采集简单分类:
采集类型:
全量 采集: 相当于每天整张表做个快照,在hdfs上就是一个分区 ,表比较小
增量采集: 采集每天增加的部分
表命名规则:
-i结尾: 流水型的纯增量的
-d结尾: 快照的
-a结尾: 全量没有任何分区
1、流水型数据 :
写入数据库数据不再发生变化(如日志,交易流水) , 第二天处理前一天的数据
采集条件可设为
1/ 按时间增量的抽取 ,sqoop:
create_time>=T-1 00:00:00
create_time<=T 00:00:00
2/ 按表的自增ID,每张表都有个自增ID
2、每天会发生变化 (如商品):
1/表比较小 ,每天采集全量
2/ 表比较大
必须有两个字段,create_time, updated_time字段
昨天发生变化的数据+昨日新增的数据 ,采集条件:updated_time >=T-1 00:00:00
and create_time < T 00:00:00
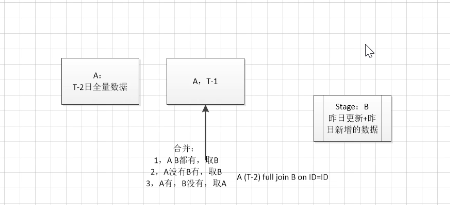
快照,就是一个时间点的数据,全量
sqoop全量在T+1时,比如0点,做一个全量转换,但在运行sqoop时需要花费时间,所以时间并不准确,适合数据量小的时候.
sqoop在做增量是, 比如0点,按create_time和updated_time为条件是可以的.
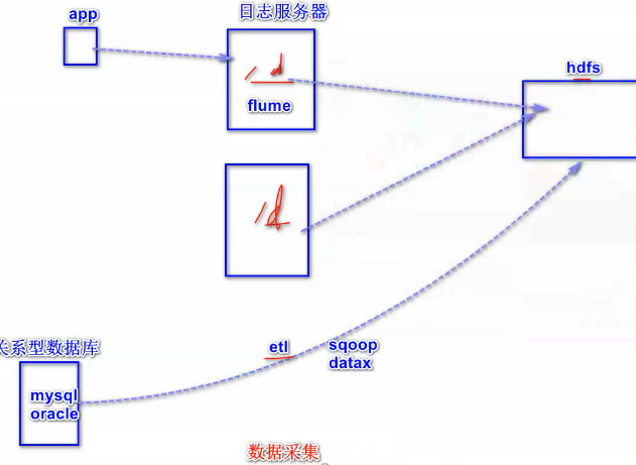
数据采集:
目前主要的数据源分为数据库、日志、平面文件三种,针对每种数据源的特点,采用适当的采集方案,目前常用的主要开源产品如下:
数据库:Datax、Sqoop
日志:flume、logstash、filebeat、rsyslog等
平面文件:ftp、sftp、scp等
为什么mysql关系型数据库的采集不用直接用sqoop就行了,还要采集binglog
数据库用binglog的采集方法优点:
1/ 时间可以很准确,
2/ 实时采集,也可用于实时计算.
如果要用binglog的采集方式,并支持事务或用于实时计算,可采用:
方法一:
#先存在hbase的采集方案,以支持事务来实时查询,在数据量不大(千万条时),后端可用hive,和Phoenix来实时查询(当然hive如果选MR作引擎,做不了准实时,有MR的时间)

缺点:
1/ hbase如果做聚合指标计算的话,是需要通过 coprocessor 做开发,变成固定api式的使用,灵活程度太低了。如常见聚合操作,找一张大表某个字段的最大值,如果不用Coprocesser则只能全表扫描,在客户端遍历所有结果找出最大值,且只能利用有限的客户端资源进行迭代计算,无法利用上HBase的并发计算能力
2/ 实时计算Phoenix不稳定和bug太多,影响了它的使用
方法二:
使用流式引擎直接计算binlog 这种精确业务数据会造成的数据误差,数据误差的原因和数据顺序、业务计算要求都有关。所以采用:
confluent写入kudu,impala计算对比mysql结果
datax:
阿里开源,支持mysql到orcle, 支持mangoDB .基于多线程级别的并行实现离线、异构平台同步工具,能够快速实现数据异构数据源的离线同步。
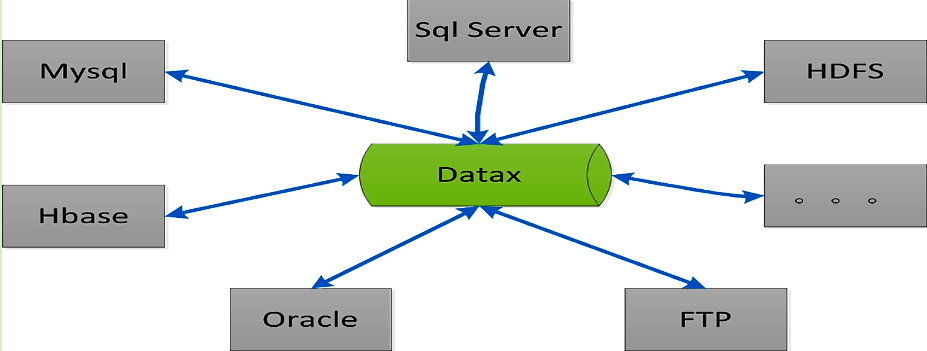
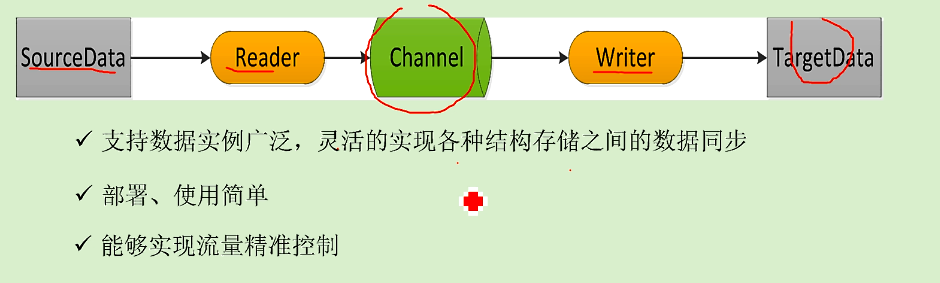
不是分布式.单台的资源压力可能会比较大.
sqoop:
开源的,基于mr的、关系型数据库与hdfs之间数据同步工具,目前有1和2两个版本。目前常用的是1.
sqoop1部署特别简单,就一个客户端,部署在hadoop集群上的一个节点上,只要能连上yarn就可以了
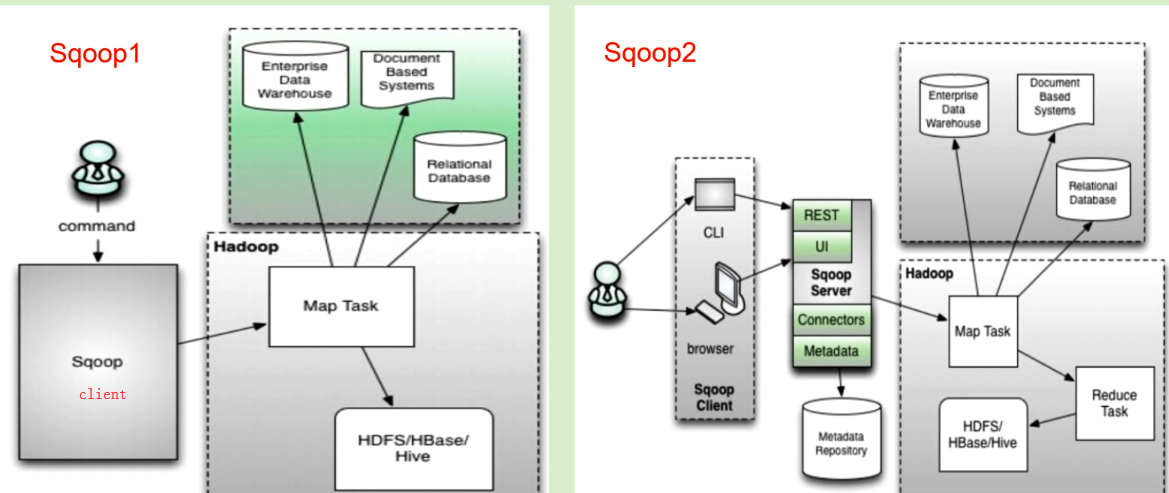
sqoop2则是有了一个server,客户端通过server来提交作业到yarn上。
优点:sqoop1架构更简单,但sqoop1命令上用户名密码都是暴露出去的,2是server上创建了connector,客户端不会暴露密码。
但sqoop2只负责数据的读写操作,不像1还可以在命令行建表建分区等。需要下来再多一个步骤,所以相对1来说不是很方便。
注意:
sqoop是在yarn上运行MR,所以每个节点上的nodemanager需要和源mysql数据相连,即yarn的节点ip要加入mysql的白名单.特别是集群扩容增加新节点后,不要忘了把新节点加入源mysql的白名单,不然有些作业调度到新节点上的会失败.
datax没有这个问题,数据库都是和datax交互, datax数据没有通过yarn,而是直接落在hdfs上.
datax 和 sqoop的区别:

Flume:
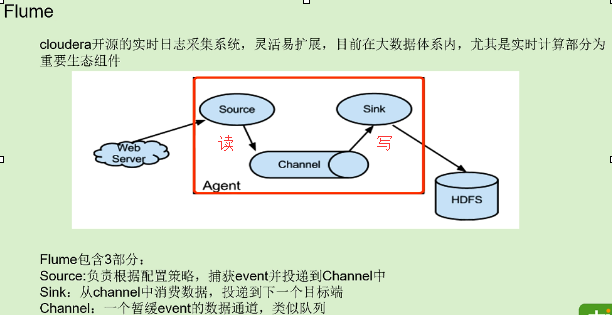
开发做异步来提高并发,也通常会用队列的形式.
上面是原理介绍,但实际中很少会部一个节点的情况:
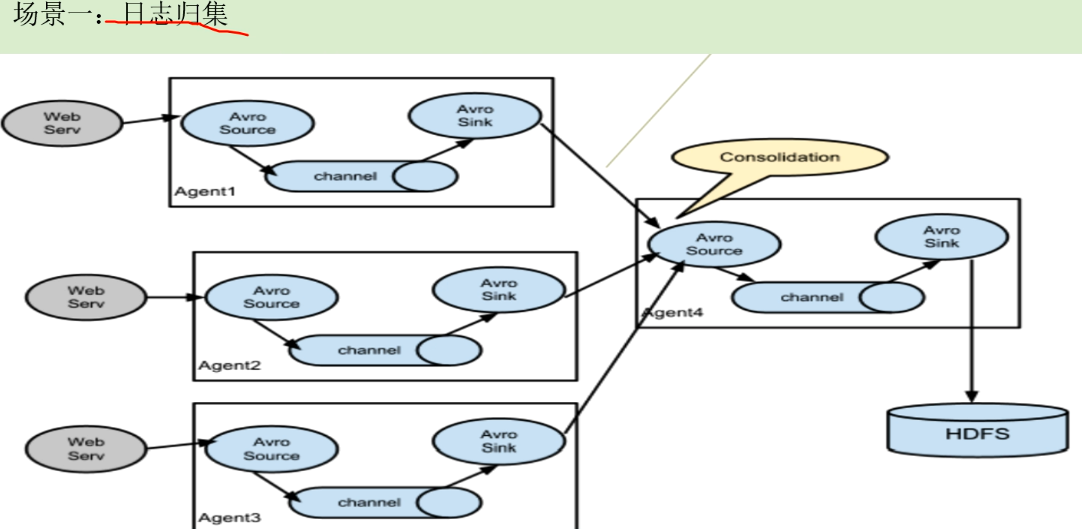
场景一:
如果100台webserve日志收集都直接写到hdfs,那会有很多小文件.所以做日志归集
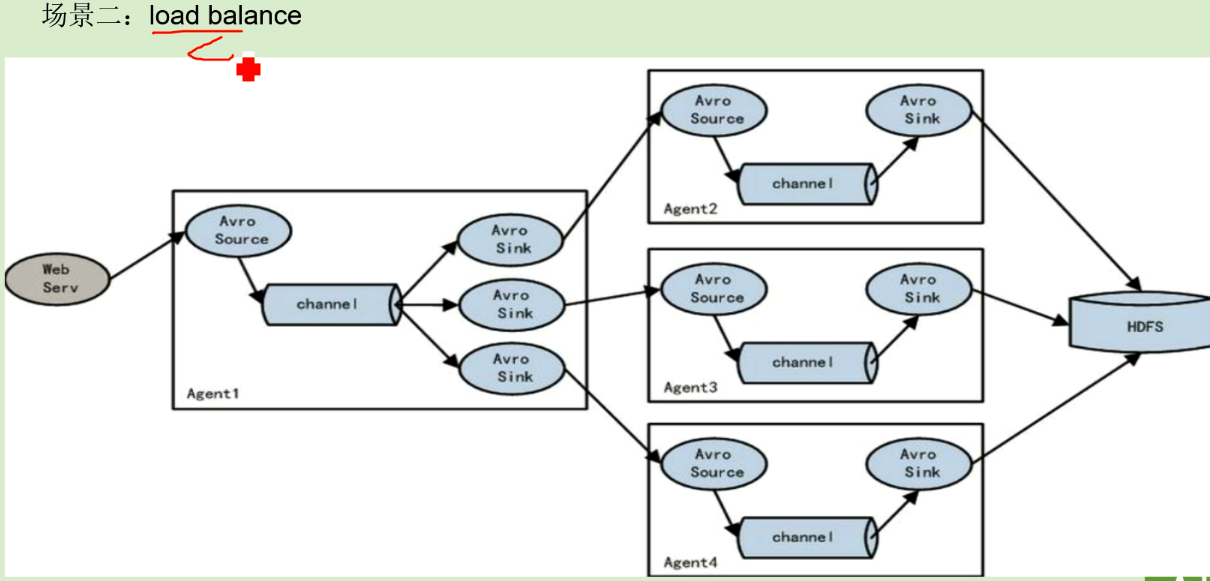
场景二:
上面解决了聚合问题,但还存在聚合单点问题.实际中聚合点也是至少2台。 所以场景一,二可以整合在一起
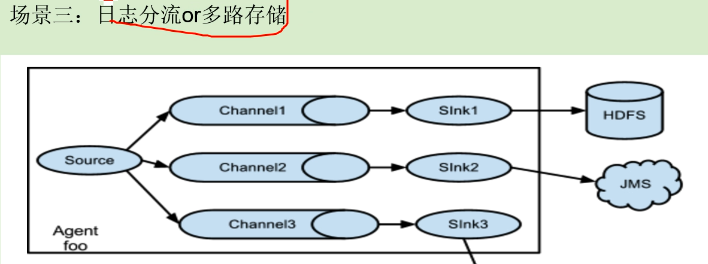
场景三:
日志分流和多路存储
场景四:
数据通道前置
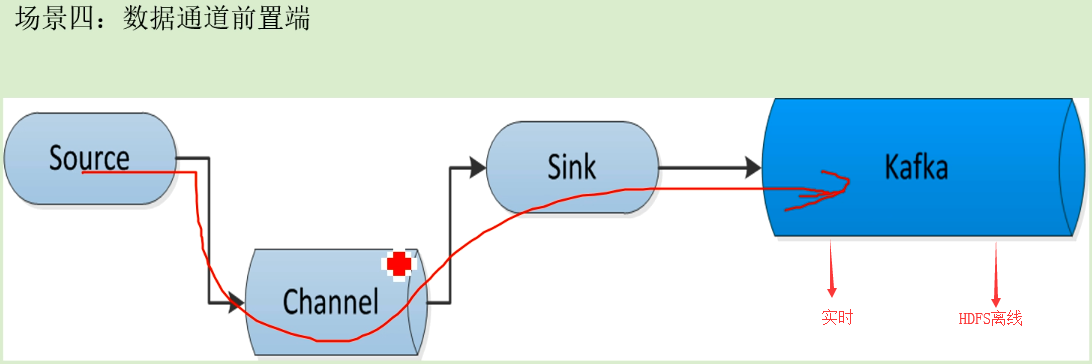
用kafka使数仓和实时算法、风控等部门都来订阅(消费)kafka,kafka保持了数据的一致性。
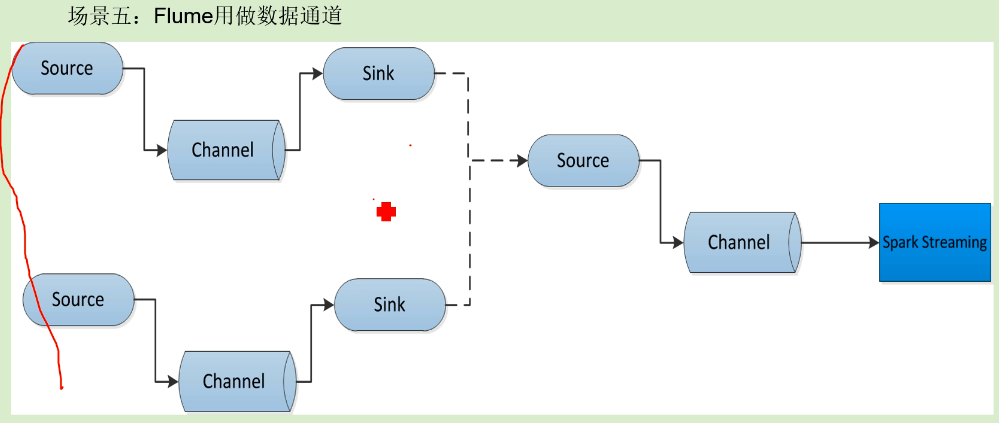
场景五:
flume替代kafka作数据通道
有些时候需要快速上线,单一的通道就可以了
spark streaming:
https://www.cnblogs.com/fishperson/p/10447033.html