总思路:
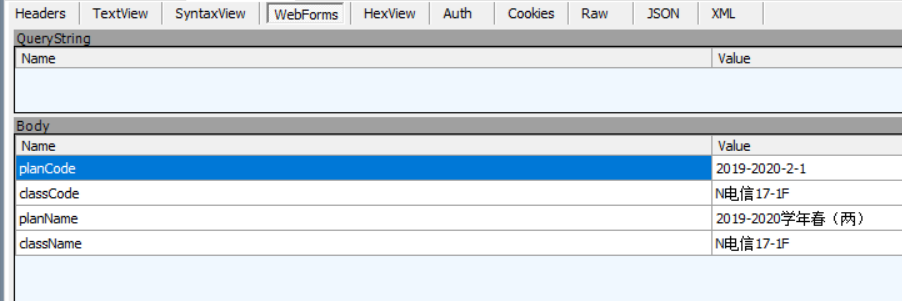
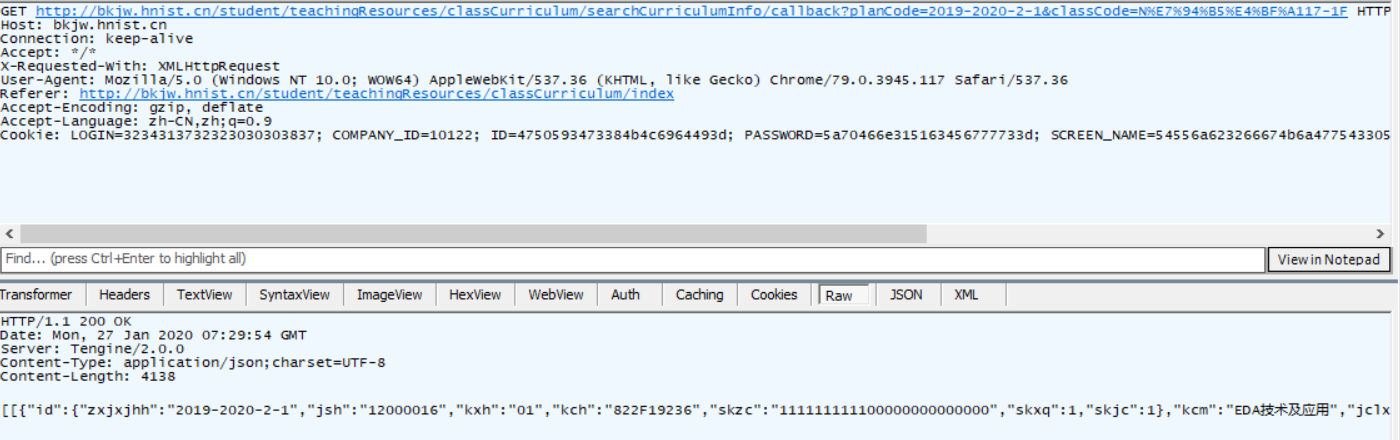
抓包看需要发送什么数据,从fiddler抓到的包发现想要获得课程表的数据需要发送一个携带班级序号和学期号的GET请求,
因为尝试了各种方法都无法直接通过请求进入网站,于是我把可能需要携带的数据都带进去,发现只需要一个User-Agent和Cookie
这样事情就变得简单了,直接在字典中放入伪装头User-Agent和Cookie,再通过urllib.parse处理一下这个url,直接发送就能获取到网页发来的json数据了
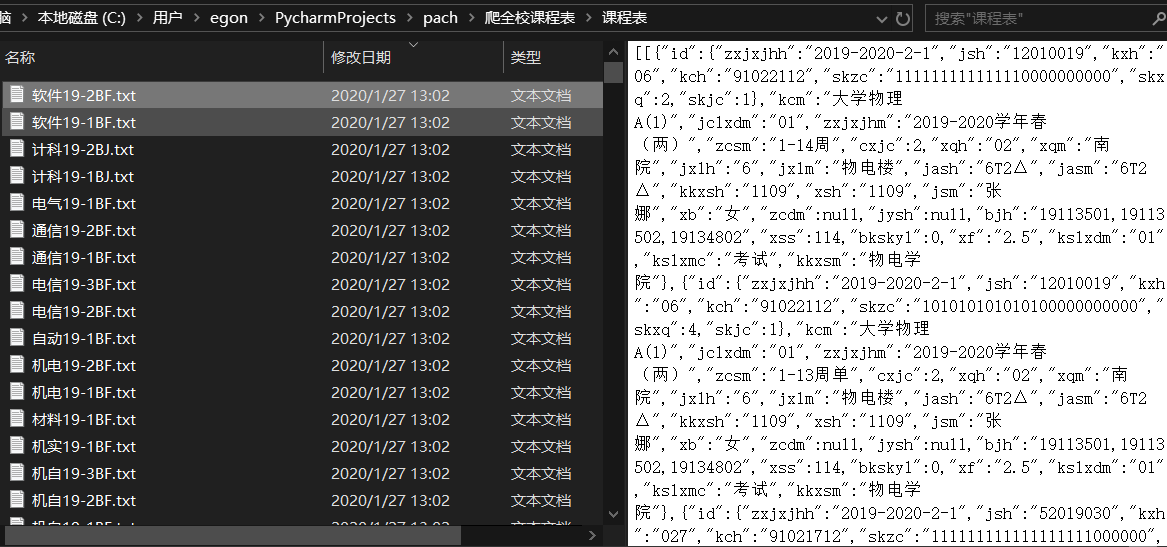
得到json数据后第一件事就是提取里面的班级名,班级号
得到了班级名和班级号,继续发送GET请求,携带班级号和学期号
得到班级的课程信息,再做进一步保存,就得到了想要的数据
========================================================================
1.把全校所有的班级名和班级号弄下来,班级名的作用是用来命名文件,班级号的作用是发送POST请求,返回json数据
import urllib.request import urllib.parse url = 'http://bkjw.hnist.cn/student/teachingResources/classCurriculum/search' fromdata={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36', 'Cookie': 'COMPANY_ID=10122; ID=6a6d653961526b305a44673d; PASSWORD=43717531446d5a623850513d; LOGIN=3234313732323030303837; SCREEN_NAME=563143355451674c6f70326a3735497a4454327442773d3d; JSESSIONID=abcWs6G7vtja1c6SuVH-w; selectionBar=1423374', } for i in range(1,59): post_data={ 'param_value':'100020', 'executiveEducationPlanNum':'2019-2020-2-1', 'yearNum' :'', 'departmentNum' :'', 'subjectNum':'' , 'classNum' :'', 'pageNum':i, 'pageSize':'10', } query_string = urllib.parse.urlencode(post_data).encode() req = urllib.request.Request(url=url,headers=fromdata,data=query_string) resp = urllib.request.urlopen(req).read() with open('第%d页'%i+'.txt','w',encoding='utf-8')as f: f.write(resp.decode())
2.提取班级名和班级号
import json import os def file_open(filename): file=json.load(open(filename,'r',encoding='utf-8')) return file def parse_file(filename,page): fp = file_open(filename) file=open('班级名/第%d页班级名.txt'%page,'w',encoding='utf-8') for i in range(1,len(fp[0]['records'])): print(fp[0]['records'][i]['className']+','+fp[0]['records'][i]['id']['classNum']) classname = fp[0]['records'][i]['className'] classNum= fp[0]['records'][i]['id']['classNum'] file.write(classname+' '+classNum+' ') for i in range(1,59): name='第%d页.txt'%i page=i parse_file(name,page)
接下来把这些文件合并到一个总文件
import os for filename in os.listdir("班级名"): print(filename) with open("班级名/"+filename,encoding='utf-8') as f: for line in f.readlines(): with open("班级名/总表.txt", "a") as fp: fp.write(line)
这样就有一个班级名和班级号的总表了

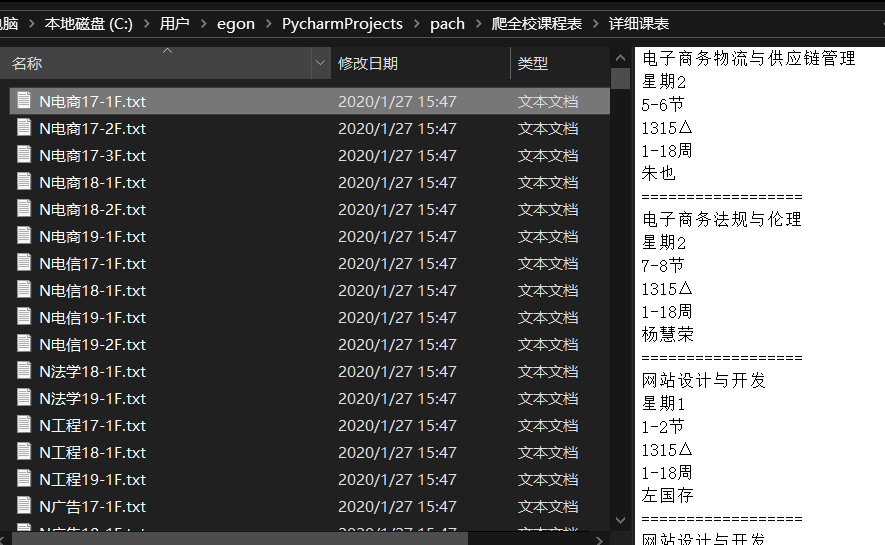
3.继续发送请求,返回课程表数据
import json import os def list_file(): for filename in os.listdir("课程表"): print('文件名:',filename) load_file(filename) def load_file(filename): try: file =open('课程表/%s'%filename,'r',encoding='gbk') context = json.load(file) print('文件已加载') write_in_file(context,filename) except FileNotFoundError as e: print(e) # print(context) # print(type(context)) # # print(context[0][0]) # #课程名 # print(context[0][0]['kcm']) # # # #上课星期 # print(context[0][0]['id']['skxq']) # # #周次 # print(context[0][0]['zcsm']) # # # print(context[0][0]['xqm']) # # # # print(context[0][1]['jash']) # # # #教师名 # print(context[0][1]['jsm']) # # # #课程名 # print(context[0][1]['kcm']) # # # #上课星期 # print(context[0][1]['id']['skxq']) # # #周次 # print(context[0][1]['zcsm']) # # # print(context[0][1]['xqm']) # # # #教学楼号 # # print(context[0][0]['jxlh']) # # #教学楼名 # # print(context[0][0]['jxlh']) # # #jash # # print(context[0][1]['jash']) # # # #教师名 # print(context[0][1]['jsm']) # # print(context[0][1]['id']['skjc']) def write_in_file(context,filename): print('开始写入文件') if not os.path.exists('详细课表'): os.mkdir('详细课表') classNum=len(context[0]) print('课程总节次:',classNum) for i in range(classNum): try: print('班级名:%s'%filename) #课程名 kcm=context[0][i]['kcm'] print('课程名:',kcm) #上课星期 skxq=context[0][i]['id']['skxq'] #上课节次 skjc=context[0][i]['id']['skjc'] #教室 skjs=context[0][1]['jash'] #周次 zc=context[0][1]['zcsm'] #老师 jsm=context[0][i]['jsm'] print('教师:',jsm) file = open('详细课表/'+filename,'a',encoding='utf-8') if skjc==1: skjc='1-2节' elif skjc==3: skjc='3-4节' elif skjc==5: skjc='5-6节' elif skjc==7: skjc='7-8节' file.write(kcm+' '+'星期'+str(skxq)+' '+str(skjc)+' '+skjs+' '+zc+' '+jsm+' ================== ') except : print('错误') filename=list_file() print('over')