方法一:打印PDF表单以及在PDF中加入图片
需要的资料:
jar包:iTextAsian.jar ,itext-2.1.7.jar;
源码:
1 public static void main(String args[]) throws IOException, DocumentException { 2 String fileName = "D:/testPDF.pdf"; // pdf模板 3 InputStream input = new FileInputStream(new File(fileName)); 4 PdfReader reader = new PdfReader(input); 5 PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("D:/contract.pdf")); 6 AcroFields form = stamper.getAcroFields(); 7 fillData(form, data()); 8 stamper.setFormFlattening(true); 9 Image image = Image.getInstance("D:/testPhoto.jpg"); 10 image.scaleToFit(100, 125); 11 PdfContentByte content=null; 12 int pageCount=reader.getNumberOfPages();//获取PDF页数 13 System.out.println("pageCount="+pageCount); 14 content =stamper.getOverContent(pageCount); 15 image.setAbsolutePosition(100, 700); 16 content.addImage(image); 17 stamper.close(); 18 reader.close(); 19 } 20 21 public static void fillData(AcroFields fields, Map<String, String> data) throws IOException, DocumentException { 22 for (String key : data.keySet()) { 23 String value = data.get(key); 24 System.out.println(key+"= "+fields.getField(key)+" value="+value); 25 fields.setField(key, value); 26 } 27 } 28 29 public static Map<String, String> data() { 30 Map<String, String> data = new HashMap<String, String>(); 31 data.put("trueName", "xxxxxx"); 32 data.put("idCard", "xxxxxx"); 33 data.put("userName", "xxxx"); 34 data.put("address", "12"); 35 data.put("telephone", "123456"); 36 data.put("signName","xxx"); 37 return data; 38 }
注意以上引入的包一定是一下的方式,否则PDF表单中的字段不能赋值
//AcroFields import com.lowagie.text.DocumentException; import com.lowagie.text.Image; import com.lowagie.text.pdf.AcroFields; import com.lowagie.text.pdf.AcroFields.Item; import com.lowagie.text.pdf.PdfContentByte; import com.lowagie.text.pdf.PdfReader; import com.lowagie.text.pdf.PdfStamper;
制作PDF表单:
利用工具Adobe Acrobat制作PDF表单
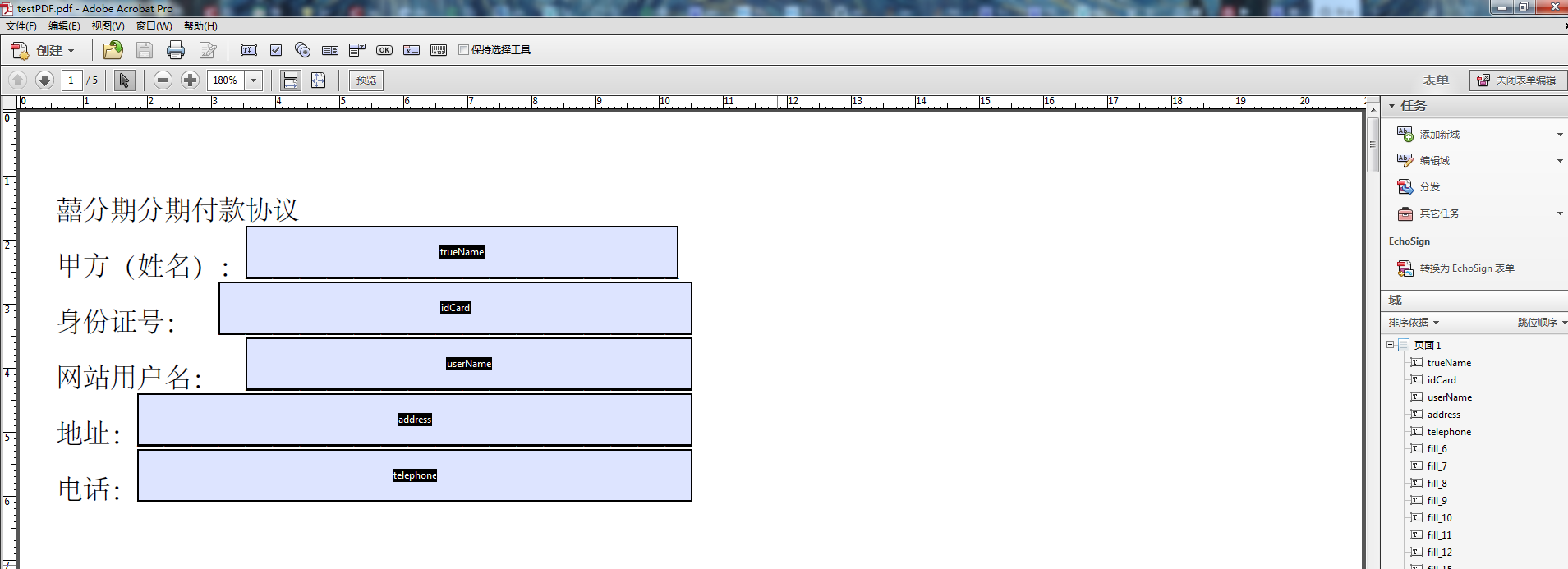
将制作好的表单保存到:D:/testPDF.pdf,这样点击运行代码会根据设置的字段添加对应的值。

注意:此方法中还包含怎样将图片随pdf打印出来,因为jar的原因,此种方法只能获得pdf的页数,不能获得某一个字段的具体位置,因此只能将其的位置初始化。
源码:
置于插入图片:还有一种能获取具体某一个字段的具体位置的方法,但是因为引入jar包的原因不能保证既满足读取pdf获取具体位置又能将PDF表单赋值
1 // 模板文件路径 2 String templatePath = "template.pdf"; 3 // 生成的文件路径 4 String targetPath = "target.pdf"; 5 // 书签名 6 String fieldName = "field"; 7 // 图片路径 8 String imagePath = "image.jpg"; 9 10 // 读取模板文件 11 InputStream input = new FileInputStream(new File(templatePath)); 12 PdfReader reader = new PdfReader(input); 13 PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(targetPath)); 14 // 提取pdf中的表单 15 AcroFields form = stamper.getAcroFields(); 16 form.addSubstitutionFont(BaseFont.createFont("STSong-Light","UniGB-UCS2-H", BaseFont.NOT_EMBEDDED)); 17 18 // 通过域名获取所在页和坐标,左下角为起点 19 int pageNo = form.getFieldPositions(fieldName).get(0).page; 20 Rectangle signRect = form.getFieldPositions(fieldName).get(0).position; 21 float x = signRect.getLeft(); 22 float y = signRect.getBottom(); 23 24 // 读图片 25 Image image = Image.getInstance(imagePath); 26 // 获取操作的页面 27 PdfContentByte under = stamper.getOverContent(pageNo); 28 // 根据域的大小缩放图片 29 image.scaleToFit(signRect.getWidth(), signRect.getHeight()); 30 // 添加图片 31 image.setAbsolutePosition(x, y); 32 under.addImage(image); 33 34 stamper.close(); 35 reader.close();
但引入的包:
import com.itextpdf.text.Document; import com.itextpdf.text.DocumentException; import com.itextpdf.text.pdf.PdfWriter; import com.itextpdf.tool.xml.XMLWorkerHelper;
只有这样以下方法才可用:
Rectangle signRect = form.getFieldPositions(fieldName).get(0).position;
方法二:将html页面打印成PDF
此种方法需要引入的jar包:itextpdf-5.3.2.jar, xmlworker-5.5.3。(注意:如果xmlworker版本不对会报:java.lang.NoSuchMethodError: com.itextpdf.tool.xml.html.pdfelement.NoNewLineParagraph.setMultipliedLeading(F)V )
源码:
import com.itextpdf.text.Document; import com.itextpdf.text.DocumentException; import com.itextpdf.text.pdf.PdfWriter; import com.itextpdf.tool.xml.XMLWorkerHelper;
public static final String HTML = "D:/template.html"; public static final String DEST = "D:/helo.pdf"; public void createPdf(String file) throws IOException, DocumentException { // step 1 Document document = new Document(); // step 2 PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file)); // step 3 document.open(); // step 4 XMLWorkerHelper.getInstance().parseXHtml(writer, document, new FileInputStream(HTML), Charset.forName("UTF-8")); // step 5 document.close(); } public static void main(String[] args) throws IOException, DocumentException { File file = new File(DEST); file.getParentFile().mkdirs(); new TestPdf().createPdf(DEST); }
测试中文字体:
在网上找到一篇资料:
直接上源码:http://www.bubuko.com/infodetail-1301851.html
public void fillTemplate(){//利用模板生成pdf //模板路径 String templatePath = "pdfFolder/template_demo.pdf"; //生成的新文件路径 String newPDFPath = "pdfFolder/newPdf.pdf"; PdfReader reader; FileOutputStream out; ByteArrayOutputStream bos; PdfStamper stamper; try { out = new FileOutputStream(newPDFPath);//输出流 reader = new PdfReader(templatePath);//读取pdf模板 bos = new ByteArrayOutputStream(); stamper = new PdfStamper(reader, bos); AcroFields form = stamper.getAcroFields(); String[] str = {"123456789","小鲁","男","1994-00-00", "130222111133338888" ,"河北省唐山市"}; int i = 0; java.util.Iterator<String> it = form.getFields().keySet().iterator(); while(it.hasNext()){ String name = it.next().toString(); System.out.println(name); form.setField(name, str[i++]); } stamper.setFormFlattening(true);//如果为false那么生成的PDF文件还能编辑,一定要设为true stamper.close(); Document doc = new Document(); PdfCopy copy = new PdfCopy(doc, out); doc.open(); PdfImportedPage importPage = copy.getImportedPage( new PdfReader(bos.toByteArray()), 1); copy.addPage(importPage); doc.close(); } catch (IOException e) { System.out.println(1); } catch (DocumentException e) { System.out.println(2); } }
输出英文:没问题!
1 public void test1(){//生成pdf 2 Document document = new Document(); 3 try { 4 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/1.pdf")); 5 document.open(); 6 document.add(new Paragraph("hello word")); 7 document.close(); 8 } catch (FileNotFoundException | DocumentException e) { 9 System.out.println("file create exception"); 10 } 11 }
可是如果要输出中文呢,上面这个就不行了,就要用到语言包了
最新亚洲语言包:http://sourceforge.net/projects/itext/files/extrajars/
pdf显示中文:
1 public void test1_1(){ 2 BaseFont bf; 3 Font font = null; 4 try { 5 bf = BaseFont.createFont( "STSong-Light", "UniGB-UCS2-H", 6 BaseFont.NOT_EMBEDDED);//创建字体 7 font = new Font(bf,12);//使用字体 8 } catch (DocumentException | IOException e) { 9 e.printStackTrace(); 10 } 11 Document document = new Document(); 12 try { 13 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/2.pdf")); 14 document.open(); 15 document.add(new Paragraph("hello word 你好 世界",font));//引用字体 16 document.close(); 17 } catch (FileNotFoundException | DocumentException e) { 18 System.out.println("file create exception"); 19 } 20 }
另外一种方法:我不用第三方语言包:
我是在工程目录里面新建了一个字体文件夹Font,然后把宋体的字体文件拷贝到这个文件夹里面了
上程序:
1 public void test1_2(){ 2 BaseFont bf; 3 Font font = null; 4 try { 5 bf = BaseFont.createFont("Font/simsun.ttc,1", //注意这里有一个,1 6 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 7 font = new Font(bf,12); 8 } catch (DocumentException | IOException e) { 9 e.printStackTrace(); 10 } 11 Document document = new Document(); 12 try { 13 PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/3.pdf")); 14 document.open(); 15 document.add(new Paragraph("使用中文另外一种方法",font)); 16 document.close(); 17 } catch (FileNotFoundException | DocumentException e) { 18 System.out.println("file create exception"); 19 } 20 }