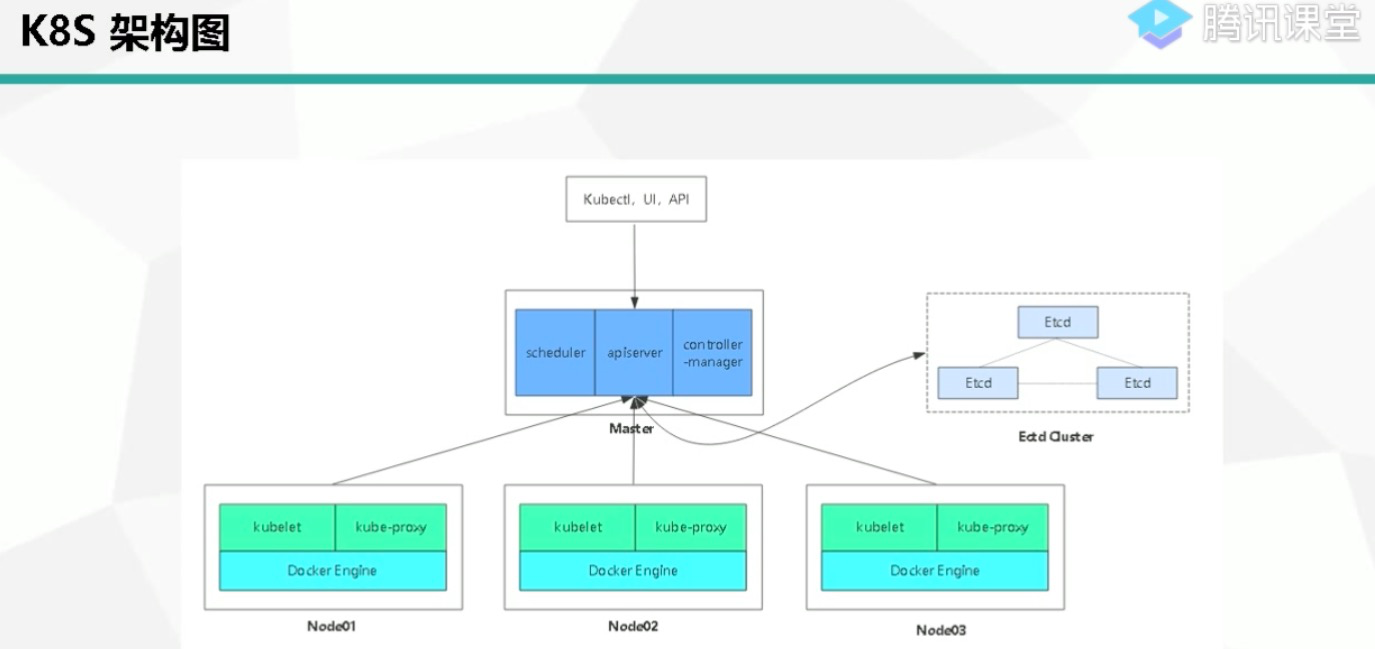
一、k8s集群组成
1、k8s集群主要分为master、node、etcd集群
master //负责集群管理,高可用集群副本数量最好>=3 奇数个
node //负责计算,跑任务
etcd //k8s的元数据库
2、k8smaster组件
scheduler //调度器,接受任务,将任务分配到后方的node节点上的kubelet组件去完成工作,监听的端口为10250
apiserver //架构核心,接受客户请求,是用户kubectl指令的执行者,监听的端口为8080
controller-manager //控制器,维持pod副本期望数量,当node节点上的pod或者容器出现问题over了,负责再其他node节点创建一个一摸一样的容器继续提供服务
etcd //键值对存储数据库,存储k8s数据支持持久化
3、node组件
kubelet //负责完成apiserver下发的指令,完成用户的请求
kube-proxy //负责node容器网络,外界是无法访问docker容器,实现容器里的应用与外界交互
4、falnnel/weavenet网络插件
监听的端口2379
注册到etcd元数据库中的key为"/atomic.io/netwoerk"
5、插件
CoreDNS //为k8s集群中的svc创建一个域名和ip的对应关系解析
Dashboard //为k8s集群提供一个B/S结构的访问体系
Ingress controller //为k8s集群实现七层代理,可以通过主机名称和域名实现负载均衡
Federation //提供多个k8s集群统一管理功能
Prometheus //监控k8s
ELK //提供k8s日志统一分析接入平台
二、kubernetes 安装类型
1、源码编译安装,基于go语言;
2、二进制:安装步骤繁琐复杂,部署kubernetes组件清晰可见;
3、官方推荐kubeadm:安装步骤简单,依赖网络,部署kubernetes组件模糊;
4、minkube 依赖网络,适合开发;
5、yum安装最简单;
三、kebernetes 的权限认证
RBAC 认证体系
ssl证书,https协议
证书格式为pem
四、kubernetes版本升级
例如:小版本升级,1.10.3版本出现漏洞,1.10.4修复。1.10.3 升 1.10.4 只对apiserver组件升级,node节点kubelet不动,这样的好处是,修复后外界无法利用apiserver这个漏洞,业务跑在弄的节点kubelet上,升级过程不影响业务,还修复了k8s漏洞;
五、kubernetes监控
1、prometheus(普罗米修斯),依赖于官网插件进行监控;k8s原生支持prometheus监控,浏览器访问master节点可看到metic下有很多指标,node节点ip+端口号看到contaier下有容器指标,prometheus就是利用这些指标数据监控;
架构:
监控端:jobs服务可以按照监控端的软件安装对应的插件,比如mysql,redis,k8s等等,jobs服务监听本地地址+端口(9001)采集数据,通过metic(指标)生成url发送到prometheus server端;prometheus server端的配置文件可以设置jobs服务监控的地址和url;
核心:prometheus server从jobs服务采集到监听数据可以存到数据库/存储集群;
web界面:prometheus server端提供一个http server UI界面功能,也可以通过Grafana应用帮助prometheus出监控数据图像,提高UI界面的数据化;
报警端:Alertmanager插件,支持Email;
网络设备监控端:Pushgetway插件监听一个固定端口,主动到到网络设备端去取值,等待prometheus server端要;
2、Heapster
六、备份
1、卷:后段存储集群
2、etcd:高可用模式
七、日志
EFK //fluentd elasticsearch,附加插件
八、集群的高可用
kubernetes联邦集群,多个地区的k8s集群联动一体,通过联邦服务管理多个地区的k8s集群;
九、kubernetes dns
coredns,通过yaml文件创建安装;
十、kubernetes 包管理工具
helm:支持k8s应用模版,只要通过命令一键将应用部署到k8s集群中,再做配置,调试即可投入使用;
十一:kubernetes七层负载均衡 //k8s默认提供四层负载均衡
ingress controller
十二、kubernetes特性
service discovery and load balancing 服务的自动发现与负载均衡 //传统的负载均衡,需要手动配置一台物理机,启动web服务,再手动添加到前端的负载均衡器上重新reload下配置文件,过程繁琐麻烦。在k8s通过ployment控制调整pod副本数量就,可以实现调整后端web网站比如WordPress节点数量,负载业务需求;
self-healing 自愈 //传统模式,当一个应用启动在容器中,这个容器出现种种问题,导致容器死掉了,需要重新pull镜像,run起来后再做配置,过程比较复杂,服务持久化是问题。k8s通过master节点controller-manager随时监听各个node节点的容器健康状态,遇到容器问题不能提供服务,会自动起一个一摸一样的容器接替工作,在新的node节点上提供服务;
Automated rollouts and rollbacks 滚动升级和一键回滚 //滚动升级的宗旨是确保应用提供服务不间断,在客户无感知的基础上体验最新的应用版本。例如:当后段web节点有上千台背景,如果同时升级可能会出现代码问题影响业务服务,导致用户体验差的情况。通过滚动升级,就可以实现先升级一部分web节点上的应用版本,如果用户体验好,就继续分批次的升级;
Horizcintal scaling 弹性伸缩 //通过dloyment控制来控制node节点上的pod资源数量。阿里云平台ESS产品借鉴了k8s理念开发出来的;
十三、kubernetes应用场景
微服务 //
十四、kubernetes资源类型
1、Replication Controller //简称:rc,
负责node节点上的pod资源的副本数量,保证pod高可用;
负责node节点上的pod资源容器镜像版本滚动升级;
2、Service Controller //简称:svc
负责负载均衡和端口自动发现;
工作原理:
node ip/cluster ip也叫vip/pod ip
假设:当用户需要访问容器服务时,请求时经过node ip+30000端口 转发到cluster ip/vip+80端口,通过service资源负载或者是反向代理到后段pod ip+80端口,实现用户访问pod上的nginx容器;因为pod ip是随时可能应为删除,升级随时可能变化的,所以service会随时监视发现pod ip+端口状态;
3、Persistent Volume简称:pv /Persistent Volume Controller简称:pvc
负责node节点上pod的存储持久化,需要和共享存储nfs/ceph即RDB/阿里云oss/GlusterFS/
pv //为全局类型资源,不属于任何一个namespace空间命名,独立的资源类型,一个pv只能绑定一个pvc;
pvc //属于一个namespace空间下的一个资源单位,只属于一个pv管理;
工作原理:
k8s实现数据持久化,是通过pv挂在namespace下的pvc资源上;
4、Horizontal Pod Autoscaler 简称:hpa
负责k8s集群node节点上的pod自动弹性伸缩;
工作原理:hpa资源通过对node节点上的物理cpu和内存资源等进行监控(可以通过kubectl aotoscale $控制器名称 --max=$最大pod数量 --min=$最小pod数量 --namespace=$名称空间 --cpu-percent=$cpu最大负载百分比,后触发 );
这里资源层级,hpa > deployment > rc > pod ,根据资源层级逻辑来实现hpa自动发现弹性伸缩;
5、coredns 简称:dns
6、StatefulSet 控制器
1)pod会安装顺序部署和终结;
创建pod
statefulset会给创建的pod增加一个ID,按照循序创建,只有上一个创建成功并进入就绪的状态后,下一个pod才会开始创建;
删除pod
删除pod时会按照反序进行,只有上一个pod被完全释放后,再删除下一个;
2)pod 具有唯一的网络名称;
通过Headless服务,基于主机名称,每个pod都有对的网络地址,这个网络域时有Headless服务控制;使得网络域下面的pod都是稳定唯一的域名,集群就不会重新创建处新的pod为新成员了;
3)pod 能有稳定的持久存储;
statefulset中的每个pod可以有自己的独立的PersistentVolumeCiaim对象,即使pod被重新调度到其他节点上,原有的持久磁盘也会挂在到该pod上;
4)pod 能通过Headless服务访问到;
客户端可以通过服务的域名链接到任意pod上;