FileOutputStream.writeBytes
来看FileOutputStream是如何writeBytes的
1 //JNI调用 2 private native void writeBytes(byte b[], int off, int len, boolean append) 3 throws IOException;
1 //找到了jni文件中的对应方法,writeBytes在io_util.h中 2 JNIEXPORT void JNICALL 3 Java_java_io_FileOutputStream_writeBytes(JNIEnv *env, 4 jobject this, jbyteArray bytes, jint off, jint len) { 5 writeBytes(env, this, bytes, off, len, fos_fd); 6 }
1 //找到了io_util.h文件中的writeBytes方法 2 void 3 writeBytes(JNIEnv *env, jobject this, jbyteArray bytes, 4 jint off, jint len, jfieldID fid) 5 { 6 jint n; 7 //先申请一个字节数组 8 char stackBuf[BUF_SIZE]; 9 char *buf = NULL; 10 FD fd; 11 12 if (IS_NULL(bytes)) { 13 JNU_ThrowNullPointerException(env, NULL); 14 return; 15 } 16 17 if (outOfBounds(env, off, len, bytes)) { 18 JNU_ThrowByName(env, "java/lang/IndexOutOfBoundsException", NULL); 19 return; 20 } 21 22 if (len == 0) { 23 return; 24 } else if (len > BUF_SIZE) {//如果要写入的字节数大于申请的字节数组长度则重新申请,之前是静态分配空间,这里是动态分配(最后需要手动回收) 25 buf = malloc(len);//在用户区申请len大小的空间 26 if (buf == NULL) { 27 JNU_ThrowOutOfMemoryError(env, NULL); 28 return; 29 } 30 } else { 31 buf = stackBuf; 32 } 33 //复制bytes置buf中,向java.net.Socket的SocketOutputStream中写数据也类似需要这样的复制工作 34 (*env)->GetByteArrayRegion(env, bytes, off, len, (jbyte *)buf); 35 36 if (!(*env)->ExceptionOccurred(env)) { 37 off = 0; 38 while (len > 0) { 39 fd = GET_FD(this, fid); 40 if (fd == -1) { 41 JNU_ThrowIOException(env, "Stream Closed"); 42 break; 43 } 44 //向文件中写数据,返回已写入的字节数 45 n = IO_Write(fd, buf+off, len); 46 if (n == JVM_IO_ERR) { 47 JNU_ThrowIOExceptionWithLastError(env, "Write error"); 48 break; 49 } else if (n == JVM_IO_INTR) { 50 JNU_ThrowByName(env, "java/io/InterruptedIOException", NULL); 51 break; 52 } 53 off += n; 54 len -= n; 55 } 56 } 57 if (buf != stackBuf) {//如果使用了动态空间分配则需要手动释放空间 58 free(buf); 59 } 60 }
由上面的c代码可以发现,java在写文件时首先需要将java堆中的数据(java堆中的字节数组)复制到用户空间的一个临时缓存中(由c代码申请的字节数组),然后再由c代码进行真正的写文件。
下图展示了c代码是如何读文件然后写文件的,该过程需要4次用户态/核心态切换(2次用户态->核心态,2次核心态->用户态),以及4次数据移动。
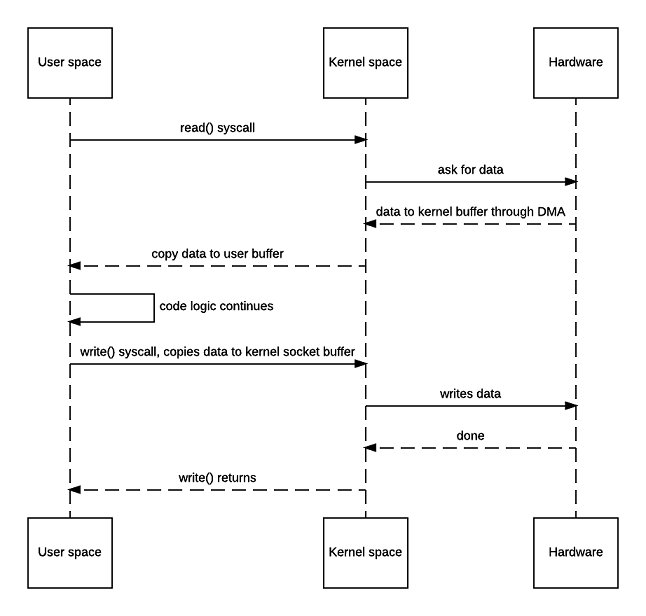
零拷贝
有时候我们只需要将数据原封不动的从数据源A复制到数据源B,如果仍然使用上面这种方式显然是低效的,因为不仅有多次用户态/核心态的转换,还需要多余的内核区与用户区间的数据复制。零拷贝很好的解决了上述问题,其避免了内核区与用户区间的数据复制,同时也只需要2次用户态/核心态的转换(调用sendfile是用户态->核心态,sendfile返回是核心态->用户态),如下图:

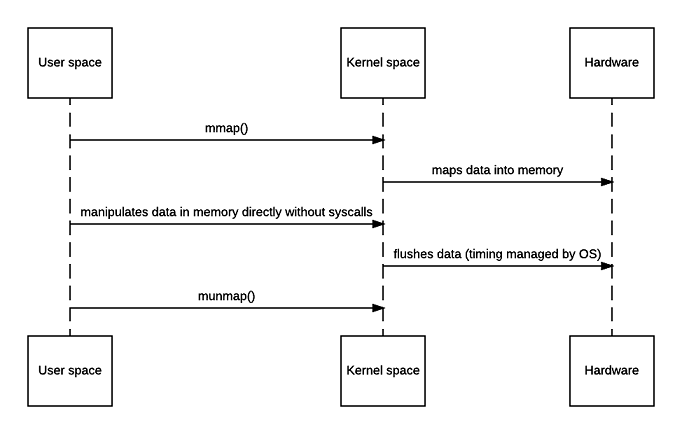
mmap
零拷贝固然是高效的,但由于中间没有用户态,所以用户无法对数据进行加工操作,所以memory-map就出现了。memory-map利用了os的虚拟存储系统,将磁盘中的文件映射在内存空间(内核区中的页表),读写时如普通访问类似,依然需要4次用户态/核心态转换。在程序访问文件时,文件数据会存入内核缓冲区,程序直接访问该内核缓冲区而不再需要复制内核缓冲区数据置用户缓冲区,提高了访问效率。但mmap并不总是高效的,因为其首先需要建立页表,在程序读取数据时如果数据不在内存中需要从磁盘中获取(缺页中断)。
ps:DMA即直接内存访问,是对于中断型内存访问的一种改进,内存与io接口的数据传输不再经过cpu,直接在二者间传输,cpu只会参与传输的开始和结束阶段。
参考:http://xcorpion.tech/2016/09/10/It-s-all-about-buffers-zero-copy-mmap-and-Java-NIO/
https://www.zhihu.com/question/60892134