot中的永久代
JDK1.8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace) - 在1.6中,常量池在方法区,intern()会把首次遇到的字符串实例复制到永久代中,返回的也是这个永久代中字符串实例的引用;
而在1.7,1.8中,String 的 intern 方法不会再复制实例到常量池中,如果不存在,则这个String肯定在堆中,则将当前实例的引用复制到实例中并返回该引用,如果存在则直接返回该实例 - 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个Hash表,jdk6中默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
字符串常量由一个一个字符组成,放在了StringTable上。。而在java 7中一开始就是可以配置的(至少在java7u02中是可以配置的)。你需要指定参数 -XX:StringTableSize=N, N 是字符串池 Map 的大小。
确保它是为性能调优而预先准备的大小,jdk8中大小已经增大到60013
- JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,即字符串池(String Pool)。字符串池由String类私有的维护
三 实现接口
String类实现了 java.io.Serializable, Comparable
1 java.io.Serializable
Serializable接口没有定义方法,仅仅作为jvm的标识,表明实现了此接口的的对象可以被序列化,进行io或者网络保存和传输
2 Comparable
Comparable接口是一个泛型接口,jdk提供这个接口来解决两个对象比较的问题,接口只定义了一个方法,即cpmpareTo方法,接受泛型T参数判断这个象相对于比较对象的顺序,小于返回负整数,等于返回0,大于返回正整数。
Java类库中:Byte,Short,Integer,Long,Float,Double,Character,BigTnteger,BigDecimal,Calendar,String及Data类都实现了Comparable接口,自定义对象可以实现此接口进行自定义比较
3 CharSequence
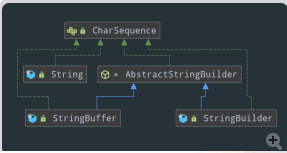
在JDK1.4中,引入了CharSequence接口,表示char 值的一个可读序列(有序集合)。String本质上也是char数组,即char可读序列的一种实现.
此接口对许多不同种类的 char 序列提供统一的只读访问,实现了这个接口的类有:CharBuffer、String、StringBuffer、StringBuilder这个四个类,接口定义了以下几个方法,其中1.8新增了两个关于Stream的方法:
public interface CharSequence {
//长度
int length();
//根据索引返回char值
char charAt(int index);
//根据索引区间,求子序列
java.lang.CharSequence subSequence(int start, int end);
public String toString();
//1.8新增方法,返回一个char类型组成的int流
public default IntStream chars() {
class CharIterator implements PrimitiveIterator.OfInt {
int cur = 0;
public boolean hasNext() {
return cur < length();
}
public int nextInt() {
if (hasNext()) {
return charAt(cur++);
} else {
throw new NoSuchElementException();
}
}
//对每个剩余的元素执行给定的动作,按照迭代时发生的顺序,直到所有元素都被处理或动作引发异常
@Override
public void forEachRemaining(IntConsumer block) {//接受一个consumer函数
for (; cur < length(); cur++) {
block.accept(charAt(cur));
}
}
}
return StreamSupport.intStream(() ->
Spliterators.spliterator(
new CharIterator(),
length(),
Spliterator.ORDERED),
Spliterator.SUBSIZED | Spliterator.SIZED | Spliterator.ORDERED,
false);
}
//从此序列返回码流值(Unicode码元数字组成的int流),即如果有辅助平面字符集,比如 0x10000,会返回这个码元数字,而不会返回其中一个char的数字(0xDc00等)
public default IntStream codePoints() {
class CodePointIterator implements PrimitiveIterator.OfInt {
int cur = 0;
@Override
public void forEachRemaining(IntConsumer block) {
final int length = length();
int i = cur;
try {
while (i < length) {
char c1 = charAt(i++);
if (!Character.isHighSurrogate(c1) || i >= length) {
block.accept(c1);
} else {
char c2 = charAt(i);
if (Character.isLowSurrogate(c2)) {
i++;
block.accept(Character.toCodePoint(c1, c2));
} else {
block.accept(c1);
}
}
}
} finally {
cur = i;
}
}
public boolean hasNext() {
return cur < length();
}
public int nextInt() {
final int length = length();
if (cur >= length) {
throw new NoSuchElementException();
}
char c1 = charAt(cur++);
if (Character.isHighSurrogate(c1) && cur < length) {
char c2 = charAt(cur);
if (Character.isLowSurrogate(c2)) {
cur++;
return Character.toCodePoint(c1, c2);
}
}
return c1;
}
}
return StreamSupport.intStream(() ->
Spliterators.spliteratorUnknownSize(
new CodePointIterator(),
Spliterator.ORDERED),
Spliterator.ORDERED,
false);
}
@SuppressWarnings("unchecked")
public static int compare(java.lang.CharSequence cs1, java.lang.CharSequence cs2) {
if (Objects.requireNonNull(cs1) == Objects.requireNonNull(cs2)) {
return 0;
}
if (cs1.getClass() == cs2.getClass() && cs1 instanceof Comparable) {
return ((Comparable<Object>) cs1).compareTo(cs2);
}
for (int i = 0, len = Math.min(cs1.length(), cs2.length()); i < len; i++) {
char a = cs1.charAt(i);
char b = cs2.charAt(i);
if (a != b) {
return a - b;
}
}
return cs1.length() - cs2.length();
}
}
四 源码解析
String的源码比较多且相对复杂,这里使用分类解析,里面也包含了jdk9之后的一些比较大的变动,这里都会列举对比出来,为了节省篇幅,已经废弃的方法这里不再列举:
1 属性
// 一 属性
/**
* 用来存字符串,字符串的本质:
* jdk1.8之前是一个final的char型数组,且不可变:
* private final char value[];
* jdk1.9带来了字符串两大改善,更小的内存空间和改善表现,
* 内存改为final的byte数组,StringBuffer和StringBuild也做了一样的处理,
* 这样英文字母就可以用一个字节存储,节省了内存,汉字的话意义不大
* 因为java内部使用UTF-16编码(定长),一个char为两个字节,所以英文字母一个字节用char存储就会造成空间浪费
*/
@Stable
private final byte[] value;
/**
* jdk9新增的一个编码格式的标识,使用LATIN1还是UTF-16,这个是在String生成的时候自动的,
* 如果字符串中都是能用LATIN1,coder值就是0,否则就是1 表示UTF-16
* 例如: String a="a"; 断点查看 value数组只有一个即一个字节,code=0
* String h="侯"; value数组有两个即两个字节, code=1
*/
private final byte coder;
/**
* hash是String实例化的hashcode的一个缓存。因为String经常被用于比较,比如在HashMap中。
* 如果每次进行比较都重新计算hashcode的值的话,那无疑是比较麻烦的,
* 而保存一个hashcode的缓存无疑能优化这样的操作
*/
private int hash; // Default to 0
/** 序列化的标识 */
private static final long serialVersionUID = -6849794470754667710L;
/** 字符串压缩标识: COMPACT_STRINGS默认为true,即该特性默认是开启的 */
static final boolean COMPACT_STRINGS;
//默认开启,可通过JVM参数-XX:-CompactStrings 关闭,这个时候JVM会进行再赋值处理 ,COMPACT_STRINGS 就为false了,可以debug验证
static {
COMPACT_STRINGS = true;
}
// 新增两种编码格式的标识符
@Native
static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
// coder方法判断COMPACT_STRINGS为true的话,则返回coder值,否则返回UTF16;
final byte getCoder() {
return COMPACT_STRINGS ? coder : UTF16;
}
// 判断编码是够是isLatin1
final boolean isLatin1() {
return COMPACT_STRINGS && coder == LATIN1;
}
属性里面主要就是看一下final类型的byte[],jdk8之前是char[],还有新增的一个coder编码标识,和两种编码方式,在后面的构造器和API中会大量使用这几个
2 构造器
// 二 构造器
/** 空字符串构造器 */
public String() {
this.value = "".value;
this.coder = "".coder; //新增coder赋值
}
/** 参数为一个String对象的构造器
* 将形参的value和hash以及coder赋值给实例对象作为初始化
* 相当于深拷贝了一个形参String对象 */
@HotSpotIntrinsicCandidate
public String(java.lang.String original) {
this.value = original.value;
this.coder = original.coder;
this.hash = original.hash;
}
/**
* 通过char数组参数来构造String对象,实际将参数char数组值复制给String对象的char数组
* 不能直接赋值,因为cahr数组是可变的,会影响构造的String对象值
*/
public String(char value[]) {
this(value, 0, value.length, null);
}
/**
* 截取入参数组的一部分来构造String对象,具体哪一部分由offset和count决定,
* 其中做了些参数检查,传入非法参数会报数组越界异常StringIndexOutOfBoundsException
*/
public String(char value[], int offset, int count) {
this(value, offset, count, rangeCheck(value, offset, count));
}
// 返回Void占位符类型
private static Void rangeCheck(char[] value, int offset, int count) {
checkBoundsOffCount(offset, count, value.length);//数组越界检查
return null;
}
/*
* 截取char数组一部分构造对象
* Void类是一个不可实例化的占位符类,如果方法返回值是Void类型,那么该方法只能返回null类型,
* 即不需要返回任何数据,只做相应处理,比如检查参数,消费参数等,这里占位符达到方法复用的目的,
* 调用时不需要的可以直接传null,需要的可以是一个返回Void类型的方法,在里面做一些检查等
*/
String(char[] value, int off, int len, Void sig) {
if (len == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
//COMPACT_STRINGS 默认为true,即会先尝试是否可以压缩,即用一个char表示
if (COMPACT_STRINGS) {
//会先遍历char数组中每个char,对齐进行和0xFF比较,如果有任何一个char大于0xFF,则返回null,否则返回构造的byte数组
byte[] val = StringUTF16.compress(value, off, len);
if (val != null) {
this.value = val;
this.coder = LATIN1;
return;
}
}
//使用
this.coder = UTF16;// UTF-16编码,直接转字节数组
//会先创建一个双倍大小的byte数组,new byte[len << 1],然后进行put数据,每个char都会put两个byte进去
// 会根据高端或者低端字节序进行 8位8位的put,
this.value = StringUTF16.toBytes(value, off, len);
}
/**
* 使用int数组构造String对象,int值会对应unicode编码的值,比如 65->A
*/
public String(int[] codePoints, int offset, int count) {
checkBoundsOffCount(offset, count, codePoints.length);
if (count == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
if (COMPACT_STRINGS) {
//这里会遍历int[]中每个元素,会进行 >>> 逻辑右移,如果不为0(即大于8位,大于256),则返回null
byte[] val = StringLatin1.toBytes(codePoints, offset, count);
if (val != null) {
this.coder = LATIN1;
this.value = val;
return;
}
}
this.coder = UTF16;
this.value = StringUTF16.toBytes(codePoints, offset, count);
}
/**
* 使用byte数组构造String对象并按照指定编码格式(参数是String)
*/
public String(byte bytes[], int offset, int length, java.lang.String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBoundsOffCount(offset, length, bytes.length);
StringCoding.Result ret =
StringCoding.decode(charsetName, bytes, offset, length);
this.value = ret.value;
this.coder = ret.coder;
}
/**
* 使用byte数组构造String对象并按照指定编码格式(参数是Charset对象)
*/
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBoundsOffCount(offset, length, bytes.length);
StringCoding.Result ret =
StringCoding.decode(charset, bytes, offset, length);
this.value = ret.value;
this.coder = ret.coder;
}
/**
* 使用byte 数组,指定charsetName编码名字
*/
public String(byte bytes[], java.lang.String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
/**
* 使用byte数组,指定编码格式
*/
public String(byte bytes[], Charset charset) {
this(bytes, 0, bytes.length, charset);
}
/**
* 使用byte数组构造
*/
public String(byte bytes[], int offset, int length) {
checkBoundsOffCount(offset, length, bytes.length);
StringCoding.Result ret = StringCoding.decode(bytes, offset, length);
this.value = ret.value;
this.coder = ret.coder;
}
/**
* 使用 byte数组构造String对象
*/
public String(byte[] bytes) {
this(bytes, 0, bytes.length);
}
/**
* 使用StringBuffer对象构造器
*/
public String(StringBuffer buffer) {
this(buffer.toString());
}
/**
* 使用StringBuilder对象构造器
*/
public String(StringBuilder builder) {
this(builder, null);
}
/*
* 包私有构造函数,外面无法调用。后面的Void参数用于消除与其他(公共)构造函数的歧义,比如有一个new String(StringBuilder builder),同名同参的
*/
String(AbstractStringBuilder asb, Void sig) {
byte[] val = asb.getValue();
int length = asb.length();
if (asb.isLatin1()) {
this.coder = LATIN1;
this.value = Arrays.copyOfRange(val, 0, length);
} else {
if (COMPACT_STRINGS) {
byte[] buf = StringUTF16.compress(val, 0, length);
if (buf != null) {
this.coder = LATIN1;
this.value = buf;
return;
}
}
this.coder = UTF16;
this.value = Arrays.copyOfRange(val, 0, length << 1);
}
}
2.1 StringUTF16工具类分析
这里部分构造器主要使用了StringUTF16和StringLatin1这两个工具类的方法进行byte和char转换,下面分析其中两个方法:
尝试转化char数组的方法:
- StringUTF16.compress(value, off, len)
public static byte[] compress(char[] val, int off, int len) {
byte[] ret = new byte[len];
// 如果compress返回int==len,则返回构造的byte数组,否则返回null
if (compress(val, off, ret, 0, len) == len) {
return ret;
}
return null;
}
// compressedCopy char[] -> byte[]
@HotSpotIntrinsicCandidate
public static int compress(char[] src, int srcOff, byte[] dst, int dstOff, int len) {
for (int i = 0; i < len; i++) {
char c = src[srcOff];
// 如果 char数组中有任何值大于0xFF,则直接返回0, 因为char在内存中存储的也是数字,可直接进行比较
if (c > 0xFF) {
len = 0;
break;
}
dst[dstOff] = (byte)c;
srcOff++;
dstOff++;
}
return len;
}
- StringUTF16.toBytes(value, off, len); 使用两个byte存储一个char的转化方法:
@HotSpotIntrinsicCandidate
public static byte[] toBytes(char[] value, int off, int len) {
// 这里使用UTF-16存储,所以一个char需要两个byte存储,len需要变成2倍
byte[] val = newBytesFor(len);
for (int i = 0; i < len; i++) {
//每个char分为两个byte进行put
putChar(val, i, value[off]);
off++;
}
return val;
}
//根据len,创建一个两倍大小的byte数组
public static byte[] newBytesFor(int len) {
if (len < 0) {
throw new NegativeArraySizeException();
}
if (len > MAX_LENGTH) {
throw new OutOfMemoryError("UTF16 String size is " + len +
", should be less than " + MAX_LENGTH);
}
return new byte[len << 1];
}
static void putChar(byte[] val, int index, int c) {
assert index >= 0 && index < length(val) : "Trusted caller missed bounds check";
index <<= 1;
//两个byte存储一个完整的char
val[index++] = (byte)(c >> HI_BYTE_SHIFT);// 右移8位,高位put
val[index] = (byte)(c >> LO_BYTE_SHIFT);// 右移0位,不变,高于8位的自动舍弃,即地位
}
3 API
- length() 与 isEmpty()
/**
* 返回字符串长度,即字符数组长度,jdk9中因为改用byte数组,加入了可选编码,所以计算长度也要根据编码方式计算:
* 如果是LATIN1,则 coder()返回0 ,长度为byte数组长度,一个byte存储一个char
* 如果是UTF-16,则coder()返回1, 长度为byte数组的一半,两个byte为一个字符char
*/
public int length() {
return value.length >> coder();
}
/**
* 判断是否为空,即判断byte数组长度是否为0
*/
public boolean isEmpty() {
return value.length == 0;
}
- charAt(int index)
/**
* 返回字符串中的第index位置的值
*/
public char charAt(int index) {
if (isLatin1()) {// Latin1 编码
return StringLatin1.charAt(value, index);
} else { // UTF-16 编码
return StringUTF16.charAt(value, index);
}
}
这里需要注意下这两个工具类的方法:
StringLatin1.charAt(value, index):
public static char charAt(byte[] value, int index) {
if (index < 0 || index >= value.length) {
throw new StringIndexOutOfBoundsException(index);
}
/**
* value[index] & 0xff : 结果为int,即byte -> int
* 16进制数 0xff 二进制就是11111111 ,高位都为0
* 因为&操作中,超过0xff的部分,全部都会变成0,而对于0xff以内的数据,
* 它不会影响原来的值,取其最低8位,即一个字节的值,此操作也能保证负数补码不变
*/
return (char)(value[index] & 0xff);
}
StringUTF16.charAt(value, index):
public static char charAt(byte[] value, int index) {
checkIndex(index, value);
return getChar(value, index);
}
static char getChar(byte[] val, int index) {
assert index >= 0 && index < length(val) : "Trusted caller missed bounds check";
/**
* index 乘以2 ,因为是使用两个字节编码,所以实际的char在byte数组中index需要乘以2
* 比如 第1个char,索引是0和1,第二个是2和3,所以当index等于1时(找第二个char),需要从2开始查找
*/
index <<= 1;
//求出两个字节的值,分别位移到高低位,再进行位或运算,将两个byte组合成一个char
return (char)(((val[index++] & 0xff) << HI_BYTE_SHIFT) |
((val[index] & 0xff) << LO_BYTE_SHIFT));
}
- codePoint相关方法
/**
* 返回String对象的byte数组index位置的元素byte值的ASSIC码(int类型)
*/
public int codePointAt(int index) {
if (isLatin1()) {
checkIndex(index, value.length);
return value[index] & 0xff;
}
int length = value.length >> 1;
checkIndex(index, length);
// 使用UTF16工具类处理,这里会对获取的char进行判断是否是高代理highSurrogate,如果是再判断后面一位是否是低代理,如果是则进行两个组合的int值返回
// 这里涉及到一些unicode编码以及UTF-16的一些知识,高代理,低代理等涉及.以及减去0x10000码位运算等,这里就不细说了,了解Unicode编码的话就很容易理解,不然无法看懂里面转化的源码
return StringUTF16.codePointAt(value, index, length);
}
/**
* 返回index位置元素的前一个元素的ASSIC码(int型)
*/
public int codePointBefore(int index) {
int i = index - 1;
if (i < 0 || i >= length()) {
throw new StringIndexOutOfBoundsException(index);
}
if (isLatin1()) {
return (value[i] & 0xff);
}
return StringUTF16.codePointBefore(value, index);
}
/**
* * 方法返回的是代码点个数,是实际上的字符个数,功能类似于length()
* * 对于正常的String来说,length方法和codePointCount没有区别,都是返回字符个数。
* * 但当String是Unicode类型时则有区别了。
* * 例如:String str = “/uD835/uDD6B” (即使 'Z' ), length() = 2 ,codePointCount() = 1
*/
public int codePointCount(int beginIndex, int endIndex) {
if (beginIndex < 0 || beginIndex > endIndex ||
endIndex > length()) {
throw new IndexOutOfBoundsException();
}
if (isLatin1()) {
return endIndex - beginIndex;
}
return StringUTF16.codePointCount(value, beginIndex, endIndex);
}
/**
* 也是相对Unicode字符集而言的,从index索引位置算起,偏移codePointOffset个位置,返回偏移后的位置是多少
* 例如,index = 2 ,codePointOffset = 3 ,maybe返回 5
*/
public int offsetByCodePoints(int index, int codePointOffset) {
if (index < 0 || index > length()) {
throw new IndexOutOfBoundsException();
}
return Character.offsetByCodePoints(this, index, codePointOffset);
}
- getChars和getBytes相关的一些方法
/**
* 这是一个不对外的包私有方法,是给String内部调用的,因为它是没有访问修饰符的,只允许同一包下的类访问
* 参数:dst[]是目标数组,dstBegin是目标数组的偏移量,既要复制过去的起始位置(从目标数组的什么位置覆盖)
* 作用就是将String的字符数组value整个复制到dst字符数组中,在dst数组的dstBegin位置开始拷贝
*/
void getBytes(byte dst[], int dstBegin, byte coder) {
if (coder() == coder) {
//这里调用的是native底层方法
System.arraycopy(value, 0, dst, dstBegin << coder, value.length);
} else { // this.coder == LATIN && coder == UTF16
StringLatin1.inflate(value, 0, dst, dstBegin, value.length);
}
}
/**
* 获得charsetName编码格式的bytes数组
*/
public byte[] getBytes(java.lang.String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, coder(), value);
}
/**
* 获得Charset编码格式的bytes数组
*/
public byte[] getBytes(Charset charset) {
if (charset == null) throw new NullPointerException();
return StringCoding.encode(charset, coder(), value);
}
/**
* 使用平台默认编码获取bytes数组,会获取 file.encoding 属性,获取不到则使用new UTF_8()
*/
public byte[] getBytes() {
return StringCoding.encode(coder(), value);
}
- equals 和 compareTo 和 regionMatches 相关方法
/**
* String的equals方法,重写了Object的equals方法(区分大小写)
* 比较的是两个字符串的值是否相等
* 参数是一个Object对象,而不是一个String对象。这是因为重写的是Object的equals方法,所以是Object
* 如果是String自己独有的方法,则可以传入String对象,不用多此一举
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof java.lang.String) {
java.lang.String aString = (java.lang.String)anObject;
//先判断coder是否相等,即使用的编码格式
if (coder() == aString.coder()) {
//根据编码格式具体比较,其实就是获取char的时候是一个byte还是两个byte分开处理
// for循环对每一个数组的值进行==比较,全部相等返回true
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
/**
* 这是一个公有的比较方法,参数是StringBuffer类型
* 实际调用的是contentEquals(CharSequence cs)方法,可以说是StringBuffer的特供版
*/
public boolean contentEquals(StringBuffer sb) {
return contentEquals((java.lang.CharSequence)sb);
}
/**
* 这是一个常用于String对象跟StringBuffer和StringBuilder比较的方法
* 参数是StringBuffer或StringBuilder或String或CharSequence
* StringBuffer和StringBuilder和String都实现了CharSequence接口
*/
public boolean contentEquals(java.lang.CharSequence cs) {
// Argument is a StringBuffer, StringBuilder
if (cs instanceof AbstractStringBuilder) {
if (cs instanceof StringBuffer) {
synchronized(cs) { //StringBuffer 是线程安全的,类里面方法都实现了synchronized线程同步,这里也要保持同步
//调用私有比较方法
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
} else {
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
}
// Argument is a String
if (cs instanceof java.lang.String) {
return equals(cs);
}
// Argument is a generic CharSequence
int n = cs.length();
if (n != length()) {
return false;
}
byte[] val = this.value;
if (isLatin1()) {
for (int i = 0; i < n; i++) {
if ((val[i] & 0xff) != cs.charAt(i)) {
return false;
}
}
} else {
if (!StringUTF16.contentEquals(val, cs, n)) {
return false;
}
}
return true;
}
/**
* 这是一个私有方法,特供给比较StringBuffer和StringBuilder使用的。
* 比如在contentEquals方法中使用,参数是AbstractStringBuilder抽象类的子类
*/
private boolean nonSyncContentEquals(AbstractStringBuilder sb) {
int len = length();
if (len != sb.length()) {
return false;
}
byte v1[] = value;
byte v2[] = sb.getValue();
if (coder() == sb.getCoder()) {
int n = v1.length;
for (int i = 0; i < n; i++) {
if (v1[i] != v2[i]) {
return false;
}
}
} else {
if (!isLatin1()) { // utf16 str and latin1 abs can never be "equal"
return false;
}
return StringUTF16.contentEquals(v1, v2, len);
}
return true;
}
}
/**
* 这也是一个String的equals方法,与上一个方法不用,该方法(不区分大小写),从名字也能看出来
* 是对String的equals方法的补充。
* 这里参数这是一个String对象,而不是Object了,因为这是String本身的方法,不是重写谁的方法
*/
public boolean equalsIgnoreCase(java.lang.String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.length() == length())
&& regionMatches(true, 0, anotherString, 0, length());
}
/**
* 这是一个类似于equals的方法,比较的是字符串的片段,也即是部分区域的比较,区分大小写比较,即 A != a
* toffset是当前字符串的比较起始位置(偏移量),other是要比较的String对象参数,ooffset是要参数String的比较片段起始位置,len是两个字符串要比较的片段的长度大小
* 例子:String str1 = "0123456",Str2 = "0123456789";
* str1.regionMatchs(0,str2,0,6);意思是str1从0位置开始于str2的0位置开始比较6个长度的字符串片段
* 相等则返回 true,不等返回false
*/
public boolean regionMatches(int toffset, java.lang.String other, int ooffset, int len) {
byte tv[] = value;
byte ov[] = other.value;
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0) ||
(toffset > (long)length() - len) ||
(ooffset > (long)other.length() - len)) {
return false;
}
if (coder() == other.coder()) {
if (!isLatin1() && (len > 0)) {
toffset = toffset << 1;
ooffset = ooffset << 1;
len = len << 1;
}
while (len-- > 0) {
if (tv[toffset++] != ov[ooffset++]) {
return false;
}
}
} else {
if (coder() == LATIN1) {
while (len-- > 0) {
if (StringLatin1.getChar(tv, toffset++) !=
StringUTF16.getChar(ov, ooffset++)) {
return false;
}
}
} else {
while (len-- > 0) {
if (StringUTF16.getChar(tv, toffset++) !=
StringLatin1.getChar(ov, ooffset++)) {
return false;
}
}
}
}
return true;
}
/**
* 是否区分大小写的部分比较,比上面方法多了一个是否区分大小写参数
*/
public boolean regionMatches(boolean ignoreCase, int toffset,
java.lang.String other, int ooffset, int len) {
if (!ignoreCase) {
return regionMatches(toffset, other, ooffset, len);
}
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0)
|| (toffset > (long)length() - len)
|| (ooffset > (long)other.length() - len)) {
return false;
}
byte tv[] = value;
byte ov[] = other.value;
// 这里面比较主要是会对每一个字符进行大小写转化进行比较,大写和小写都会转化比较一次,不相等就返回false,相等则继续,达到忽略大胸写的目的
if (coder() == other.coder()) {
return isLatin1()
? StringLatin1.regionMatchesCI(tv, toffset, ov, ooffset, len)
: StringUTF16.regionMatchesCI(tv, toffset, ov, ooffset, len);
}
return isLatin1()
? StringLatin1.regionMatchesCI_UTF16(tv, toffset, ov, ooffset, len)
: StringUTF16.regionMatchesCI_Latin1(tv, toffset, ov, ooffset, len);
}
/**
* 这是一个比较字符串中字符大小的函数,因为String实现了Comparable<String>接口,所以重写了compareTo方法
* Comparable是排序接口。若一个类实现了Comparable接口,就意味着该类支持排序。
* 实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
* 参数是需要比较的另一个String对象
* 返回的int类型,正数为大,负数为小,是基于字符的ASSIC码比较的
*/
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
if (coder() == anotherString.coder()) {
// 底层都是 char元素的相减运算,大于则为整数,相等则为0,小于则为负数
return isLatin1() ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return isLatin1() ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}
/**
* 这是一个饿汉单例模式,是String类型的一个不区分大小写的比较器
* 提供给Collections和Arrays的sort方法使用
* 例如:Arrays.sort(strs,String.CASE_INSENSITIVE_ORDER);
* 效果就是会将strs字符串数组中的字符串对象进行忽视大小写的排序
*/
public static final Comparator<java.lang.String> CASE_INSENSITIVE_ORDER
= new java.lang.String.CaseInsensitiveComparator();
/**
* 这一个私有的静态内部类,只允许String类本身调用
* 实现了序列化接口和比较器接口,comparable接口和comparator是有区别的
* 重写了compare方法,该静态内部类实际就是一个String类的比较器
*
*/
private static class CaseInsensitiveComparator
implements Comparator<java.lang.String>, java.io.Serializable {
// use serialVersionUID from JDK 1.2.2 for interoperability
private static final long serialVersionUID = 8575799808933029326L;
public int compare(java.lang.String s1, java.lang.String s2) {
byte v1[] = s1.value;
byte v2[] = s2.value;
if (s1.coder() == s2.coder()) {
return s1.isLatin1() ? StringLatin1.compareToCI(v1, v2)
: StringUTF16.compareToCI(v1, v2);
}
return s1.isLatin1() ? StringLatin1.compareToCI_UTF16(v1, v2)
: StringUTF16.compareToCI_Latin1(v1, v2);
}
/** Replaces the de-serialized object. */
private Object readResolve() { return CASE_INSENSITIVE_ORDER; }
}
- startWith、endWith相关方法
/**
* 作用就是当前对象[toffset,toffset + prefix.value.lenght]区间的字符串片段等于prefix
* 也可以说当前对象的toffset位置开始是否以prefix作为前缀
* prefix是需要判断的前缀字符串,toffset是当前对象的判断起始位置
*/
public boolean startsWith(java.lang.String prefix, int toffset) {
// Note: toffset might be near -1>>>1.
if (toffset < 0 || toffset > length() - prefix.length()) {
return false;
}
byte ta[] = value;
byte pa[] = prefix.value;
int po = 0;
int pc = pa.length;
if (coder() == prefix.coder()) {
//获取到开始比较的位置to
int to = isLatin1() ? toffset : toffset << 1;
while (po < pc) { //循环比较
if (ta[to++] != pa[po++]) {
return false;
}
}
} else {
if (isLatin1()) { // && pcoder == UTF16
return false;
}
// coder == UTF16 && pcoder == LATIN1)
while (po < pc) {
if (StringUTF16.getChar(ta, toffset++) != (pa[po++] & 0xff)) {
return false;
}
}
}
return true;
}
/**
* 判断当前字符串对象是否以字符串prefix起头
* 是返回true,否返回fasle
*/
public boolean startsWith(java.lang.String prefix) {
return startsWith(prefix, 0);
}
/**
* 判断当前字符串对象是否以字符串prefix结尾
* 是返回true,否返回fasle
*/
public boolean endsWith(java.lang.String suffix) {
return startsWith(suffix, length() - suffix.length());
}
- hashCode方法
/**
* 这是String字符串重写了Object类的hashCode方法。
* 给由哈希表来实现的数据结构来使用,比如String对象要放入HashMap中。
* 如果没有重写HashCode,或HaseCode质量很差则会导致严重的后果,既不靠谱的后果
*/
public int hashCode() {
int h = hash; //hash是属性字段,是成员变量,默认为0
if (h == 0 && value.length > 0) { //如果hash为0,且字符串对象长度大于0,不为""
//根据编码计算哈希值
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
//StringLatin1.hashCode(value)
public static int hashCode(byte[] value) {
int h = 0;
//遍历byte数组
for (byte v : value) {
h = 31 * h + (v & 0xff);// 每次都是31 * 每次循环获得的h +第i个字符的ASSIC码 int值
}
return h;
}
//StringUTF16.hashCode(value);
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
- indexOf相关方法
/**
* 返回cn对应的字符在字符串中第一次出现的位置,从字符串的索引0位置开始遍历
*/
public int indexOf(int ch) {
return indexOf(ch, 0);
}
/**
* index方法就是返回ch字符第一次在字符串中出现的位置
* 既从fromIndex位置开始查找,从头向尾遍历,ch整数对应的字符在字符串中第一次出现的位置
* -1代表字符串没有这个字符,整数代表字符第一次出现在字符串的位置
*/
public int indexOf(int ch, int fromIndex) {
// for循环比较,相等返回i索引
return isLatin1() ? StringLatin1.indexOf(value, ch, fromIndex)
: StringUTF16.indexOf(value, ch, fromIndex);
}
/**
* 从尾部向头部遍历,返回cn第一次出现的位置,value.length - 1就是起点
* 为了理解,我们可以认为是返回cn对应的字符在字符串中最后出现的位置
*
* ch是字符对应的整数
*/
public int lastIndexOf(int ch) {
return lastIndexOf(ch, length() - 1);
}
/**
* 从尾部向头部遍历,从fromIndex开始作为起点,返回ch对应字符第一次在字符串出现的位置
* 既从头向尾遍历,返回cn对应字符在字符串中最后出现的一次位置,fromIndex为结束点
*
*/
public int lastIndexOf(int ch, int fromIndex) {
return isLatin1() ? StringLatin1.lastIndexOf(value, ch, fromIndex)
: StringUTF16.lastIndexOf(value, ch, fromIndex);
}
/**
* 返回第一次出现的字符串的位置
*/
public int indexOf(java.lang.String str) {
if (coder() == str.coder()) {
return isLatin1() ? StringLatin1.indexOf(value, str.value)
: StringUTF16.indexOf(value, str.value);
}
if (coder() == LATIN1) { // str.coder == UTF16
return -1;
}
return StringUTF16.indexOfLatin1(value, str.value);
}
/**
* 从fromIndex开始遍历,返回第一次出现str字符串的位置
*/
public int indexOf(java.lang.String str, int fromIndex) {
return indexOf(value, coder(), length(), str, fromIndex);
}
/**
* 这是一个不对外公开的静态函数
* source就是原始字符串,sourceOffset就是原始字符串的偏移量,起始位置。
* sourceCount就是原始字符串的长度,target就是要查找的字符串。
* fromIndex就是从原始字符串的第fromIndex开始遍历
*/
static int indexOf(byte[] src, byte srcCoder, int srcCount,
java.lang.String tgtStr, int fromIndex) {
byte[] tgt = tgtStr.value;
byte tgtCoder = tgtStr.coder();
int tgtCount = tgtStr.length();
if (fromIndex >= srcCount) {
return (tgtCount == 0 ? srcCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (tgtCount == 0) {
return fromIndex;
}
if (tgtCount > srcCount) {
return -1;
}
if (srcCoder == tgtCoder) {
return srcCoder == LATIN1
? StringLatin1.indexOf(src, srcCount, tgt, tgtCount, fromIndex)
: StringUTF16.indexOf(src, srcCount, tgt, tgtCount, fromIndex);
}
if (srcCoder == LATIN1) { // && tgtCoder == UTF16
return -1;
}
// srcCoder == UTF16 && tgtCoder == LATIN1) {
return StringUTF16.indexOfLatin1(src, srcCount, tgt, tgtCount, fromIndex);
}
/**
* 查找字符串Str最后一次出现的位置,后面都和查找第一次字符串位置一样的API
*/
public int lastIndexOf(java.lang.String str) {
return lastIndexOf(str, length());
}
public int lastIndexOf(java.lang.String str, int fromIndex) {
return lastIndexOf(value, coder(), length(), str, fromIndex);
}
static int lastIndexOf(byte[] src, byte srcCoder, int srcCount,
java.lang.String tgtStr, int fromIndex) {
byte[] tgt = tgtStr.value;
byte tgtCoder = tgtStr.coder();
int tgtCount = tgtStr.length();
/*
* Check arguments; return immediately where possible. For
* consistency, don't check for null str.
*/
int rightIndex = srcCount - tgtCount;
if (fromIndex > rightIndex) {
fromIndex = rightIndex;
}
if (fromIndex < 0) {
return -1;
}
/* Empty string always matches. */
if (tgtCount == 0) {
return fromIndex;
}
if (srcCoder == tgtCoder) {
return srcCoder == LATIN1
? StringLatin1.lastIndexOf(src, srcCount, tgt, tgtCount, fromIndex)
: StringUTF16.lastIndexOf(src, srcCount, tgt, tgtCount, fromIndex);
}
if (srcCoder == LATIN1) { // && tgtCoder == UTF16
return -1;
}
// srcCoder == UTF16 && tgtCoder == LATIN1
return StringUTF16.lastIndexOfLatin1(src, srcCount, tgt, tgtCount, fromIndex);
}
- substring,concat,replace,matches,spilt相关方法
/**
* 截取当前字符串对象的片段,组成一个新的字符串对象
* beginIndex为截取的初始位置,默认截到len - 1位置
*/
public java.lang.String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
/**
* 从区间范围开始截取
*/
public java.lang.String substring(int beginIndex, int endIndex) {
int length = length();
checkBoundsBeginEnd(beginIndex, endIndex, length);
int subLen = endIndex - beginIndex;
if (beginIndex == 0 && endIndex == length) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
/**
*/
public java.lang.CharSequence subSequence(int beginIndex, int endIndex) {
return this.substring(beginIndex, endIndex);
}
/**
* 拼接字符串,底层调用native方法对byte数组进行复制
*/
public java.lang.String concat(java.lang.String str) {
int olen = str.length();
if (olen == 0) {
return this;
}
if (coder() == str.coder()) {
byte[] val = this.value;
byte[] oval = str.value;
int len = val.length + oval.length;// 数组扩容
byte[] buf = Arrays.copyOf(val, len);// 拷贝
System.arraycopy(oval, 0, buf, val.length, oval.length);//natice方法,复制数组到buf
return new java.lang.String(buf, coder);
}
int len = length();
byte[] buf = StringUTF16.newBytesFor(len + olen);
getBytes(buf, 0, UTF16);
str.getBytes(buf, len, UTF16);
return new java.lang.String(buf, UTF16);
}
/**
* 替换,将字符串中的oldChar字符全部替换成newChar
*/
public java.lang.String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
java.lang.String ret = isLatin1() ? StringLatin1.replace(value, oldChar, newChar)
: StringUTF16.replace(value, oldChar, newChar);
if (ret != null) {
return ret;
}
}
return this;
}
/**
* matches() 方法用于检测字符串是否匹配给定的正则表达式。
* regex -- 匹配字符串的正则表达式。
* 如:String Str = new String("www.snailmann.com");
* System.out.println(Str.matches("(.*)snailmann(.*)")); output:true
* System.out.println(Str.matches("www(.*)")); output:true
*/
public boolean matches(java.lang.String regex) {
return Pattern.matches(regex, this);
}
//是否含有CharSequence这个子类元素,通常用于StrngBuffer,StringBuilder
public boolean contains(java.lang.CharSequence s) {
return indexOf(s.toString()) >= 0; //调用的是indexOF方法,是否能找到索引
}
/**
* 只替换第一个
*/
public java.lang.String replaceFirst(java.lang.String regex, java.lang.String replacement) {
return Pattern.compile(regex).matcher(this).replaceFirst(replacement);
}
/**
* 当不是正规表达式时,与replace效果一样,都是全体换。如果字符串的正则表达式,则规矩表达式全体替换
*/
public java.lang.String replaceAll(java.lang.String regex, java.lang.String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}
/**
* 可以用旧字符串去替换新字符串
*/
public java.lang.String replace(java.lang.CharSequence target, java.lang.CharSequence replacement) {
java.lang.String tgtStr = target.toString();
java.lang.String replStr = replacement.toString();
int j = indexOf(tgtStr);
if (j < 0) {
return this;
}
int tgtLen = tgtStr.length();
int tgtLen1 = Math.max(tgtLen, 1);
int thisLen = length();
int newLenHint = thisLen - tgtLen + replStr.length();
if (newLenHint < 0) {
throw new OutOfMemoryError();
}
StringBuilder sb = new StringBuilder(newLenHint);
int i = 0;
do {
sb.append(this, i, j).append(replStr);
i = j + tgtLen;
} while (j < thisLen && (j = indexOf(tgtStr, j + tgtLen1)) > 0);
return sb.append(this, i, thisLen).toString();
}
/**
* 按照给定的符号将String分割成String数组,limit表示分割次数限制,0 不限制次数
*/
public java.lang.String[] split(java.lang.String regex, int limit) {
/* regex是
一个char,并且此字符不是RegEx的元字符“$|()[{^”?*+\\“,或者
是两个字符字符串,第一个字符是反斜杠和第二个不是ascii数字或ascii字母
*/
char ch = 0;
if (((regex.length() == 1 &&
".$|()[{^?*+\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0; //是否限制次数,>0则有限制次数
ArrayList<java.lang.String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next)); //使用子字符串加入list
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
int last = length();
list.add(substring(off, last));
off = last;
break;
}
}
// If no match was found, return this
if (off == 0)
return new java.lang.String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, length()));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
java.lang.String[] result = new java.lang.String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
/**
* 分割字符串,全部分割
*/
public java.lang.String[] split(java.lang.String regex) {
return split(regex, 0);
}
- toUpperCase, trim,format,toCharArray相关方法
/**
* 全部转小写,使用默认的Locale
* locale: 国际化类
* 例如: Locale locale11 = new Locale("en");//英语
*/
public String toLowerCase() {
return toLowerCase(Locale.getDefault());
}
/**
* 全部转小写,根据locale参数
*/
public String toLowerCase(Locale locale) {
return isLatin1() ? StringLatin1.toLowerCase(this, value, locale)
: StringUTF16.toLowerCase(this, value, locale);
}
/**
* 转大写
*/
public String toUpperCase(Locale locale) {
return isLatin1() ? StringLatin1.toUpperCase(this, value, locale)
: StringUTF16.toUpperCase(this, value, locale);
}
public String toUpperCase() {
return toUpperCase(Locale.getDefault());
}
/**
* 去除两边的空格,使用两个while循环,分别从0 和 length-1 开始去掉空格''
*/
public String trim() {
String ret = isLatin1() ? StringLatin1.trim(value)
: StringUTF16.trim(value);
return ret == null ? this : ret;
}
/**
* byte数组转char数组
*/
public char[] toCharArray() {
return isLatin1() ? StringLatin1.toChars(value)
: StringUTF16.toChars(value);
}
/**
* 也是比较常用的方法,接受不定参数,将参数按顺序放到对应的 形式声明位置中,形成字符串
* 实现用到了Formatter类和FormatString接口定义的几种实现类,这个后面会专门讨论这个,这里不再细说
*/
public static String format(String format, Object... args) {
return new Formatter().format(format, args).toString();
}
public static String format(Locale l, String format, Object... args) {
return new Formatter(l).format(format, args).toString();
}
- valueOf相关方法
/**
* vauleOf 方法,都是其他类型转换成String类的方法,其中char类型参数调用的String的构造器,其他基本类型
* 调用的是对应包装类型的方法,比如 Integer.toString ,关于这部分逻辑会放到后面包装类里面解析,这里就不多说了
*/
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
public static String valueOf(char data[]) {
return new String(data);
}
public static String valueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
public static String copyValueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
public static String copyValueOf(char data[]) {
return new String(data);
}
public static String valueOf(boolean b) {
return b ? "true" : "false";
}
public static String valueOf(char c) {
if (COMPACT_STRINGS && StringLatin1.canEncode(c)) {
return new String(StringLatin1.toBytes(c), LATIN1);
}
return new String(StringUTF16.toBytes(c), UTF16);
}
public static String valueOf(int i) {
return Integer.toString(i);
}
public static String valueOf(long l) {
return Long.toString(l);
}
public static String valueOf(float f) {
return Float.toString(f);
}
public static String valueOf(double d) {
return Double.toString(d);
}
static String valueOfCodePoint(int codePoint) {
if (COMPACT_STRINGS && StringLatin1.canEncode(codePoint)) {
return new String(StringLatin1.toBytes((char)codePoint), LATIN1);
} else if (Character.isBmpCodePoint(codePoint)) {
return new String(StringUTF16.toBytes((char)codePoint), UTF16);
} else if (Character.isSupplementaryCodePoint(codePoint)) {
return new String(StringUTF16.toBytesSupplementary(codePoint), UTF16);
}
throw new IllegalArgumentException(
format("Not a valid Unicode code point: 0x%X", codePoint));
}
- jdk8和jdk9新增的一些方法
/**
* join方法是JDK1.8加入的新函数,静态方法
* 这个方法就是跟split有些对立的函数,不过join是静态方法
* delimiter就是分割符,后面就是要追加的可变参数,比如str1,str2,str3
*
* 例子:String.join(",",new String("a"),new String("b"),new String("c"))
* output: "a,b,c"
*/
public static String join(java.lang.CharSequence delimiter, java.lang.CharSequence... elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
// Number of elements not likely worth Arrays.stream overhead.
//StringJoiner类里面维护了一个elts String数组
StringJoiner joiner = new StringJoiner(delimiter);
for (java.lang.CharSequence cs: elements) {
joiner.add(cs); //往elts数组添加字符
}
return joiner.toString();//遍历获取char数组,重新构造String对象 new String(chars)
}
/**
* jdk1.8新增方法,参数为可迭代对象
*/
public static java.lang.String join(java.lang.CharSequence delimiter,
Iterable<? extends java.lang.CharSequence> elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
StringJoiner joiner = new StringJoiner(delimiter);
for (java.lang.CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
/**
* jdk9 新增方法,获取IntStream,便于计算,转换后为int类型的unicode编码
*/
@Override
public IntStream chars() {
return StreamSupport.intStream(
isLatin1() ? new StringLatin1.CharsSpliterator(value, Spliterator.IMMUTABLE)
: new StringUTF16.CharsSpliterator(value, Spliterator.IMMUTABLE),
false);
}
/**
* jdk9 新增方法,获取IntStream,便于计算
*/
@Override
public IntStream codePoints() {
return StreamSupport.intStream(
isLatin1() ? new StringLatin1.CharsSpliterator(value, Spliterator.IMMUTABLE)
: new StringUTF16.CodePointsSpliterator(value, Spliterator.IMMUTABLE),
false);
}
- jdk11新增的一些方法
/**
* jdk11 新增方法,比trim更强大,会去除任何字符的首尾空白,trim只能去除英文的空格,trim里面方法只判断了' '
* 而strip调用的是下面 indexOfNonWhitespace 方法,还判断了
等空格换行符
*/
public String strip() {
java.lang.String ret = isLatin1() ? StringLatin1.strip(value)
: StringUTF16.strip(value);
return ret == null ? this : ret;
}
/**
* jdk11 新增方法,去除首部空格
*/
public String stripLeading() {
java.lang.String ret = isLatin1() ? StringLatin1.stripLeading(value)
: StringUTF16.stripLeading(value);
return ret == null ? this : ret;
}
/**
* jdk11 新增方法,去除尾部空格
*/
public String stripTrailing() {
java.lang.String ret = isLatin1() ? StringLatin1.stripTrailing(value)
: StringUTF16.stripTrailing(value);
return ret == null ? this : ret;
}
/**
* jdk11 新增方法,判断是否为空字符, 空格,换行符都是,之前的isEmpty只会判断空字符串,因为是直接获取length==0
* StringLatin1.indexOfNonWhitespace(value): 方法的一段实现:
* 空格, 换行符 空白字符串(包括
tab键等)
* if (ch != ' ' && ch != ' ' && !Character.isWhitespace(ch)) {
* break;
* }
*/
public boolean isBlank() {
return indexOfNonWhitespace() == length();
}
private int indexOfNonWhitespace() {
if (isLatin1()) {
return StringLatin1.indexOfNonWhitespace(value);
} else {
return StringUTF16.indexOfNonWhitespace(value);
}
}
/**
* jdk11 新增方法,以换行符分割,再转换为流,便于操作计算,比如求行数这个API就十分方便,实现后面Stream类细讲
*/
public Stream<String> lines() {
return isLatin1() ? StringLatin1.lines(value)
: StringUTF16.lines(value);
}
/**
* jdk11 新增方法,复制字符串,实现还是使用数组copy
*/
public String repeat(int count) {
if (count < 0) {
throw new IllegalArgumentException("count is negative: " + count);
}
if (count == 1) {
return this;
}
final int len = value.length;
if (len == 0 || count == 0) {
return "";
}
if (len == 1) {
final byte[] single = new byte[count];
Arrays.fill(single, value[0]);
return new String(single, coder);
}
if (Integer.MAX_VALUE / count < len) {
throw new OutOfMemoryError("Repeating " + len + " bytes String " + count +
" times will produce a String exceeding maximum size.");
}
final int limit = len * count;
final byte[] multiple = new byte[limit];
System.arraycopy(value, 0, multiple, 0, len);
int copied = len;
for (; copied < limit - copied; copied <<= 1) {
System.arraycopy(multiple, 0, multiple, copied, copied);
}
System.arraycopy(multiple, 0, multiple, copied, limit - copied);
return new String(multiple, coder);
}
- intern()方法
参考下面五总结第一个
4 内部类
五 总结
1 intern 方法解析
这里再写一遍:
在1.6中,常量池在方法区,intern()会把首次遇到的字符串实例复制到永久代中,返回的也是这个永久代中字符串实例的引用;
而在1.7,1.8中,String 的 intern 方法不会再复制实例到常量池中,如果不存在,则这个String肯定在堆中,则将当前实例的引用复制到实例中并返回该引用,如果存在则直接返回该实例
//intern() 解析
public void test01Intern(){
String s = new String("1");//生成堆中对象和常量池中1,常量池中有1
s.intern();
String s2 = "1";// 返回常量池引用
System.out.println(s == s.intern());// jdk1.6 false jdk1.7以上 false
System.out.println(s == s2);// jdk1.6 false jdk1.7以上 false
}
public void test01Intern02(){
String s3 = new String("2") + new String("3");//生成堆中2和3,23,常量池中只有2和3
s3.intern();// 1.7 会在常量池中添加 s3的引用 1.6 直接在常量池添加23实例
String s4 = "23"; //1.7 返回 s3的引用 1.6返回常量池实例的引用
System.out.println(s3 == s3.intern());
System.out.println(s3 == s4);
/**
* jdk1.6: false
* false
* jdk1.7以上: true
* true
*/
}
public void test01Intern03(){
String s3 = new String("2") + new String("3");
String s4 = "23"; //直接在常量池中创建55实例
s3.intern();// 返回常量池中实例的引用
System.out.println(s3 == s3.intern());// jdk1.6 false jdk1.7以上 false
System.out.println(s3 == s4);// jdk1.6 false jdk1.7以上 false
/**
* jdk1.6: false
* false
* jdk1.7以上: false
* false
*/
}
2 常见创建几个对象问题
算是比较常见的面试题了
public void test01Intern(){
String s = new String("1");//生成堆中对象和常量池中1,常量池中有1
s.intern();
String s2 = "1";// 返回常量池引用
System.out.println(s == s.intern());// jdk1.6 false jdk1.7以上 false
System.out.println(s == s2);// jdk1.6 false jdk1.7以上 false
}
public void testBase(){
/**
* 创建一个或者两个,如果常量池中存在,堆里创建一个
* 如果不存在,在常量池中创建一个,堆里创建一个
*/
String s=new String("1");
String s1="2";//若存在,直接返回引用,不存在,在常量池中创建一个并返回引用
String a1 = new String("AA");
String a2 = new String("AA");
System.out.println(a1 == a2); //false,堆中创建两个对象,不相等
//堆里生成了两个对象,一个 string的hou,和一个StringBuffer的houzheng,常量池中只有一个hou
String str=new String("hou")+"zheng";
//证明如下:
String zheng=new String("zh")+new String("eng");
zheng.intern();// 如果之前有zheng,则返回常量池引用,下面是false,如果没有,则返回堆里面引用,下面为true
System.out.println(zheng==zheng.intern());// true
}
3 关于 + 拼接创建对象问题
使用+ 拼接String生成String对象实例测试代码:
// 拼接对象+ 创建问题举例
public void testNewString(){
String a1 = "AA" + "BB";//在常量池上创建常量AABB,并返回AABB,对于字符串的+连接编译期会直接优化直接编译成AABB
String a="A";
String a2=a+"A";//只在堆里创建了一个AA,常量池没有
System.out.println(a2.intern() == a2);// true
String a4 = new String("CC") + new String("DD"); //在堆上创建对象CC、DD和CCDD,在常量池上创建常量CC和DD
a4.intern();// 将堆中的CCDD引用加入常量池
String a5 = "CCDD"; // 返回引用
System.out.println(a4 == a5); //都是引用,true
String a6 = new String("EE") + new String("FF"); //在堆上创建对象EE、FF和EEFF,在常量池上创建常量EE和FF
String a7 = "EEFF"; // 常量池中创建EEFF
System.out.println(a6 == a7); //a6是堆中引用,a7是常量池中实例,false
String str1 = "a";
String str2 = "b";
//下面这句被Java编译器做了优化, 实际上使用StringBuilder实现的(不在堆里生成str1和str2对象)
// 字符串引用的+ 连接, 编译期无法优化,只能运行时候动态赋值引用返回
//该语句只在堆中生成一个对象(str4),没有在常量池生成字符串实例,因为StringBuffer是可变的,不会在常量池生成
String str4 = str1 + str2;
//String str5="ab"; 如果有这句,则下面会变成false,证明 str4没有在常量池生成字符串
System.out.println(str4.intern()==str4);// true
/**
* 关于+ 总结:
* String s = "a" + "b" + "c";
* 就等价于String s = "abc";
* String a = "a";
* String b = "b";
* String c = "c";
* String s = a + b + c;
* 这个就不一样了,最终结果等于:
* StringBuffer temp = new StringBuffer();
* temp.append(a).append(b).append(c);
* String s = temp.toString();
* 所以for循环里直接用 + 拼接效率很低,因为每次都会创建String对象,如果用StringBuffer只会创建一个对象
*/
}
4 final修饰String问题
fainl修饰String变量的几种情况:
// final 修饰
public void test03(){
//对于final修饰的变量(不是new String创建的),它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中,
final String x="X";
String xy=x + "Y"; // 如果拼接的全部变量都是final修饰或者字符串常量(即非引用),编译时候被解析成一个常量,并非StringBuffer对象
String hou="XY";
System.out.println(hou == xy); //true
final String a=new String("a");
String b=a+"b"; // 堆里引用
String ab="ab";// 常量
System.out.println(b==ab);// false
final String s1=getS1();// 编译期无法确定,运行时动态分配内存到堆
String s2=s1+"2";
String s3="12";
System.out.println(s2==s3);// false
final String h=new String("h");
final String o=new String("o");
String zheng=h+o;
String ho="ho";
System.out.println(ho==zheng);// false
}
private String getS1() { return "1"; }