作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
上个星期去看了电影《反贪风暴》,该片讲述了ICAC陆志廉卧底狱中,与狱中两大势力斗智斗力,调查取证罪犯与监狱惩教员私相授受的案件,最终引出并成功破获大案的故事。
对电影中的有些画面印象很是深刻,给了一个满分评价。但在复联的压力之下只能顶着票房第二的位置。
在我获取数据的时候票房已经是7.65亿元,评分9.1。于是我爬取了69406条评论,对评论进行分析电影。
获取数据部分:
然后往下滑,点击右边界面的XHR就发现会出现一个评论文件,我们可以查看里面的数据,每一次滑到底AJAX都会有新的文件,里面包含15条数据。

但是得到的数据是这样的,里面显示的数据包含了:id,评价内容content,评分score,时间time,名字nick。所以如果使用这个数据接口的话我们需要对时间time进行解析,并且只能获取前1

于是根据资料使用抓包工具,找到了另外一个数据接口:
http://m.maoyan.com/mmdb/comments/movie/1211727.json?_v_=yes&offset=0&startTime=0
每次发起请求时 服务器返回的都是JSON格式,每次都会有15条数据,数据返回结构如图所示,我们需要的数据为
- 评论内容:content
- 所在城市:cityName
- 用户id:id
- 电影评分:score
- 评论时间:starttime

这样的话我们的评论数据接口已经得到了,接下来就是对数据进行大量获取了。
获取数据
def get_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'User-Agent': 'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36',
'User-Agent': 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10'
}
proxies = {
"http": " http://10.10.1.10:3128",
"https": " http://10.10.1.10:1080",
}
req = request.Request(url, headers=headers[random.randint(0.2)])
response = request.urlopen(req)
if response.getcode() == 200:
return response.read()
return None
对数据进行处理:
def parse_data(html):
data = json.loads(html)['cmts'] # 将str转换为json
comments = []
for item in data:
comment = {
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况
'content': item['content'].replace('
', ' ', 10), # 处理评论内容换行的情况
'score': item['score'],
'startTime': item['startTime']
}
comments.append(comment)
return comments
对数据进行保存:
#保存到csv文件
for item in comments:
with open('D:h.csv', 'a', encoding='utf-8') as f:
f.write(str(item['id']) + ',' + item['nickName'] + ',' + item['cityName'] + ',' + item[
'content'] + ',' + str(item['score']) + ',' + item['startTime'] + '
')
#保存到数据库中
conInfo = "mysql+pymysql://user:passwd@host:port/movie?charset=utf8"
engine = create_engine(conInfo,encoding='utf-8')
df = pd.DataFrame(allnews)
df.to_sql(name = ‘movie', con = engine, if_exists = 'append', index = False)
所以最后从中爬取69406条评论

数据的可视化结果:(Pyecharts)
注意:得到数据之后要先对数据进行清洗和预处理再进行数据的统计分析
1.观众位置分布:
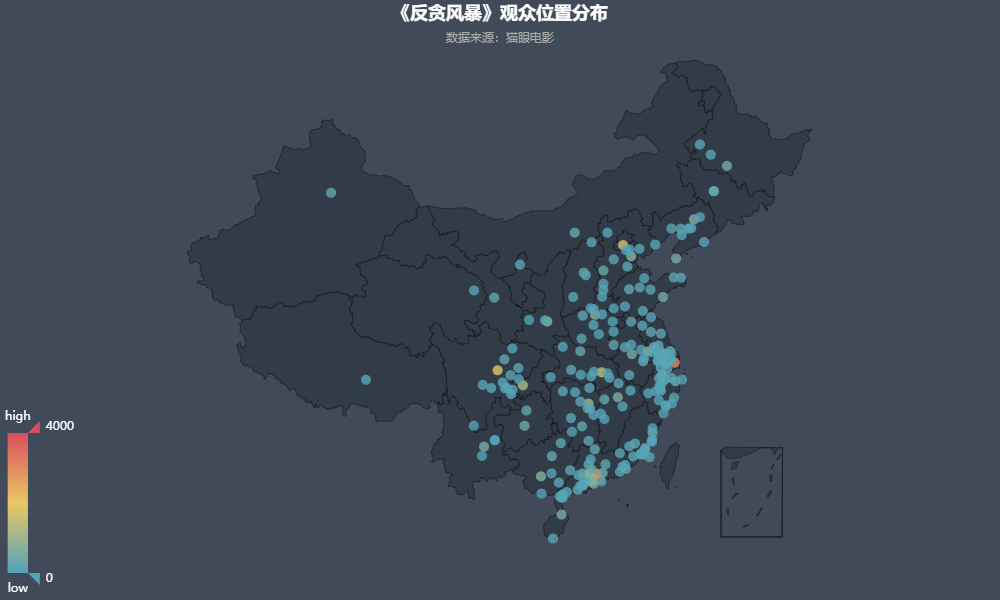
由图可知,《反贪风暴》的观众位置分布相对比较集中在沿海地区,沿海城市的城市相对比较发达,点的颜色也差不多,只有较少个颜色比较突出,代表着人很多的城市所在。
代码:
import pandas as pd
from collections import Counter
from pyecharts import Map, Geo, Bar
def draw_map(comments):
try:
attr = comments['cityName'].fillna("zero_token")
data = Counter(attr).most_common(300)
data.remove(data[data.index([(i, x) for i, x in (data) if i == 'zero_token'][0])])
geo = Geo("《反贪风暴》观众位置分布", "数据来源:猫眼电影", title_color="#fff", title_pos="center", width=1000, height=600,
background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, visual_range=[0, 1000], maptype='china', visual_text_color="#fff", symbol_size=10,
is_visualmap=True)
geo.render("./观众位置分布.html") # 生成html文件
geo # 直接在notebook中显示
except Exception as e:
print(e)
if __name__ == "__main__":
filename = "D:aa.csv"
titles = ['nickName','cityName','content','score','startTime']
comments = pd.read_csv(filename, names=titles, encoding='gbk')
draw_map(comments):
2.粉丝来源排行top20城市
由此我们进一步,对观众所在的城市进行分析。
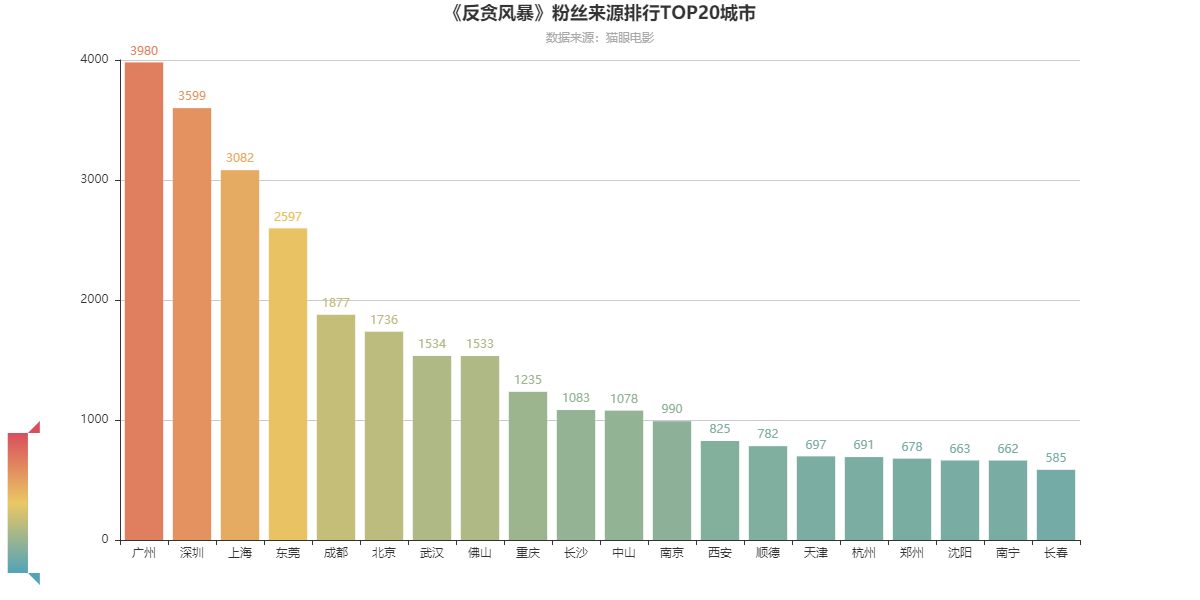
可以看出,粉丝来源排名前20的城市为:广州、深圳、上海ia、东莞、成都、北京、武汉、佛山、重庆、长沙、中山、南京、西安、顺德、天津、杭州、郑州、沈阳、南宁、长春。
可以发现几乎都是经济相对发达的城市,可以看得出这些城市的消费水平更高,民众对第三行业的消费有更多是选择,城市的GDP也逐渐上升。
代码:(本人的数据是直接再excel上统计得到了,也可以使用代码进行统计)
# -*- coding:utf-8 -*-
from pyecharts import Map, Geo, Bar
data_top30=[ (u"广州", 3980), (u"深圳", 3599), (u"上海",3082 ), (u"东莞", 2597), (u"成都", 1877), (u"北京", 1736),
(u"武汉", 1534), (u"佛山", 1533), (u"重庆", 1235), (u"长沙", 1083), (u"中山", 1078), (u"南京", 990),
(u"西安", 825), (u"顺德", 782), (u"天津", 697), (u"杭州", 691), (u"郑州", 678), (u"沈阳", 663),
(u"南宁", 662), (u"长春", 585),]
bar = Bar("《反贪风暴》粉丝来源排行TOP20城市", "数据来源:猫眼电影", title_pos='center', width=1200, height=600)
attr, value = bar.cast(data_top30)
bar.add("", attr, value, is_visualmap=True, visual_range=[0, 5000], visual_text_color='#fff', is_more_utils=True, is_label_show=True)
bar.render("./粉丝来源排行-柱状图.html")
3.词云图:

- 评论中多次出现“可以”、“好看”、“不错”,“非常”等好评词,说明观众还是还是很喜欢《反贪风暴4》的。
- 可以看到很多“古天乐”,“校长”的词语,说明有一些观众是古天乐的头号粉丝,对古天乐的演技表示认可。
- 也有部分观众表示失望,那这个原因估计是因为对剧情的期待太高了导致有落差吧。
# coding=utf-8
# 导入jieba模块,用于中文分词
import jieba
# 导入matplotlib,用于生成2D图形
import matplotlib.pyplot as plt
# 导入wordcount,用于制作词云图
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取所有评论
comments = []
with open('comments.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
comment = row.split(',')[3]
if comment != '':
comments.append(comment)
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false
words = " ".join(comment_after_split) # 以空格进行拼接
# print(words)
# 设置屏蔽词
stopwords = STOPWORDS.copy()
stopwords.add("电影")
stopwords.add("一部")
stopwords.add("一个")
stopwords.add("没有")
stopwords.add("什么")
stopwords.add("有点")
stopwords.add("这部")
stopwords.add("这个")
stopwords.add("不是")
stopwords.add("真的")
stopwords.add("感觉")
stopwords.add("觉得")
stopwords.add("还是")
stopwords.add("但是")
stopwords.add("就是")
# 导入背景图
bg_image = plt.imread('bg.jpg')
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = WordCloud(width=1024, height=768, background_color='white', mask=bg_image, font_path='STKAITI.TTF',
stopwords=stopwords, max_font_size=400, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file('词云图.jpg')
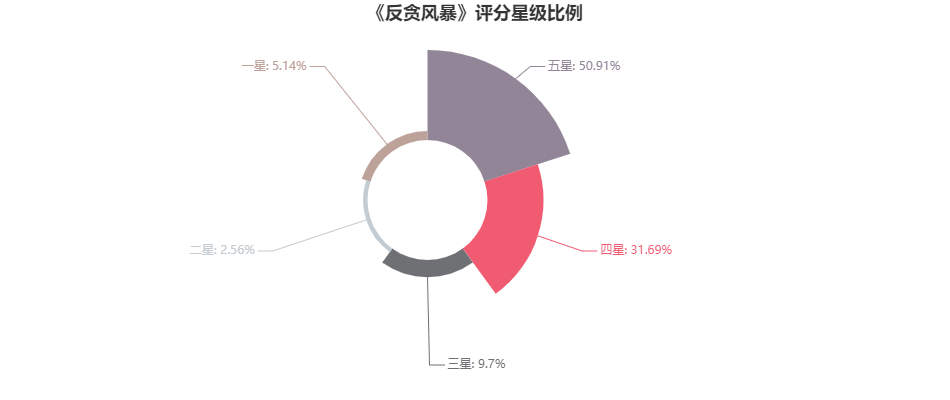
from pyecharts import Pie
attr = ['五星','四星','三星','二星','一星']
value= [15170,9443,2891,762,1533]
pie = Pie('《反贪风暴》评分星级比例', title_pos='center', width=900)
pie.add("7-17", attr, value, center=[75, 50], is_random=True, radius=[30, 75], rosetype='area', is_legend_show=False, is_label_show=True)
pie.render('./观众评分星级.html')
