本次demo主题是使用keras对IMDB影评进行文本分类:
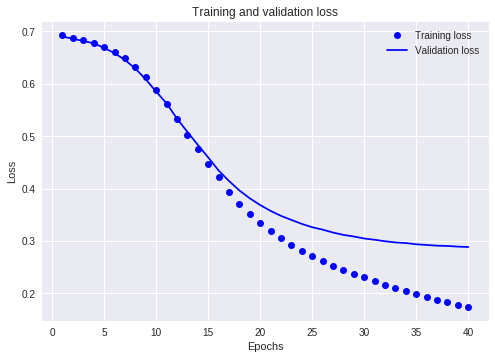
import tensorflow as tf from tensorflow import keras import numpy as np print(tf.__version__) imdb = keras.datasets.imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels))) print(train_data[0]) len(train_data[0]), len(train_data[1]) # A dictionary mapping words to an integer index word_index = imdb.get_word_index() # The first indices are reserved word_index = {k:(v+3) for k,v in word_index.items()} word_index["<PAD>"] = 0 word_index["<START>"] = 1 word_index["<UNK>"] = 2 # unknown word_index["<UNUSED>"] = 3 reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) #把数字序列转化为相应的字符串 def decode_review(text): return ' '.join([reverse_word_index.get(i, '?') for i in text]) #显示其中一个评价 decode_review(train_data[0]) #pad填充使其长度一样 train_data = keras.preprocessing.sequence.pad_sequences(train_data, value=word_index["<PAD>"], padding='post', maxlen=256) test_data = keras.preprocessing.sequence.pad_sequences(test_data, value=word_index["<PAD>"], padding='post', maxlen=256) len(train_data[0]), len(train_data[1]) print(train_data[0]) # input shape is the vocabulary count used for the movie reviews (10,000 words) vocab_size = 10000 #建立模型 model = keras.Sequential() model.add(keras.layers.Embedding(vocab_size, 16)) model.add(keras.layers.GlobalAveragePooling1D()) #对序列维度求平均,为每个示例返回固定长度的输出向量 model.add(keras.layers.Dense(16, activation=tf.nn.relu)) model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) #显示模型的概况 model.summary() model.compile(optimizer=tf.train.AdamOptimizer(), loss='binary_crossentropy', metrics=['accuracy']) #创建验证集 x_val = train_data[:10000] partial_x_train = train_data[10000:] y_val = train_labels[:10000] partial_y_train = train_labels[10000:] #训练 history = model.fit(partial_x_train, partial_y_train, epochs=40, batch_size=512, validation_data=(x_val, y_val), verbose=1) results = model.evaluate(test_data, test_labels) print(results) history_dict = history.history history_dict.keys() ##out:dict_keys(['val_loss', 'val_acc', 'loss', 'acc']) ##显示loss下降的图 import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) # "bo" is for "blue dot" plt.plot(epochs, loss, 'bo', label='Training loss') # b is for "solid blue line" plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show() ##显示accuracy上升的图 plt.clf() # clear figure acc_values = history_dict['acc'] val_acc_values = history_dict['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()
layers的概况
_________________________________________________________________
Layer (type) Output Shape Param
# =================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________