SAX的特点:
- 是基于事件的 API
- 在一个比 DOM 低的级别上操作
- 为您提供比 DOM 更多的控制
- 几乎总是比 DOM 更有效率
- 但不幸的是,需要比 DOM 更多的工作
基于对象和基于事件的接口
您可能已经知道语法分析器有两类接口 - 基于对象的(如:DOM)和基于事件(如:SAX)的接口。
DOM是基于对象的语法分析器的标准 API。
作为基于对象的接口,DOM 通过在内存中显示地构建对象树来与应用程序通信。对象树是 XML 文件中元素树的精确映射。
DOM 易于学习和使用,因为它与基本 XML 文档紧密匹配。然而,对于大多数应用程序,处理 XML 文档只是其众多任务中的一种。例如,记帐软件包可能导入 XML 发票,但这不是其主要活动。计算帐户余额、跟踪支出以及使付款与发票匹配才是主要活动。记帐软件包可能已经具有一个数据结构(最有可能是数据库)。DOM 模型不太适合记帐应用程序,因为在那种情况下,应用程序必须在内存中维护数据的两份副本(一个是 DOM 树,另一个是应用程序自己的结构)。至少,在内存维护两次数据会使效率下降。对于桌面应用程序来说,这可能不是主要问题,但是它可能导致服务器瘫痪。
对于不以 XML 为中心的应用程序,SAX 是明智的选择。实际上,SAX 并不在内存中显式地构建文档树。它使应用程序能用最有效率的方法存储数据。
基于事件驱动
基于事件的语法分析器将事件发送给应用程序。这些事件类似于用户界面事件,例如,浏览器中的 ONCLICK 事件或者 Java 中的 AWT/Swing 事件。
事件通知应用程序发生了某件事并需要应用程序作出反应。在浏览器中,通常为响应用户操作而生成事件:当用户单击按钮时,按钮产生一个 ONCLICK 事件。
在 XML 语法分析器中,事件与用户操作无关,而与正在读取的 XML 文档中的元素有关。有对于以下方面的事件:
- 元素开始和结束标记
- 元素内容
- 实体
- 语法分析错误
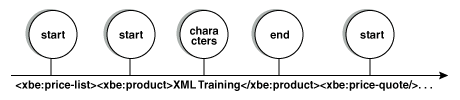
图 3 显示语法分析器在读取文档时如何生成事件。
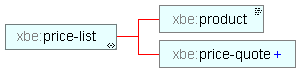
清单 1 显示了 XML 格式的清单。它详细列出了不同公司对 XML 培训的收费。图 4 显示了价目表文档的结构。
清单 1. pricelist.xml
<?xml version="1.0"?> <xbe:price-list xmlns:xbe="http://www.psol.com/xbe2/listing8.1"> <xbe:product>XML Training</xbe:product> <xbe:price-quote price="999.00" vendor="Playfield Training"/> <xbe:price-quote price="699.00" vendor="XMLi"/> <xbe:price-quote price="799.00" vendor="WriteIT"/> <xbe:price-quote price="1999.00" vendor="Emailaholic"/> </xbe:price-list>
图 4. 价目表的结构
XML 语法分析器读取并解释该文档。每当它识别出文档中的某些内容,就会生成一个事件。
读取 清单 1 时,语法分析器首先读取 XML 声明并生成文档开始事件。当它遇到第一个开始标记 <xbe:price-list> 时,语法分析器生成它的第二个事件来通知应用程序已经遇到了 price-list 元素。
接下来,语法分析器看到 product 元素的开始标记(为简单起见,在本文其余部分,我将忽略名称空格和缩进空格)并生成它的第三个事件。
在开始标记后,语法分析器看到 product 元素的内容: XML Training ,它产生另一个事件。
下一个事件指出 product 元素的结束标记。语法分析器已经完成了对 product 元素的语法分析。到目前为止,它已经激发了 5 个事件: product 元素的 3 个事件,一个文档开始事件和一个 price-list 开始标记事件。
语法分析器现在移动到第一个 price-quote 元素。它为每个 price-quote 元素生成两个事件:一个开始标记事件和一个结束标记事件。
是的,即使将结束标记简化为开始标记中的 / 字符,语法分析器仍然生成一个结束事件。
有 4 个 price-quote 元素,所以语法分析器在分析它们时生成 8 个事件。最后,语法分析器遇到 price-list 的结束标记并生成它的最后两个事件:结束 price-list 和文档结束。
如图 5 所示,这些事件共同向应用程序描述了文档树。开始标记事件意味着“转到树的下一层”,而结束标记元素意味着“转到树的上一层”。
图 5. 语法分析器如何隐含地构建树
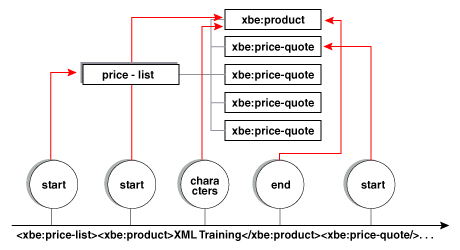
请注意,语法分析器传递了足够信息以构建 XML 文档的文档树,但是与 DOM 语法分析器不同,它并不显式地构建该树。
为何选择SAE而不是DOM
现在,我敢肯定你已经糊涂了。应该使用哪一种类型的 API,应该何时使用它 - SAX 还是 DOM?不幸的是,这个问题没有明确的答案。这两种 API 中没有一种在本质上更好;他们适用于不同的需求。
经验法则是在需要更多控制时使用 SAX;要增加方便性时,则使用 DOM。
例如,DOM 在脚本语言中很流行。
采用 SAX 的主要原因是效率。SAX 比 DOM 做的事要少,但提供了对语法分析器的更多控制。当然,如果语法分析器的工作减少,则意味着您(开发者)有更多的工作要做。
而且,正如我们已讨论的,SAX 比 DOM 消耗的资源要少,这只是因为它不需要构建文档树。
在 XML 早期,DOM 得益于 W3C 批准的官方 API 这一身份。逐渐地,开发者选择了功能性而放弃了方便性,并转向了 SAX。
SAX 的主要限制是它无法向后浏览文档。实际上,激发一个事件后,语法分析器就将其忘记。如您将看到的,应用程序必须显式地缓冲其感兴趣的事件。
使用Python解析XML的时候,需要 import xml.sax 和 xml.sax.handler
xml.sax
xml.sax提供了3个函数以及 SAX 异常类
make_parser方法
创建并返回一个SAX XMLReader对象
xml.sax.make_parser([parser_list])
- parser_list - 可选参数,解析器列表
parse方法
创建一个 SAX 解析器并解析xml文档
xml.sax.parse(filename_or_stream, handler[, error_handler])
- file_or_stream:xml文件名
- handler:必须是一个ContentHandler的对象
- error_handler:如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
parseString方法
创建一个XML解析器并解析xml字符串
xml.sax.parseString(string, handler[, error_handler])
- string: xml字符串
- handler:必须是一个ContentHandler的对象
- error_handler:如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
ContentHandler类方法介绍
- characters(content)方法
- 调用时机
- 从行开始,遇到标签之前,存在字符,content的值为这些字符串。
- 从一个标签,遇到下一个标签之前, 存在字符,content的值为这些字符串。
- 从一个标签,遇到行结束符之前,存在字符,content的值为这些字符串。
- 标签可以是开始标签,也可以是结束标签。
- startDocument()方法:文档启动的时候调用。
- endDocument()方法:解析器到达文档结尾时调用。
- startElement(name, attrs)方法:遇到XML开始标签时调用,name是标签的名字,attrs是标签的属性值字典。
- endElement(name)方法:遇到XML结束标签时调用。
Python 解析XML实例
要解析的XML
1 <?xml version="1.0"?> 2 <collection shelf="New Arrivals"> 3 <movie title="Enemy Behind"> 4 <type>War, Thriller</type> 5 <format>DVD</format> 6 <year>2003</year> 7 <rating>PG</rating> 8 <stars>10</stars> 9 <description>Talk about a US-Japan war</description> 10 </movie> 11 <movie title="Transformers"> 12 <type>Anime, Science Fiction</type> 13 <format>DVD</format> 14 <year>1989</year> 15 <rating>R</rating> 16 <stars>8</stars> 17 <description>A schientific fiction</description> 18 </movie> 19 <movie title="Trigun"> 20 <type>Anime, Action</type> 21 <format>DVD</format> 22 <episodes>4</episodes> 23 <rating>PG</rating> 24 <stars>10</stars> 25 <description>Vash the Stampede!</description> 26 </movie> 27 <movie title="Ishtar"> 28 <type>Comedy</type> 29 <format>VHS</format> 30 <rating>PG</rating> 31 <stars>2</stars> 32 <description>Viewable boredom</description> 33 </movie> 34 </collection>
使用SAX解析XML的Python源代码
1 #!/usr/bin/python 2 3 import xml.sax 4 5 class MovieHandler( xml.sax.ContentHandler ): 6 def __init__(self): 7 self.CurrentData = "" 8 self.type = "" 9 self.format = "" 10 self.year = "" 11 self.rating = "" 12 self.stars = "" 13 self.description = "" 14 15 # 元素开始事件处理 16 def startElement(self, tag, attributes): 17 self.CurrentData = tag 18 if tag == "movie": 19 print "*****Movie*****" 20 title = attributes["title"] 21 print "Title:", title 22 23 # 元素结束事件处理 24 def endElement(self, tag): 25 if self.CurrentData == "type": 26 print "Type:", self.type 27 elif self.CurrentData == "format": 28 print "Format:", self.format 29 elif self.CurrentData == "year": 30 print "Year:", self.year 31 elif self.CurrentData == "rating": 32 print "Rating:", self.rating 33 elif self.CurrentData == "stars": 34 print "Stars:", self.stars 35 elif self.CurrentData == "description": 36 print "Description:", self.description 37 self.CurrentData = "" 38 39 # 内容事件处理 40 def characters(self, content): 41 if self.CurrentData == "type": 42 self.type = content 43 elif self.CurrentData == "format": 44 self.format = content 45 elif self.CurrentData == "year": 46 self.year = content 47 elif self.CurrentData == "rating": 48 self.rating = content 49 elif self.CurrentData == "stars": 50 self.stars = content 51 elif self.CurrentData == "description": 52 self.description = content 53 54 if ( __name__ == "__main__"): 55 56 # 创建一个 XMLReader 57 parser = xml.sax.make_parser() 58 # turn off namepsaces 59 parser.setFeature(xml.sax.handler.feature_namespaces, 0) 60 61 # 重写 ContextHandler 62 Handler = MovieHandler() 63 parser.setContentHandler( Handler ) 64 65 parser.parse("movies.xml")
执行结果:
*****Movie***** Title: Enemy Behind Type: War, Thriller Format: DVD Year: 2003 Rating: PG Stars: 10 Description: Talk about a US-Japan war *****Movie***** Title: Transformers Type: Anime, Science Fiction Format: DVD Year: 1989 Rating: R Stars: 8 Description: A schientific fiction *****Movie***** Title: Trigun Type: Anime, Action Format: DVD Rating: PG Stars: 10 Description: Vash the Stampede! *****Movie***** Title: Ishtar Type: Comedy Format: VHS Rating: PG Stars: 2 Description: Viewable boredom
参考文章
推荐书籍
《Python Cookbook》第12章:XML处理