python实战提升
1、 如何在列表、字典、集合中根据条件筛选数据?
python中for _ in range(10)与for i in range(10)有何区别
下划线表示 临时变量, 仅用一次,后面无需再用到
列表:
import random
# 生成一个随机数列表
#方法一:
# l = []
# for i in range(10):
# l.append(random.randint(-10,10))
# print(l)
#列表生成式,循环十次,要生成的列表的内容放最前边。
data = [random.randint(-10,10) for i in range(10)]
print(data)
# filter内置函数过滤
# ret = filter(lambda x:x>=0,data) # 返回一个对象
# for i in ret:
# print(i)
# filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素
# 进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件
# 的元素,返回由符合条件元素组成的新list。
# 列表推导式
l1 = [i for i in data if i > 0]
print(l1)
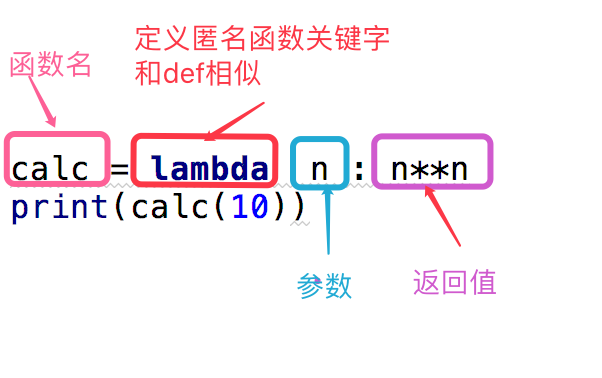
字典:
# 随机生成一个字典
d = {x:random.randint(60,100) for x in range(1,21)}
print(d)
# 字典生成式
dic = {k:v for k,v in d.items() if v >= 90}
print(dic)
集合:
data = [random.randint(-10,10) for _ in range(10)]
s = set(data)
print(s)
s1 = {x for x in s if x % 3 == 0}
print(s1)
2、 如何为元祖中的每个元素命名,提高程序可读性?
# 方法一 变量定义
NAME,AGE,MALE,EMAIL = range(4)
# print(NAME)
# 方法二
from collections import namedtuple
#namedtuple('名称', [属性list])
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
print(Point) # <class '__main__.Point'>
p = Point(1, 2)
print(p.x)
3、如何统计序列中元素的出现频率?
# 生成一个随机列表
from random import randint
# l = [randint(1,11) for _ in range(20)]
# print(l)
#
# d = dict.fromkeys(l,0)
# {11: 0, 9: 0, 1: 0, 2: 0, 4: 0, 10: 0, 5: 0, 6: 0, 8: 0}
# print(d)
#
# for i in l:
# d[i] += 1
# print(d)
# {11: 4, 9: 2, 1: 2, 2: 2, 4: 3, 10: 2, 5: 2, 6: 2, 8: 1}
# 根据字典的值进行排序
# 第一种方法
import random
# d = {x:random.randint(60,100) for x in range(1,11)}
# print(d) # {1: 76, 2: 85, 3: 80, 4: 100, 5: 79, 6: 77, 7: 80, 8: 68, 9: 67, 10: 98}
# 从小到大排序.总体思路:sorted函数可以对列表[]进行从小到大排序,对于字典{}
# dict,sorted函数只比较dict的key进行排序,所以要对dict进行调整变形。
# ret = sorted(d)
# print(ret) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# z=zip(d.values(),d.keys()) # z 是可迭代对象
# print(list(z))
# z = list(z)
# 在 Python 3.x 中为了减少内存,
# zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
# ret = sorted(z,reverse=True)
# print(ret)
# 第二种方法
# [(a1,b1,c1),(a2,b2,c2),(a3,b3,c3),(a4,b4,c4)……]
# sorted函数可以对这种集合进行指定元素排序。
# sorted(d.items(),key=lambda x:x[1]),第一个从参数是需要排序的列表,
# 第二个参数是指定key(列表中每一项的第几个元素)来进行排序。
# print(d.items())
#
# ret = sorted(d.items(),key=lambda x:x[1],reverse=True)
# print(ret)
# 第三种方法
# 利用collections的子类Counter从大到小排序
from collections import Counter
d = {x:random.randint(1,5) for x in range(1,11)}
ret = Counter(d).most_common()
print(ret)
ret = Counter(d).most_common(3)
print(ret)
import random
from collections import Counter
l = [random.randint(1,11) for _ in range(1,30)]
print(l) # [5, 9, 11, 11, 2, 8, 11, 2, 3, 5, 4, 7, 9, 9, 5, 11, 10, 6, 8, 11, 6, 11, 3, 11, 3, 11, 11, 5, 9]
obj = Counter(l)
print(obj) # Counter({11: 9, 5: 4, 9: 4, 3: 3, 2: 2, 8: 2, 6: 2, 4: 1, 7: 1, 10: 1})
print(obj.most_common(3)) # [(11, 9), (5, 4), (9, 4)]
英文词频的统计
import re
from collections import Counter
data = open('name').read()
l = re.split('W+',data)
print(l)
c = Counter(l)
print(c.most_common(5))
4、公共键
如何快速找到多个字典中的公共键?
from random import randint,sample
name = ['hou','liu','cluo','meixi','wu','alex']
# print(sample(name,randint(3,6)))
s1 = {x:randint(1,4) for x in sample(name,randint(3,6))}
print(s1)
s2 = {x:randint(1,4) for x in sample(name,randint(3,6))}
print(s2)
s3 = {x:randint(1,4) for x in sample(name,randint(3,6))}
print(s3)
ret = s1.keys() &s2.keys() &s3.keys()
print(ret)
多个字典:
l = [s1,s2,s3]
l3 = l[-1].keys()
l2 = [l3]
s_and = ['none',]
while l:
s = l.pop()
print(s.keys())
s_and[-1] = s.keys() & l2[-1]
l2[-1] = s.keys()
print(s_and)
5、 历史记录
使用deque,它是一个双端循环队列
程序退出时候,可以使用pickle将队列对象存入文件,再次运行程序是将其导入。