注意:包含Python层的网络只支持单个GPU训练!!!!!
Caffe 使得我们有了使用Python自定义层的能力,而不是通常的C++/CUDA。这是一个非常有用的特性,但它的文档记录不足,难以正确实现本演练将向您展示如何使用DIGHT来学习实现Python层。
注意:这个特性(自定义python层)在你是使用Cmake编译Caffe或者使用Deb 包来安装Caffe的时候自动被包含。如果你使用Make,你将需要将你的Makefile.config中的"WITH_PYTHON_LAYER := 1"解注释来启用它。
给MNIST添加遮挡
对于这个例子,我们将在MNIST数据集上训练LeNet,但是我们将建立一个python层,来实现在图片喂进网络之前,截取掉它的四分之一。这模拟遮挡的数据,这样将会训练出一个对遮挡更加鲁棒的模型。
比如 变成
变成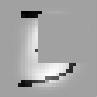
创建数据集
首先,仿照这个教程(https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md#creating-a-dataset)来使用DIGITS创建MNIST数据集(假设你还没有创建)
创建Python文件
接下来你将创建一个包含你的Pyhon层定义的Python文件。打开一个文本编辑器,然后创建一个包含如下内容的文件。
import caffe import random class BlankSquareLayer(caffe.Layer): def setup(self, bottom, top): assert len(bottom) == 1, 'requires a single layer.bottom' assert bottom[0].data.ndim >= 3, 'requires image data' assert len(top) == 1, 'requires a single layer.top' def reshape(self, bottom, top): # Copy shape from bottom top[0].reshape(*bottom[0].data.shape) def forward(self, bottom, top): # Copy all of the data top[0].data[...] = bottom[0].data[...] # Then zero-out one fourth of the image height = top[0].data.shape[-2] width = top[0].data.shape[-1] h_offset = random.randrange(height/2) w_offset = random.randrange(width/2) top[0].data[..., h_offset:(h_offset + height/2), w_offset:(w_offset + width/2), ] = 0 def backward(self, top, propagate_down, bottom): pass
其中,top和bottom是包含一个或者多个blob的列表或者数组,访问其中的每一个blob使用下标index,如top[index],访问其中的数据使用top[index].data,也就是一个四维向量[N,C,H,W]。
创建一个模型
注意:如果你以前没有使用DIGITS创建一个模型,在创建之前,你可以参照教程(https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md#training-a-model)学习。
- 点击主页上的
New Model > Images > Classification。 - 从数据集列表中选择MNIST数据集。
- 单击“
Use client side file”,并选择先前创建的Python文件。 - 点击
LeNetunderStandard Networks > Caffe。 - 点击右边显示的
Customize链接。
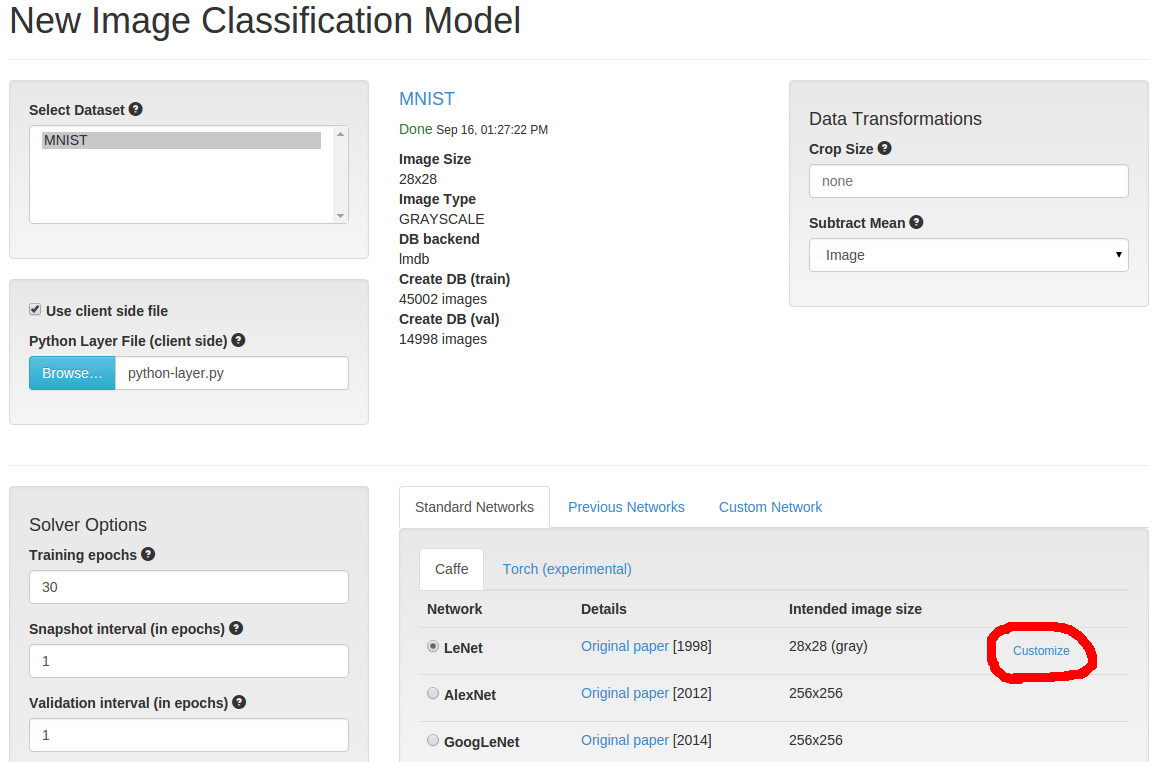
这将把我们带到一个窗口,我们可以自定义LeNet来添加自定义的Python层。我们将在scale层和conv层之间插入我们的层。找到这些层(从顶部的几行),并插入这段prototxt代码的片段:
layer {
name: "blank_square"
type: "Python"
bottom: "scaled"
top: "scaled"
python_param {
module: "digits_python_layers"
layer: "BlankSquareLayer"
}
}
当你点击Visualize,你将看到如下图:
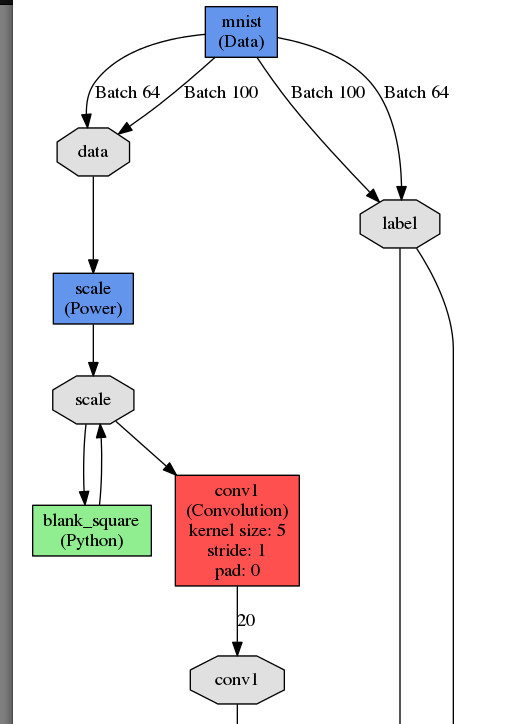
然后给模型一个名字,点击Create。你将会看到模型训练会话开始。如果你注意,你你将会发现这个模型会比默认的LeNet网络精度低,这是为什么呢?
注意:当前的caffe版本不支持在有Python层的网络上使用多GPU。如果你向使用Python层,那么你需要使用但GPU来训练。详见:https://github.com/BVLC/caffe/issues/2936
测试模型
现在开始比较有趣的部分。在MNIST测试集中选择一张图片,然后将它上传到 Test a single image(在页面的底下)
然后点击Show visualizations 和 statistics! 原始的图片将显示在左上,然后是它的预测类型。在Visualization 列,你会看到减去均值的图像作为数据激活的结果。
就在它下面,你会看到将图像从[0~255 ]缩小到[-1~1 ]的结果。你也会看到一个随机的四分之一的图像已经被删除-这是得益于我们的Python层!
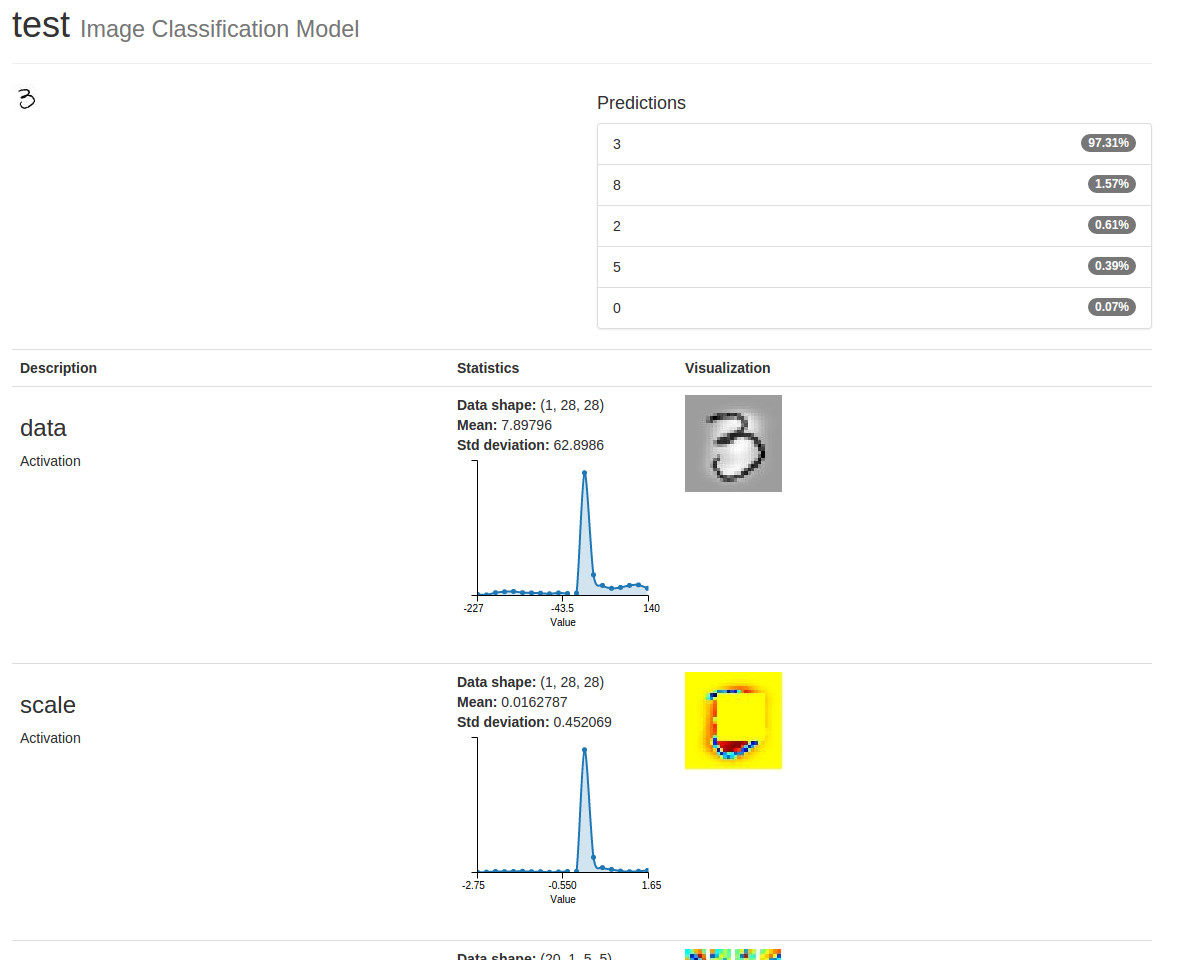
注意:第二个激活显示为彩色热图,即使底层数据仍然是单通道的,并且可以显示为灰度图像。“数据”激活被视为一种特殊情况,所有其他激活都被转换为热图。