一,添加ufile需在配置中添加:
core-site.xml
添加如下配置:
<property>
<name>fs.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFileSystem</value>
</property>
<property>
<name>ufile.properties.file</name>
<value>/data/ufile.properties</value>
</property>
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
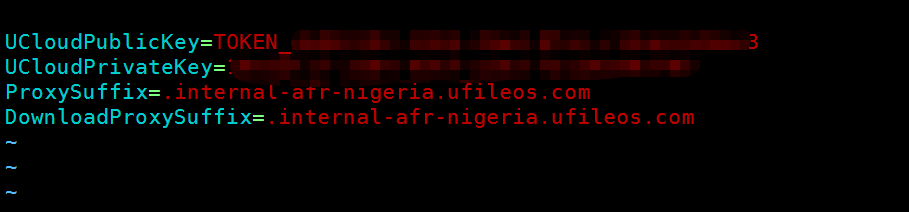
ufile.properties:
格式如下:
UCloudPublicKey=${API公钥或者TOKEN公钥}
UCloudPrivateKey=${API私钥或者TOKEN私钥}
ProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
DownloadProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
ls /data/ufile.properties
例子:
操作ufile测试:
hdfs dfs -put test.txt ufile://<bucket名>/test.txt
hdfs dfs -ls ufile://opay-datalake
<bucket名>是整段名字最前面的一段,也可点域名管理看

jar包放的目录:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep uhadoop*
uhadoop-1.0-SNAPSHOT.jar
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep ufile
ufilesdk-1.0-SNAPSHOT.jar
如要使用impala,还需要在impala下放置:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufile*
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/uhadoop*
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
scp uhadoop-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
要hive使用ufile还需要拷到这些位置:
scp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/udf-1.0-SNAPSHOT-jar-with-dependencies.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp uhadoop-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib
#要用beeline,还得在下面的位置都放置两个jar包:
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/sqoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-hdfs/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/jars/ufilesdk-1.0-SNAPSHOT.jar
理论上讲:
读: 5G B /s 40G b/s
写: 0.56G B/s 1TB 30min
问题:
1/ 当用 orc格式插入数据,起初是14万条,后来是140万条,报错如下:

改为stored as parquet格式正常
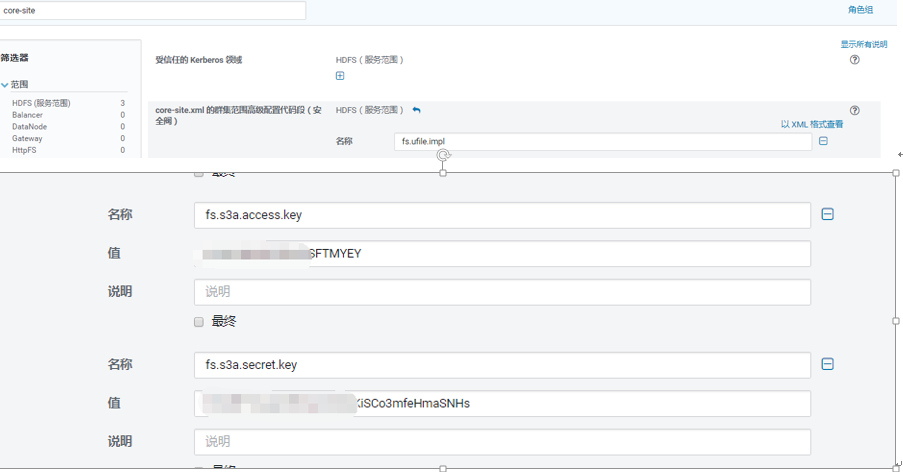
二, 添加s3的访问,因为aws的jar已经内置到了CDH,所以只需要改core-site.xml就可以了
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>AKI</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>l8IvM8s</value>
</property>
</configuration>
hadoop dfs -ls s3a://opay-bi/
#CDH要在配置中加:
参考:
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html