由于heap中对象的存活时间差异很大,如果每一次都是无差别的进行gc,效率会很差。将heap按照对象大小、存活时间划分出不同的区域,针对不同的区域使用不同的gc算法可以提高效率。
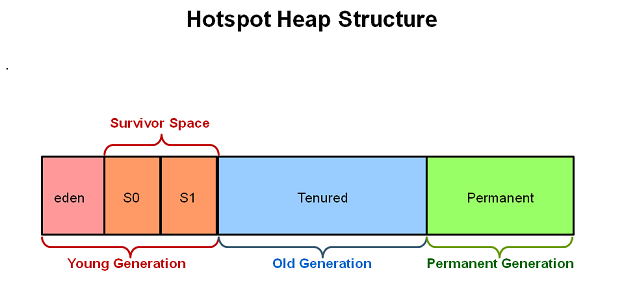
年轻代的对象存活率低可以采用复制算法,老年代的对象或是存活率高的对象,或是大对象,这些对象使用复制算法进行gc成本太高,所以老年代的gc可以采用标记-清除(可以选择是否进行压缩)。
ps:虽然每个区域的垃圾收集算法较为固定,但每个垃圾收集器的工作逻辑又有差别(比如单线程、多线程,并发、并行等)。
Serial

-XX:+UseSerialGC,显示指定Serial新生代垃圾收集器(Serial Old是Serial的老年代版本)
ParNew

-XX:+UseParNewGC,显示指定ParNew新生代垃圾收集器,ParNew是Serial的多线程版本(通过-XX:+UseConcMarkSweepGC设置CMS为老年代垃圾收集器后,新生代默认就为ParNew);
CMS
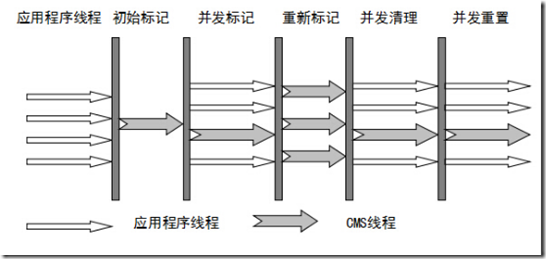
-
初始标记:STW,单线程,由于是从GCRoot寻找直达的对象,速度快;
-
并发标记:与应用线程一起运行,是CMS最主要的工作阶段,通过直达对象,扫描全部的对象,进行标记;
-
重新标记:STW,修正并发标记时由于应用程序还在并发运行产生的对象的修改(标记在可达路径上新增的对象),多线程,速度快,需要全局停顿;
-
并发清除:与应用程序一起运行。CMS主要关注低延迟,因而采用并发方式,清理垃圾时,应用程序还在运行。如果开启压缩算法,则涉及到要移动应用程序的存活对象,此时不停顿,是很难处理的,一般需要停顿下,移动存活对象,再让应用程序继续运行,但这样停顿时间变长,延迟变大。
-XX:+UseConcMarkSweepGC,使用CMS收集器;
-XX:+ UseCMSCompactAtFullCollection,Full GC后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长;
-XX:+CMSFullGCsBeforeCompaction=n,设置进行n次Full GC后,进行一次碎片整理;
-XX:ParallelCMSThreads=n,在进行并行GC的时候,用于GC的线程数,比如ParNew在对新生代gc时会STW,这是会有n个线程并行gc;
-XX:ConcGCThreads=n,设定CMS并发的线程数量(如果指定了ConcGCThreads=n,则除初始标记外,其余阶段都会使用n个线程,如果没有指定ConcGCThreads,则ConcGCThreads = (ParallelGCThreads + 3)/4);
-XX:CMSInitiatingOccupancyFraction=n,老年代使用n%后触发CMS垃圾回收;


1 /** ParallelGCThreads的取值策略: 2 ①如果用户显示指定了ParallelGCThreads,则使用用户指定的值。 3 ②否则,需要根据实际的CPU所能够支持的线程数来计算ParallelGCThreads的值,计算方法见步骤③和步骤④。 4 ③如果物理CPU所能够支持线程数小于8,则ParallelGCThreads的值为CPU所支持的线程数。这里的阀值为8,是因为JVM中调用nof_parallel_worker_threads接口所传入的switch_pt的值均为8。 5 ④如果物理CPU所能够支持线程数大于8,则ParallelGCThreads的值为8加上一个调整值,调整值的计算方式为:物理CPU所支持的线程数减去8所得值的5/8或者5/16,JVM会根据实际的情况来选择具体是乘以5/8还是5/16。 6 比如,在64线程的x86 CPU上,如果用户未指定ParallelGCThreads的值,则默认的计算方式为:ParallelGCThreads = 8 + (64 - 8) * (5/8) = 8 + 35 = 43。 7 */ 8 unsigned int VM_Version::calc_parallel_worker_threads() { 9 unsigned int result; 10 if (is_M_series()) { 11 // for now, use same gc thread calculation for M-series as for niagara-plus 12 // in future, we may want to tweak parameters for nof_parallel_worker_thread 13 result = nof_parallel_worker_threads(5, 16, 8); 14 } else if (is_niagara_plus()) { 15 result = nof_parallel_worker_threads(5, 16, 8); 16 } else { 17 result = nof_parallel_worker_threads(5, 8, 8); 18 } 19 return result; 20 } 21 22 unsigned int Abstract_VM_Version::parallel_worker_threads() { 23 if (!_parallel_worker_threads_initialized) { 24 if (FLAG_IS_DEFAULT(ParallelGCThreads)) { 25 _parallel_worker_threads = VM_Version::calc_parallel_worker_threads(); 26 } else { 27 _parallel_worker_threads = ParallelGCThreads; 28 } 29 _parallel_worker_threads_initialized = true; 30 } 31 return _parallel_worker_threads; 32 } 33 34 unsigned int Abstract_VM_Version::calc_parallel_worker_threads() { 35 return nof_parallel_worker_threads(5, 8, 8); 36 } 37 38 unsigned int Abstract_VM_Version::nof_parallel_worker_threads( 39 unsigned int num, 40 unsigned int den, 41 unsigned int switch_pt) { 42 if (FLAG_IS_DEFAULT(ParallelGCThreads)) { 43 assert(ParallelGCThreads == 0, "Default ParallelGCThreads is not 0"); 44 // For very large machines, there are diminishing returns 45 // for large numbers of worker threads. Instead of 46 // hogging the whole system, use a fraction of the workers for every 47 // processor after the first 8. For example, on a 72 cpu machine 48 // and a chosen fraction of 5/8 49 // use 8 + (72 - 8) * (5/8) == 48 worker threads. 50 unsigned int ncpus = (unsigned int) os::active_processor_count(); 51 return (ncpus <= switch_pt) ? 52 ncpus : 53 (switch_pt + ((ncpus - switch_pt) * num) / den); 54 } else { 55 return ParallelGCThreads; 56 } 57 }
我们知道CMS初始标记只标记了GCRoot,并发标记是与应用线程并发进行的,如果某对象a刚被标记就变成了垃圾(没有引用指向它),CMS是没有任何办法的,这就产生了“浮动垃圾”,“浮动垃圾”只能等到下一次gc进行回收。
由于并发标记、并发清除都是与应用程序线程并发进行的,这就会产生一种危险,即并发gc过程中应用程序产生了新对象,而此时gc还未完成,还未释放出足够的空间存放这个新对象。可以通过UseCMSInitiatingOccupancyOnly来指定当老年代使用了多少空间后触发full gc,如果此后在gc过程中仍然出现了空间不足的情况,CMS就会出现“Concurrent Mode Failure”,这时jvm会启动后备预案,即临时启动Serial Old收集器来重新进行老年代的垃圾收集。
不管是minor gc还是major gc,都会涉及到老年代和新生代的gc root。在进行新生代垃圾回收时,GC root可能在老年代中,而GC root可达的对象在新生代中,这种情况对于新生代垃圾回收来说,老年代对象指向新生代对象的引用才是事实上的GC root。而对于GC root在新生代,GC root可达的对象在老年代中,这种情况对于新生代垃圾回收来说,老年代中的可达对象会被忽略。
疑惑,如果在并发清除时阶段产生了新对象,这些新对象是未被标记的,会清除这些对象?
参考:http://www.cnblogs.com/ityouknow/p/5614961.html
http://blog.csdn.net/bdx_hadoop_opt/article/details/38021209
https://plumbr.eu/blog/garbage-collection/minor-gc-vs-major-gc-vs-full-gc
http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html