计算机组成
7 流水线处理器
7.1 流水线的基本原理

流水线作为一种生产管理的模式,对于提高生产效率有着非常大的帮助,最早是兴起于汽车制造厂,现在已在很多的行业得到了广泛的应用。 那在处理器设计当中也借鉴了流水线的概念,以提升性能。今天我们就来看一看流水线处理器是如何设计的。

这位老朋友大家还记得吧?他曾经为我们展示过精湛的厨艺。那今天我们就再来欣赏一下他做菜的过程。他做菜分为这么几步,首先是洗菜,然后是切菜,第三步是炒菜,最后是装盘。我们假设这每一步都要花费1分钟,那这位厨师做一道菜就需要4分钟,那如果他总共做四道菜,就需要16分钟。现在呢,他掌勺的这个小餐馆生意非常好,客人很多,但是大家抱怨上菜太慢了,这怎么办呢?而我正好是这个餐馆的老板,我就得思考如何解决这个问题。首先我发现,在我能请得起的厨师当中,这位大厨已经是动作很快的了。所以,我就想从生产管理模式方面做一些改变。 那现在当然是非流水线的操作方式,那如何来改造成流水线的操作。
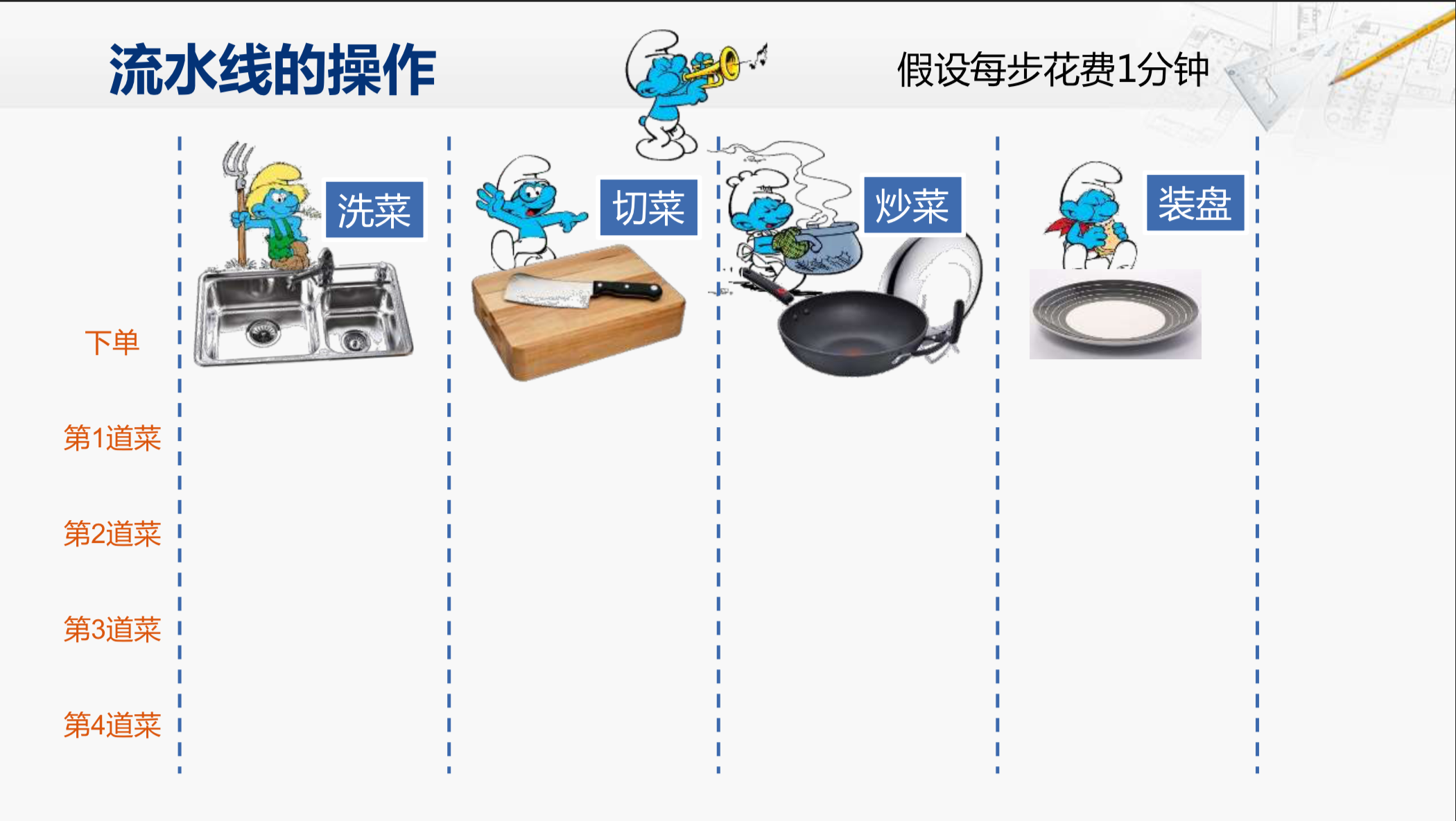
我们先来看一看这个厨房里有哪些用具。我们有洗菜用的水池,切菜用的刀和板,炒菜用的厨具,还有最后装盘的容器。那在刚才那位大厨的工作过程中,在每一个时刻他都只能使用其中的一样,另外三样都是空闲的。那看来从硬性条件来说,是适合改造成流水线的操作了。那我刚才说了,我这是一个小本经营,我没办法供四个厨师分别来做这四件事情,可以从另一个角度来说,如果我雇得起四个这样的大厨,我还不如让他们同时做四道菜呢,没必要这么麻烦,引入什么流水线的操作。那怎么办呢?那我就把这个大厨给解雇了,然后用同样的钱雇来四个人。现在大厨很全能,什么都会干,而新雇的这四位每一位只会干一种工作,那好,现在人员设备配置到位,那我就希望这四个步骤能够流水化地操作起来。 他们每一个人在做完自己手头的工作之后,将完成的成果交给下一个阶段继续进行下一步的操作,当然这样的交接需要一个统一的指挥,所以还得有一个发号施令的人,这个人是不用新雇的。刚才那位大厨每四分钟做完一道菜,所以 这位司号员每四分钟吹一次号,以指挥那位大厨去做下一道菜。而现在我们假设每个步骤和刚才那个大厨工作的方式一样,同样也要花费一分钟的时间,所以这司号员要改成每一分钟吹一次号,流水线上的工作人员每听到号响,就将自己的工作成果转交给下一阶段的人,当然,他必须保证在号响之前,已经顺利地完成了自己的工作。 这个司号员就好比CPU当中的时钟,如果这么来看,那我们现在的时钟频率已经提升为原来的4倍了。那我们就来看一看我们新改造的这个厨房是如何工作的。
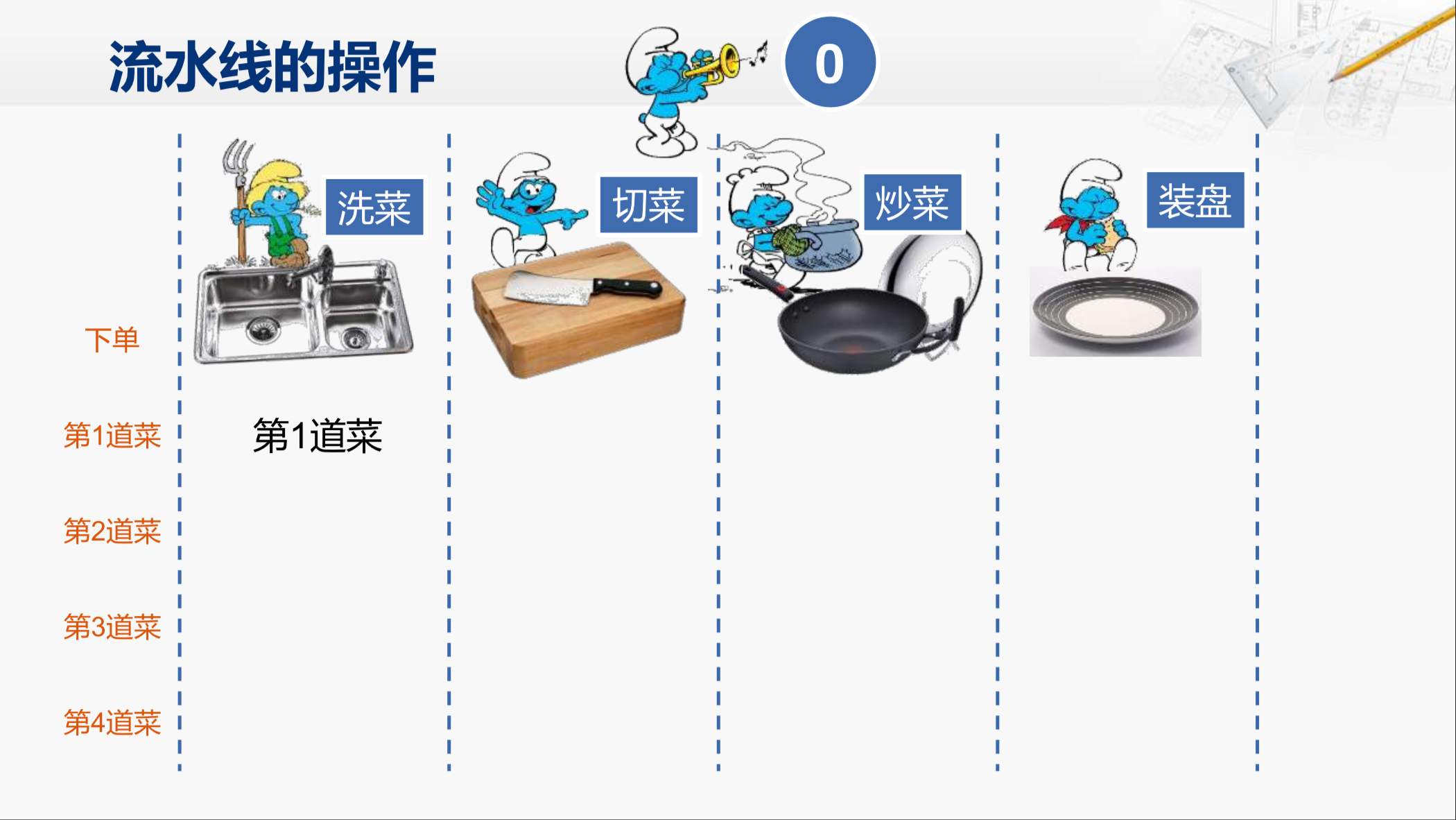
现在要做的菜单已经送过来了,工作开始。
首先第一道菜的原料送到洗菜的环节,这时候后面的各个环节都处于空闲状态,一分钟之后,洗菜完成。
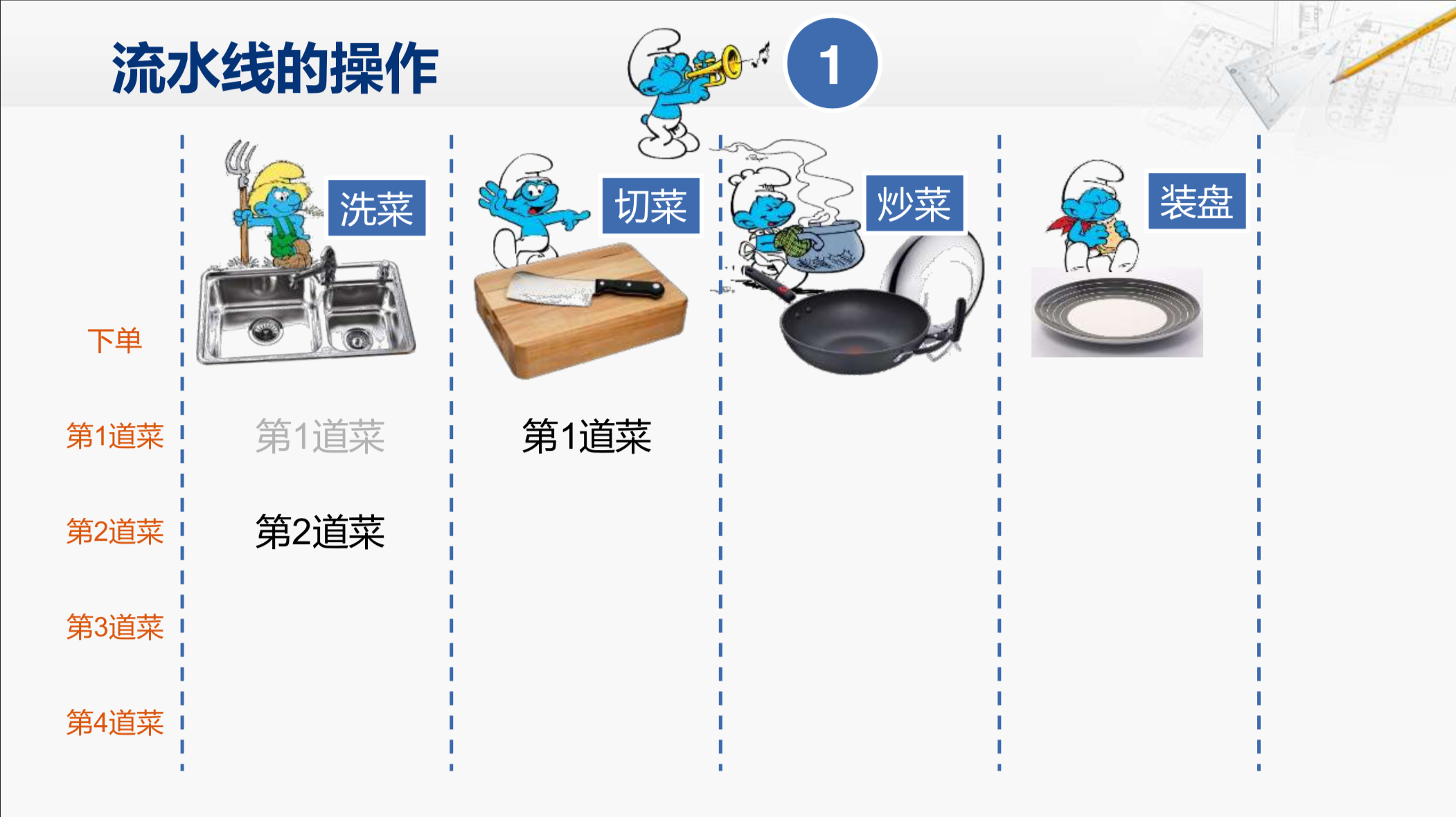
第一道菜的原料进入切菜环节,与此同时,第二道菜的原料进入洗菜环节。然后再过了一分钟,第一道菜已经切完了,与此同时,第二道菜也洗完了。
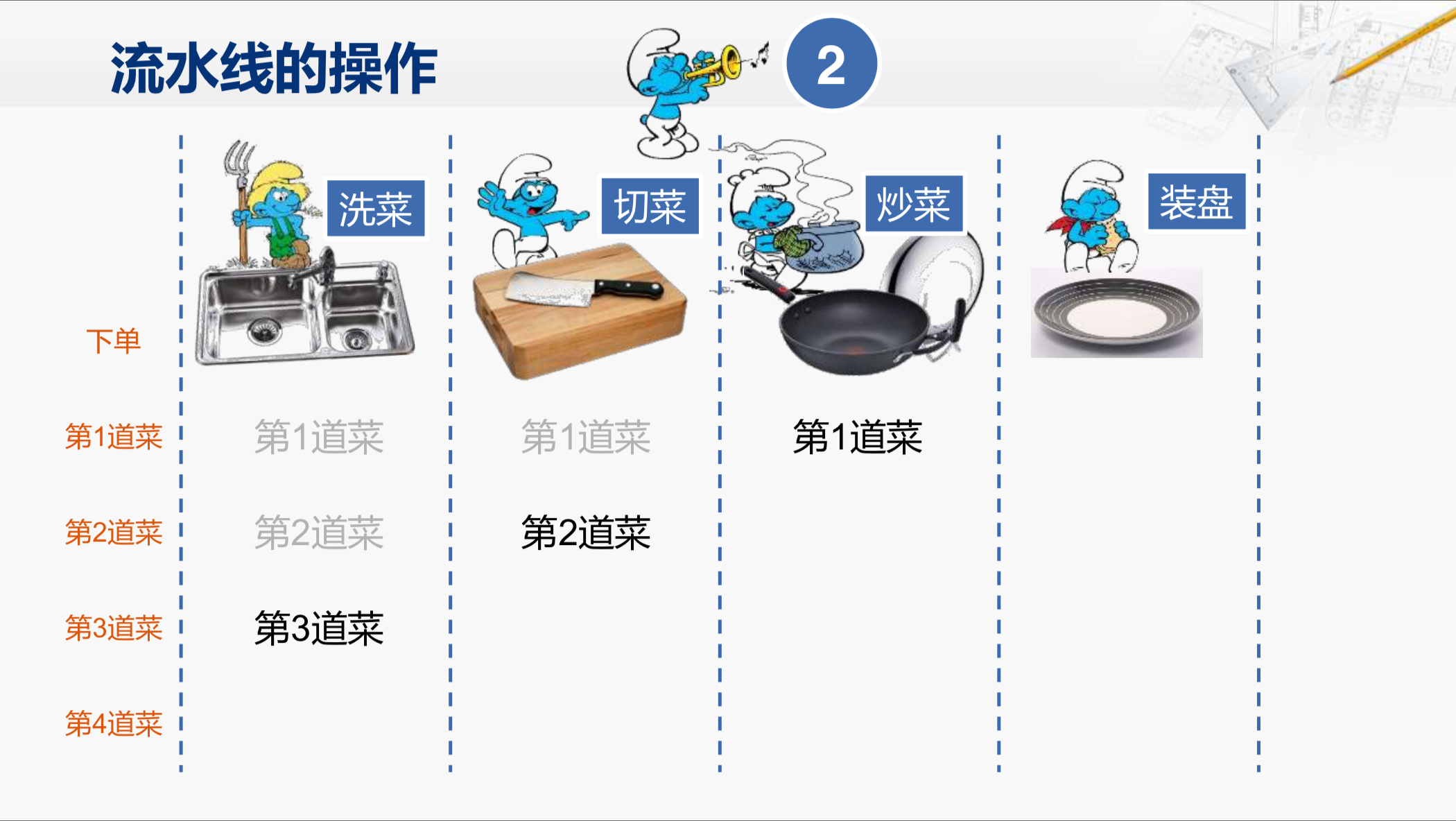
当迎来下一次号响的时候,第一道菜就会进入炒菜环节,第二道菜进入切菜环节,同时第三道菜进入洗菜环节,然后再过一分钟。
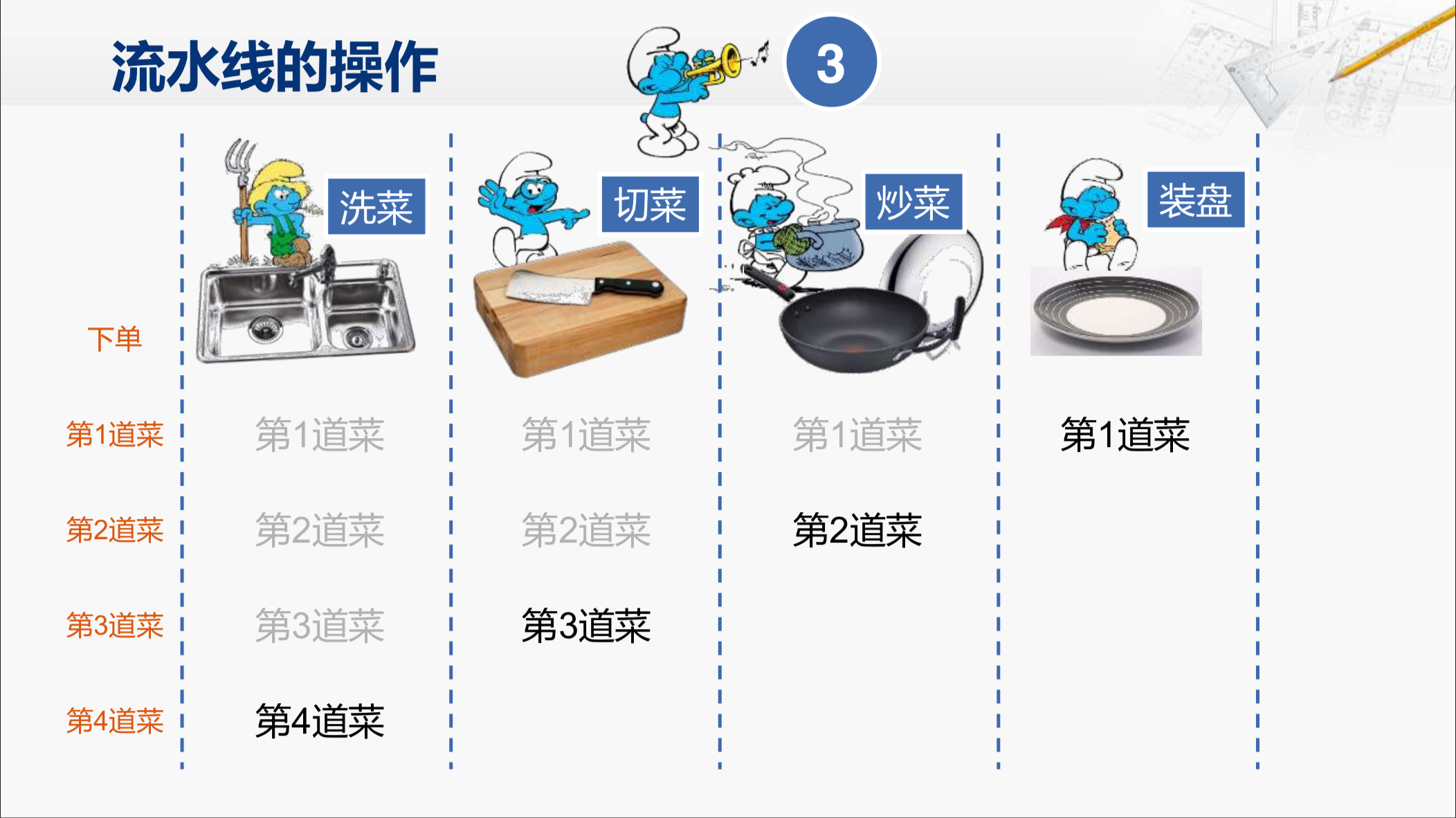
四道菜都进入了流水线当中,这个时候整条流水线的各个环节都开始工作了,那我们就可以说,这个流水线已经被填满了。而之前的这个过程就是填充流水线的过程,那再过一分钟。

第一道菜就完成了所有的工序,可以上菜了。而且之后每过一分钟,我们都可以上一道菜。

第2道

第3道

然后是第4道,7分钟后,这四道菜都完成了。那因为我们目前的任务只有四道菜,所以在刚才流水线被填满之后,又经历了一个流水线被排空的过程。当然如果这餐馆的客人很多,源源不断的有要做的菜单送来,那这个流水线就可以一直保持着充满的状态,每分钟都能送出一盘菜来。

那我们就来分析一下这个流水线的性能。现在我们采用这样的流水线的方式,做四道菜用了7分钟,平均每道菜用时不到2分钟,而且在流水线填满之后,可以做到每一分钟上一道菜。而之前采用非流水线的方式,是每四分钟才能上一道菜,那如果我们能保证流水线长期处于填满的状况,那现在的性能就可以达到原先的4倍,而我们的硬件资源的投入并没有明显的变化。当然我们要注意的是,采用流水线的方式,虽然可以做到每分钟上一道菜,但是单独针对某一道菜,其实还是需要4分钟,这个时间并没有缩短。那看完了这个厨房的例子,我们再来看一看流水线的原理是如何运用到真实的处理器结构上的。
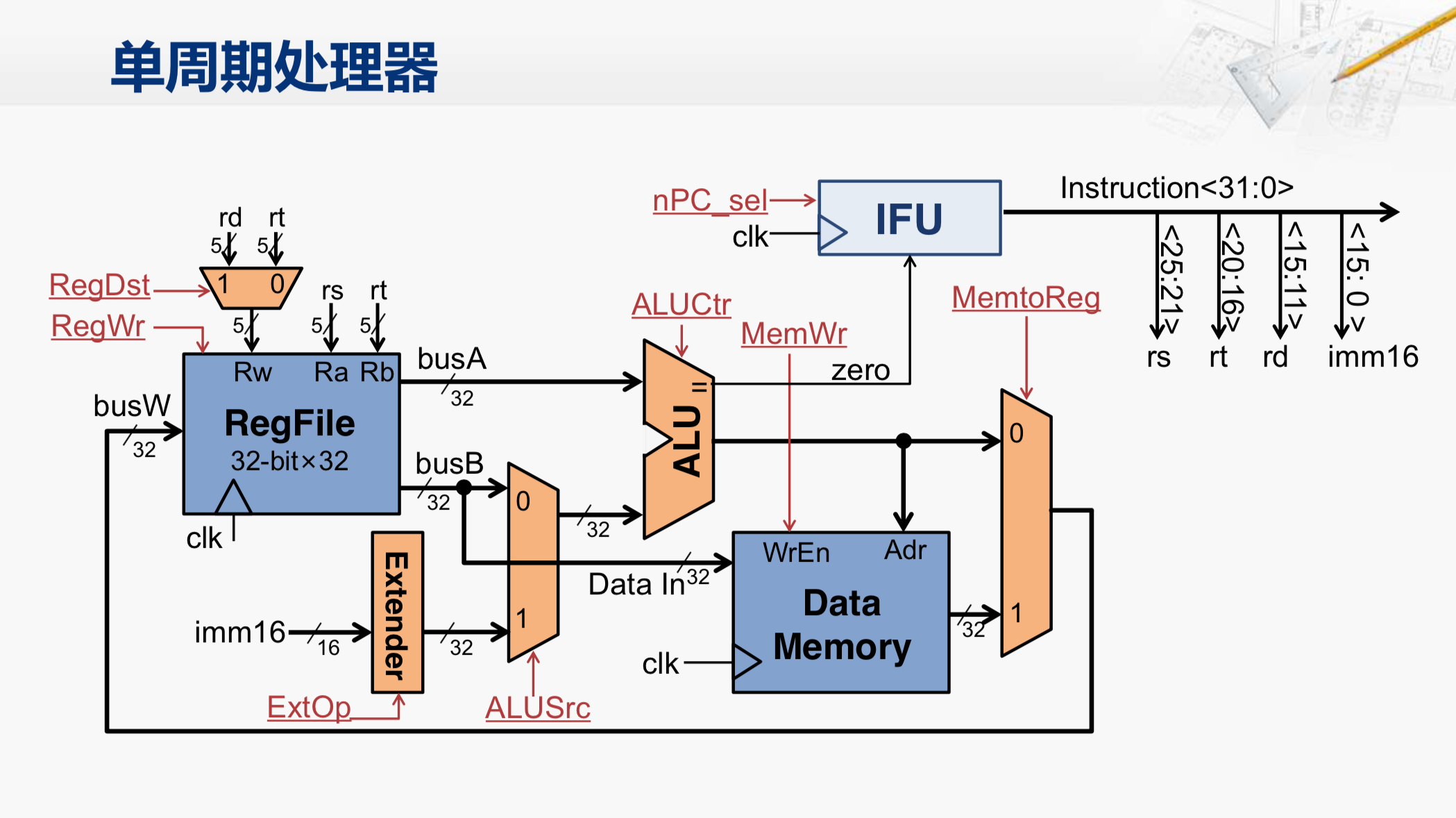
这是我们之前已经构建的单周期的处理器,我们是可以正确地运行一些MIPS的指令的。
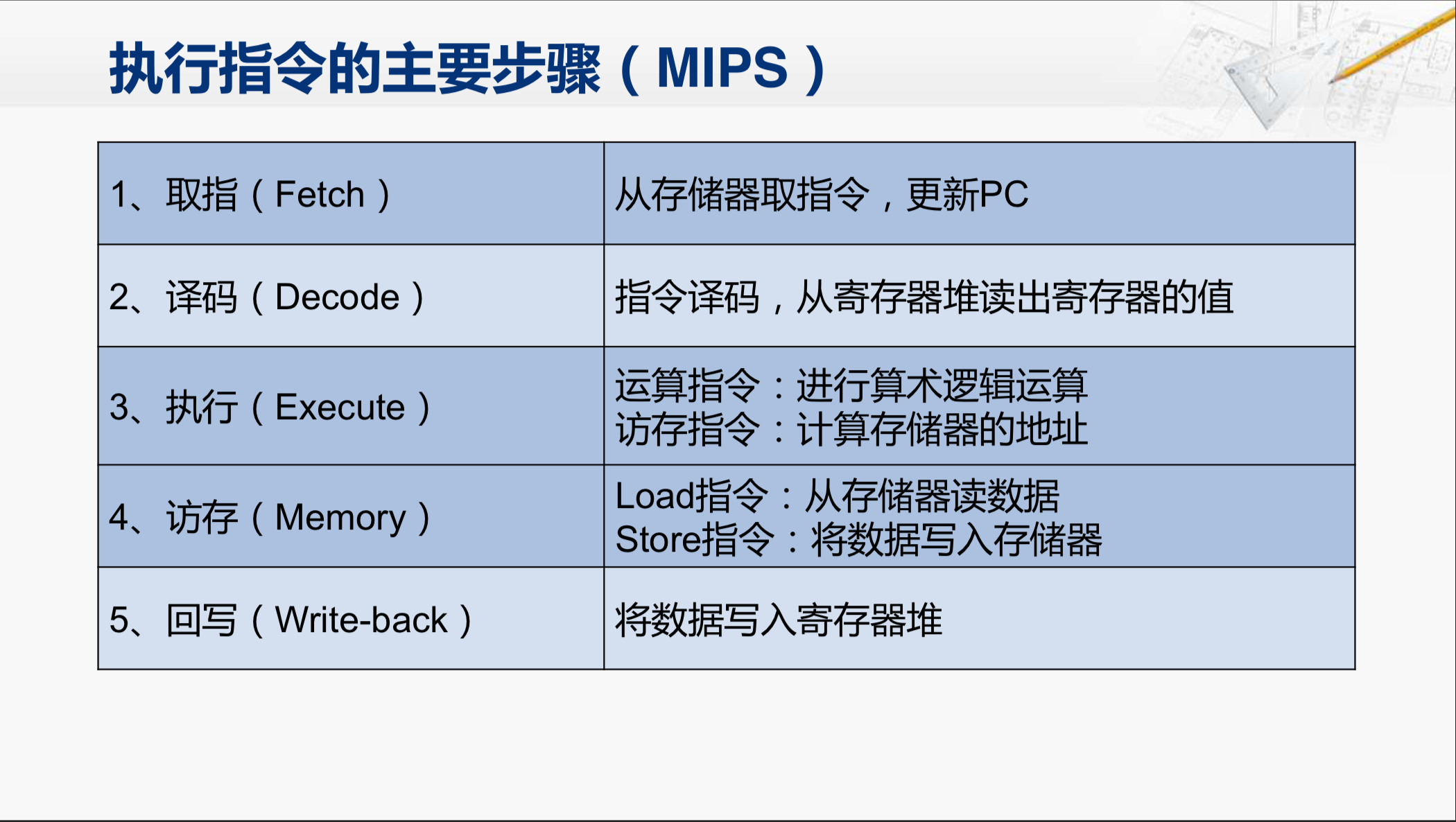
而MIPS指令的执行,可以分为这样5个步骤。
第一步是取指;
第二步是译码;
第三步是执行;
第四步是访存;
第五步是回写。
那我们还是结合数据通路图来看一看这样的步骤。
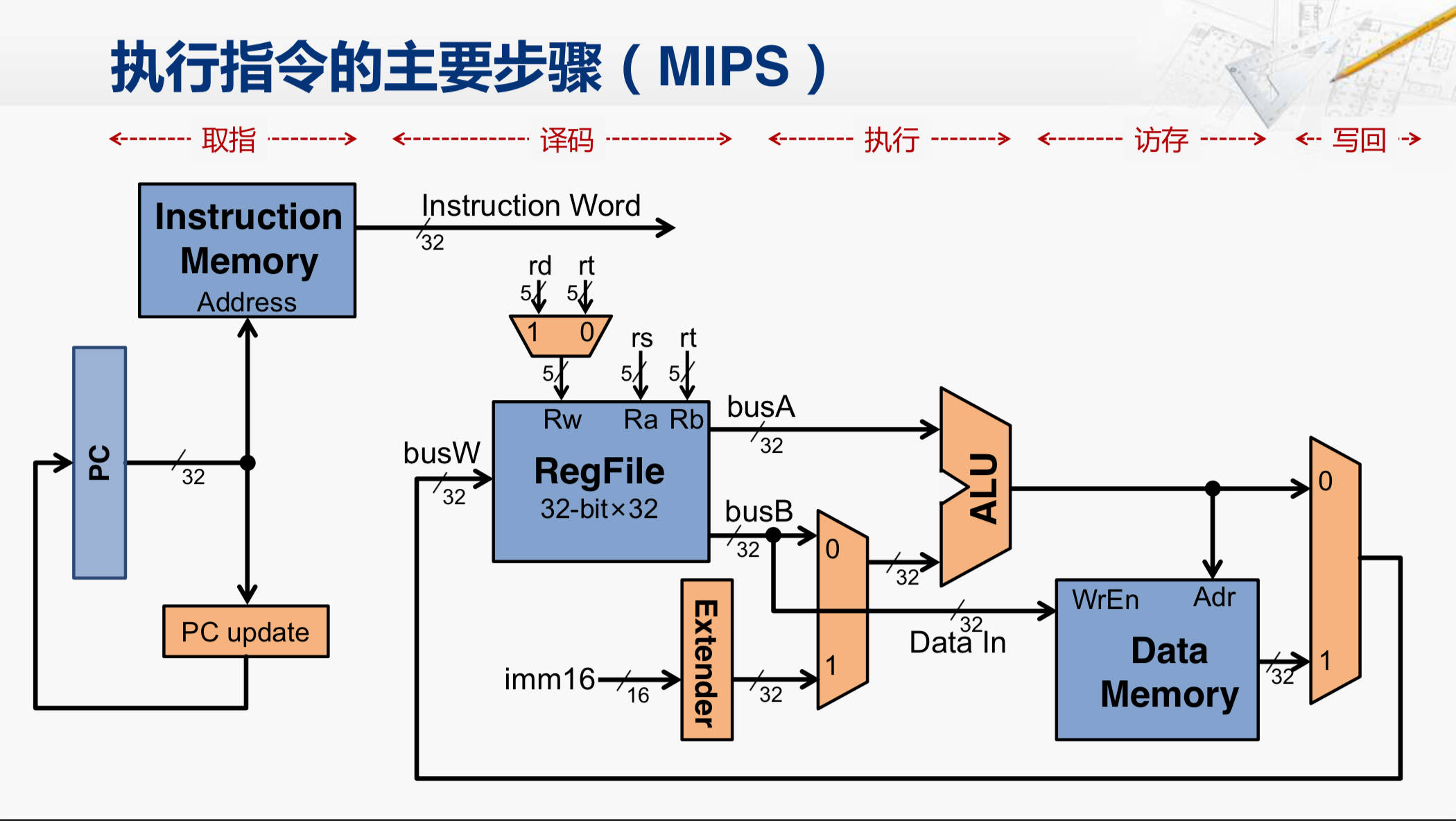
相比刚才的结构图,我们做了一点小小的变化,也就把IFU内部的结构进行适度的展开。
对照这个图,取指的阶段,就是用PC的值去访问指令存储器,从而得到指令的编码,同时还需要生成PC的更新值。
在译码阶段,不仅需要把指令编码进行分解,而且还需要从寄存器堆当中读出所需的寄存器的值。
第三步执行,主要在 ALU 当中完成。对于算术逻辑运算指令,就是完成对应的运算;而对于访存指令,则是计算出访存的地址。
第四步是访存,对于load指令,是从数据存储器当中读出对应的数据;而对于store指令,则是将数据送到数据存储器当中去;而其他指令在这一步没有实质的操作。
最后一步是写回,对于要改写寄存器的指令,在这一步会将数据写入到寄存器堆当中指定的位置。
我们要注意的是,虽然分成了这五步,但只是为了便于描述而已。所有的信号都必须要在这条指令执行的过程中保持稳定,例如从PC寄存器送到指令存储器的 这个地址信号,如果在指令执行完成前,它就发生了改变,那指令存储器送出的指令编码(Instruction Word)也就会发生改变,从而造成寄存器堆选取了不同编号的寄存器,送出了不同的值,ALU也可能执行了不同的操作,那这条指令就可能执行错误了。所以,对于单周期处理器来说,这一条指令执行的过程中,所有的信号都是必须要保持稳定的。
而我们要进行流水线的改造的话,我们同样也会发现,这不同阶段所用到的硬件资源基本上是相互独立的。如果我们能把指令存储器输出的指令编码事先保存下来,那我们就可以提前更新PC寄存器的值,并用这新的值去指令存储器当中取出一个新的指令,而在取新指令的同时,刚才取出的那条指令的编码就会被分解成不同位域,而寄存器堆也会根据输入送出对应寄存器的内容。所以,跟刚才的流水线原理的分析类似,如果我们想把这些硬件资源充分地利用起来,我们就需要把它拆分成若干个阶段。
那在这个电路的结构上要进行拆分,我们就在每一个阶段之间添加上寄存器,这就被称为流水线寄存器,这些寄存器用于保存前一个阶段要向后一个阶段传送的所有的信息。
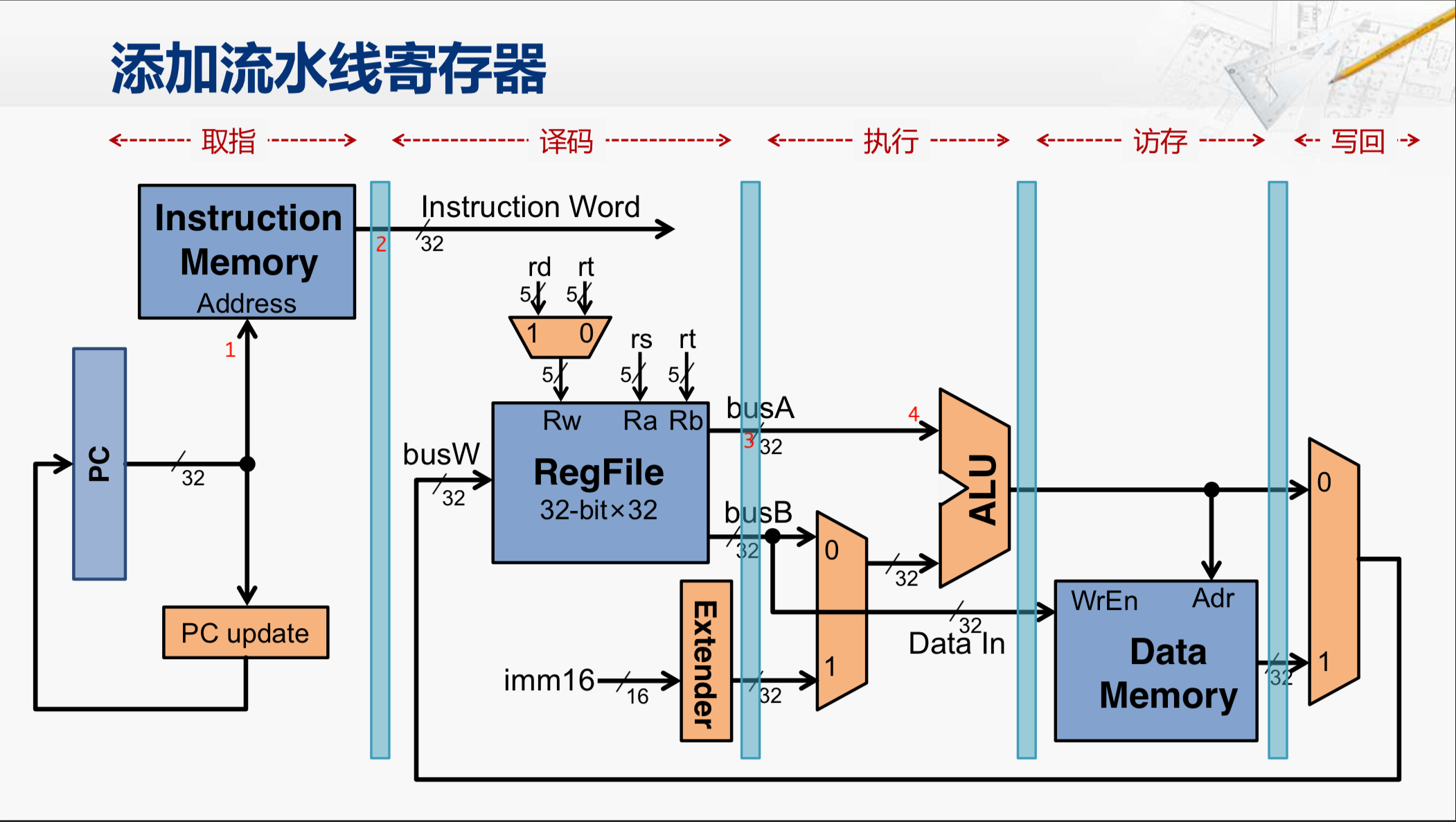
我们还是以取指到译码的这个阶段为例,我们将指令存储器的输出接到一个寄存器上(图中标号2处),那当一个时钟上升沿来临的时候,指令存储器输出的指令编码就会被保存到这个寄存器当中。那么在这个上升沿之后,指令存储器的地址输入(1处)如果发生改变,随之影响的指令存储器的输出,也不会被存到这个寄存器当中去(2处)。所以,在这个时候,我们可以用新的PC来访问这个指令存储器,从而得到下一条指令的二进制编码。而在这个同时,前一条指令的编码已经在这个(2处)流水线寄存器的输出上,并且经过相应的电路,切分成不同的位域。那其中有一个位域就会通过rs连到了寄存器堆,并且选中对应的寄存器,把其中的内容放到busA这根信号上,而这根信号也会被接到一个流水线的寄存器上(3处)。那么当下一个时钟上升沿来临的时候, 当前这条指令所需要的rs寄存器的值,就会被保存到这个(3处)流水线寄存器当中。与此同时,下一条指令的二进制编码也会保存到这个(2处)流水线寄存器中。那么在很短的
Clock-to-Q 时间之后,译码阶段所看到的指令的编码(Instruction Word)就已经变成第二条指令了。所以很快,寄存器堆得到的rs的寄存器编号也发生了改变,但是这没有关系,第一条指令所需的寄存器的值已经保存到了这个(3处)流水线寄存器当中,而且在这个时候,也应该会被送到了ALU的输入端(4处)。所以,这样通过添加流水线寄存器,我们就先从大体上把这个单周期处理器改造成了一个流水线的处理器。

那我们对这个流水线的处理器进行一些简单的性能分析。比如说我们要执行这么三条指令,我们把时间轴画出来,从0时刻开始,每一格是200ps。
那如果是在单周期的处理器上,执行一条指令需要这样五步,也就是取指、译码、执行、访存和写回。假设每个阶段都正好需要200ps,那执行完这条指令,就总共过去了1000ps,然后我们才可以执行第二条指令,又用去1000ps,然后是执行第三条指令,那这样每条指令都需要花1000ps的时间,这个单周期处理器,它的时钟周期就需要被设置为1000ps。从外界看来,这个处理器每1000ps可以完成一条指令。
而对于流水线处理器,我们同样来执行这三条指令。先看第一条指令,那要完成这条指令所需要的步骤是一样的,同样也需要这五步,也同样需要花1000ps的时间。但是不同在于,在过去200ps之后,当第一条指令完成了取指阶段,而进入到译码阶段的时候,实际上取指部件已经空闲下来,我们就可以开始第二条指令的取指工作,也就是说第二条指令在此时,已经开始执行了。同样,再过了200ps,第一条指令完成了译码,进入到了执行阶段,这样第二条指令也正好完成了取指,可以进入译码阶段,而此时,第三条指令的取指也可以开始了。这样对一个流水线处理器,虽然一条指令总共也是需要花1000ps,但是每200ps就可以开始执行一条指令,而且当流水线填满之后,每200ps也就可以完成一条指令。所以,对于这样一个流水线处理器,它的时钟周期可以设为200ps。因此,这个处理器的主频就是刚才这个单周期处理器的5倍。
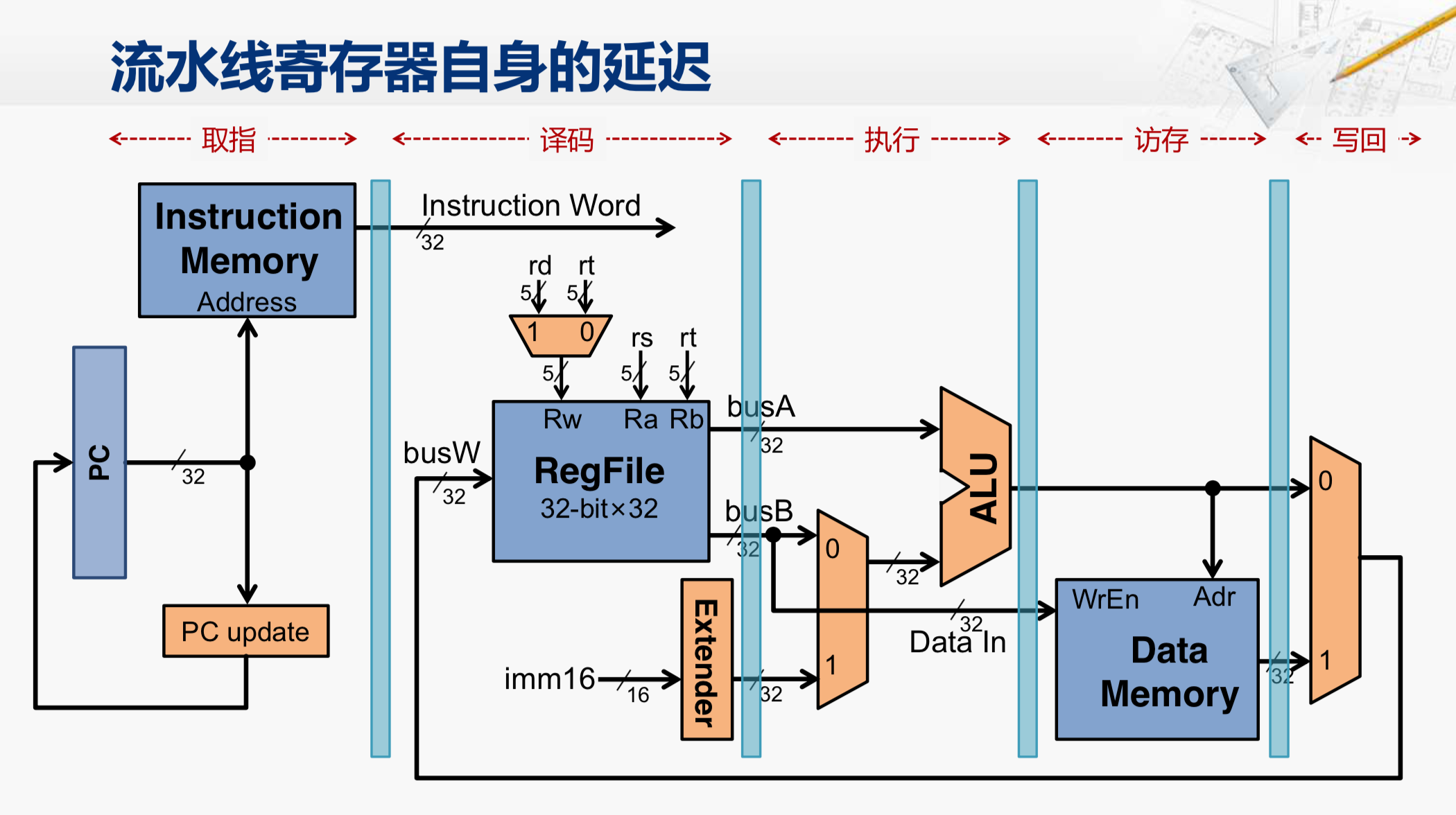
当然这只是理想情况,现实中的性能提升幅度并没有这么大, 其中一个原因就是这些新插入的流水线寄存器,它自身也会带来一些新的延迟。我们假设这些寄存器的延迟是50ps,那我们再来看一看这个处理器的性能有什么样的变化。

这是刚才没有考虑流水线寄存器延迟的情况下分析的性能表现,那如果我们加上流水线寄存器的延迟,同样还是执行这几条指令,那就需要每隔 250ps 才可以开始一条新的指令。所以,时钟周期应该设为250ps,而且对于每条指令本身来说,需要花1250ps(250*5,5个阶段每阶段时间开销一个时钟周期)才能够完成。在这一点上,是比刚才在单周期处理器还要更慢一些的。
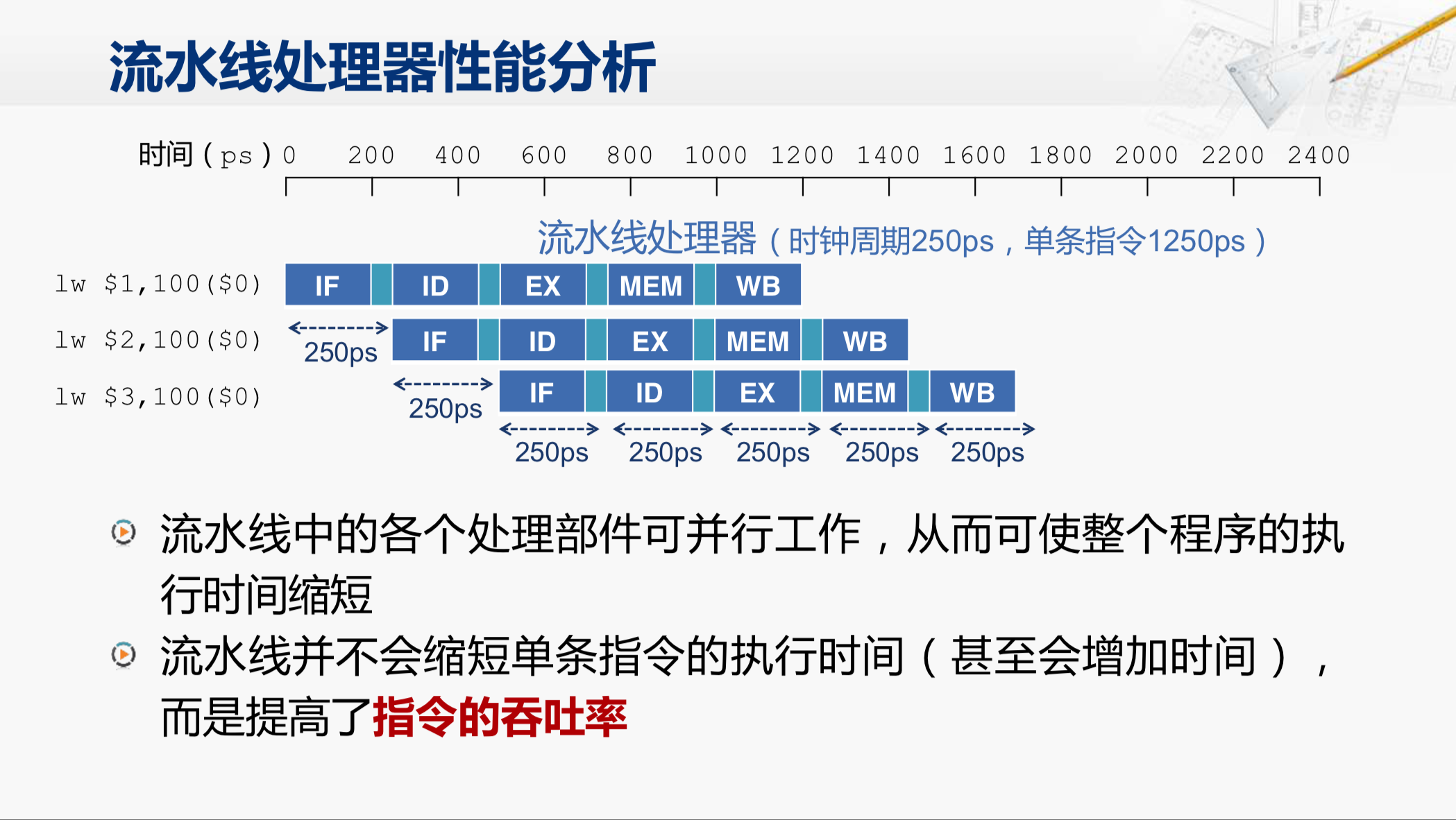
因此对于流水线处理器来说,因为各个处理部件可以并行工作,从而可以使得整个程序的执行时间缩短。但是流水线并不会缩短单条指令的执行时间,相反,还会增加这个时间。因此,采用流水线的方式,实际上是提高了指令的吞吐率,从而从整体上缩短了程序的执行时间,提高了系统的性能。

现在我们已经了解了流水线的基本原理,而且分析了一个五级流水线的大致框架,这也是早期流水线处理器的实现结构。后来,流水线处理器的设计又发生了很多的发展和变化,那我们在下一节将要进一步探讨这些问题。