索引
排好序的数据结构。
问题1:为什么设计索引
用于提升数据库的查找速度
问题2:哈希比树快,索引结果为什么设计成树形
(1)哈希:查询/插入/更新/删除 的平均复杂度都是o(1)。单行查询哈希更快,但是如果是排序查询,哈希的复杂度是o(log(n))
(2)树:查询/插入/更新/删除 的平均复杂度都是o(lg(n))。如果是排序查询,树的有序性使得复杂度依然是o(lg(n))
而且InnorDB不支持哈希索引
问题3:数据库索引为什么使用B+树
二叉树:
数据量大的时候,树的高度会比较高,查询会比较慢;
每个节点只存储一个记录,可能一次查询有很多次磁盘io。
B树:
m叉
叶子节点、非叶子节点均存储数据
中序遍历,可获得所有节点
局部性原理
问题4:数据库索引类型
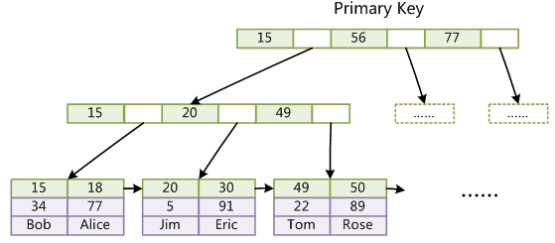
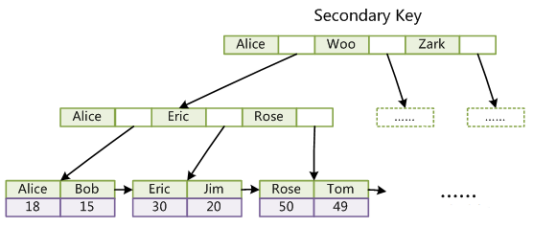
分为主键索引(primary index)和普通索引(secondary index)
1.存储引擎。
存储引擎是表级别的,在建表时指定,mysql默认的是InnerDB引擎。
MyISAM:非聚集。三个文件,table.frm(表结构)、table.MYI索引文件(存储数据文件的地址)、table.MYD(数据文件)。
主键索引和普通索引没有本质区别,是两颗独立的索引B+树,叶子节点存储的都是主键/索引列 与 对应行记录的指针。所以MyISAM可以没有主键。
只有表锁,没有行锁。
连续聚集的区域单独存储行记录 ?
不支持外键
支持全文索引
索引与数据文件分开,且索引是压缩的,可以更好的利用内存。
适合于以读写为主的程序,比如博客系统、新闻门户网站。
InnerDB:聚集。两个文件,table.frm(表结构)、table.ibd(索引与数据在一份文件)
主键索引的叶子节点存储主键与对应行记录;普通索引叶子节点存储主键索引
有行锁,支持事物
没有单独存储行记录,主键索引与行记录是存储在一起的
支持外键
5.6之前不支持全文索引
适合于更新频率高或需要事务保证数据的完整性的程序,数据量大并发量大,建议使用innordb,比如OA。
其他tips:
select count(*) MyISAM会单独存储行记录,不会全表扫描;InnerDB不存储行数,会全表扫描
不管哪种存储引擎,数据量大并发量大的情况下,都不应该使用外键,建议由应用程序保持完整性
innordb的行锁是实现在索引上的,而不是锁在物理行记录上,如果访问没有命中索引,也无法使用行锁,退化成表锁。务必建好索引,否则锁力度大影响并发。
2.底层数据结构---B+树
磁盘读取原理:
1)寻道:寻道速度慢,耗时长。个人理解为定位数据范围
2)旋转移动:速度较快。个人理解为查找具体的数据
所以需要让一次寻道加载到更多的数据。B+树节点只存储key,不存储value,可以增大度(节点的分叉数)。
B+树:
能够保证数据稳定有序,插入和修改的复杂度较稳定。常用于数据库和操作系统的文件系统中。
1)非叶子节点不存储value,只存储key,可以增大度,降低树的高度。叶子节点存储value,叶子节点是最后一次查询,不影响查询效率。
2)叶子节点之间有指针,范围查询效率快。
主键索引:建议主键设置为自增长的整型。一是整型(4字节),二是自增长(连续,插入数据等不会因为平衡树多次移动节点,性能高)。
普通索引(非主键索引):叶子节点存储的是主键索引的值。一是节约内存,二是保证数据的一致性(只需维护一套数据)。
最左前缀原理:
建立联合索引时,B+树按照从左到右的顺利建立搜索树。
Explain分析:
id:按照select出现的顺序增长,id值越大越先执行
key_len:
varchr(n)变长字段且允许NULL = n* ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchr(n)变长字段且不允许NULL = n *( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(n)固定字段且允许NULL = n * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(n)固定字段且不允许NULL = n* ( character set:utf8=3,gbk=2,latin1=1)
int = 4 + 1(NULL)
type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
extra:
using index 覆盖索引。 查询列被索引覆盖;where筛选条件是索引前导列
using where using index 查询列被索引覆盖;筛选条件不是索引前导列,是索引列之一
null 查询列未被索引覆盖;筛选条件是索引前导列
using index condition 条件过滤索引。查询列未被索引覆盖;筛选条件是一个前导列的范围
using where 查询列未被索引覆盖;筛选条件不是索引前导列
using temporary 创建一张临时表进行查询。一般考虑索引来进行优化
using filesort 对结果使用外部索引排序。如果order by 的条件是索引字段,这种会走索引,索引本身就是排好序的。group by 会先order by 一次。一般考虑索引来进行优化
索引实践
1.全值匹配
索引字段全部能够用上
2.遵守最佳左前缀法则
如果索引了多列,查询从索引的最左前列开始,并且不跳过索引中的列
3.不在索引上做任何操作(计算、函数、类型转换等),会导致索引失效,转向全表扫描
4.存储引擎中不能使用索引中范围查找右边的列
index(columa,columb,columc)
1) select * from table where columa=a and columc=c and columb>b; 用到索引的字段有columa、columb,没有用到columc的索引;mysql内部会优化查询顺序
2) select * from table where columa>a 没有用到任何索引。如果范围条件是索引前导列,不会用到索引。优化方案是使用覆盖索引
5.少用select * ,只查需要的字段,尽量使用覆盖索引
6. <>或 != 无法使用索引,会全表扫描
7. is null 或 is not null 无法使用索引,会全表扫描
8.like ‘%字符串’ 索引失效 ;like '字符串%' 可以走索引
如何优化like ‘%字符串%’ ,查询字段尽量使用覆盖索引
9.字符串不加单引号,索引失效
10. or 索引可能会失效
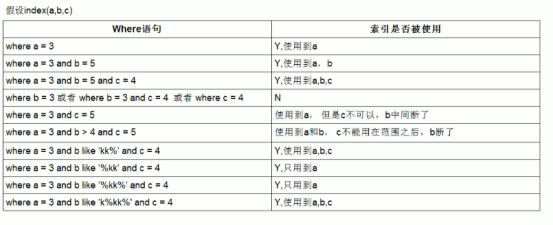
ps:like KK%相当于=常量,%KK和%KK% 相当于范围
口诀:
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用。
补充知识点:
1. mysql两种排序方式:
using index 使用索引本身的排序。遵守最左前缀法则。
filesort 尽量能优化使用索引本身的排序。
另外,group by 也是会先order by
2. 使用 in 还是 exist:
以小表数据驱动大表,即先查小表再查大表。 in 是先查后面的再查前面的, exist 是先查前面的再查后面的。