优化技巧主要是面向DBA的,但我认为即使是开发人员也应该掌握这些技巧,因为不是每个开发团队都配有专门的DBA的。
第九步:合理组织数据库文件组和文件
创建SQL Server数据库时,数据库服务器会自动在文件系统上创建一系列的文件,之后创建的每一个数据库对象实际上都是存储在这些文件中的。SQL Server有下面三种文件:
1).mdf文件
这是最主要的数据文件,每个数据库只能有一个主数据文件,所有系统对象都存储在主数据文件中,如果不创建次要数据文件,所有用户对象(用户创建的数据库对象)也都存储在主数据文件中。
2).ndf文件
这些都是次要数据文件,它们是可选的,它们存储的都是用户创建的对象。
3).ldf文件
这些是事务日志文件,数量从一到几个不等,它里面存储的是事务日志。
默认情况下,创建SQL Server数据库时会自动创建主数据文件和事务日志文件,当然也可以修改这两个文件的属性,如保存路径。
文件组
为了便于管理和获得更好的性能,数据文件通常都进行了合理的分组,创建一个新的SQL Server数据库时,会自动创建主文件组,主数据文件就包含在主文件组中,主文件组也被设为默认组,因此所有新创建的用户对象都自动存储在主文件组中(具体说就是存储在主数据文件中)。
如果你想将你的用户对象(表、视图、存储过程和函数等)存储在次要数据文件中,那需要:
1)创建一个新的文件组,并将其设为默认文件组;
2)创建一个新的数据文件(.ndf),将其归于第一步创建的新文件组中。
以后创建的对象就会全部存储在次要文件组中了。
注意:事务日志文件不属于任何文件组。
文件/文件组组织最佳实践
如果你的数据库不大,那么默认的文件/文件组应该就能满足你的需要,但如果你的数据库变得很大时(假设有1000MB),你可以(应该)对文件/文件组进行调整以获得更好的性能,调整文件/文件组的最佳实践内容如下:
1)主文件组必须完全独立,它里面应该只存储系统对象,所有的用户对象都不应该放在主文件组中。主文件组也不应该设为默认组,将系统对象和用户对象分开可以获得更好的性能;
2)如果有多块硬盘,可以将每个文件组中的每个文件分配到每块硬盘上,这样可以实现分布式磁盘I/O,大大提高数据读写速度;
3)将访问频繁的表及其索引放到一个单独的文件组中,这样读取表数据和索引都会更快;
4)将访问频繁的包含Text和Image数据类型的列的表放到一个单独的文件组中,最好将其中的Text和Image列数据放在一个独立的硬盘中,这样检索该表的非Text和Image列时速度就不会受Text和Image列的影响;
5)将事务日志文件放在一个独立的硬盘上,千万不要和数据文件共用一块硬盘,日志操作属于写密集型操作,因此保证日志写入具有良好的I/O性能非常重要;
6)将“只读”表单独放到一个独立的文件组中,同样,将“只写”表单独放到一个文件组中,这样只读表的检索速度会更快,只写表的更新速度也会更快;
7)不要过度使用SQL Server的“自动增长”特性,因为自动增长的成本其实是很高的,设置“自动增长”值为一个合适的值,如一周,同样,也不要过度频繁地使用“自动收缩”特性,最好禁用掉自动收缩,改为手工收缩数据库大小,或使用调度操作,设置一个合理的时间间隔,如一个月。
第十步:在大表上应用分区
什么是表分区?
表分区就是将大表拆分成多个小表,以免检索数据时扫描的数据太多,这个思想参考了“分而治之”的理论。
当你的数据库中有一个大表(假设有上百万行记录),如果其它优化技巧都用上了,但查询速度仍然非常慢时,你就应该考虑对这个表进行分区了。首先来看一下分区的类型:
水平分区:假设有一个表包括千万行记录,为了便于理解,假设表有一个自动增长的主键字段(如id),我们可以将表拆分成10个独立的分区表,每个分区包含100万行记录,分区就要依据id字段的值实施,即第一个分区包含id值从1-1000000的记录,第二个分区包含1000001-2000000的记录,以此类推。这种以水平方向分割表的方式就叫做水平分区。
垂直分区:假设有一个表的列数和行数都非常多,其中某些列被经常访问,其余的列不是经常访问。由于表非常大,所有检索操作都很慢,因此需要基于频繁访问的列进行分区,这样我们可以将这个大表拆分成多个小表,每个小表由大表的一部分列组成,这种垂直拆分表的方法就叫做垂直分区。
另一个垂直分区的原则是按有索引的列无索引列进行拆分,但这种分区法需要小心,因为如果任何查询都涉及到检索这两个分区,SQL引擎不得不连接这两个分区,那样的话性能反而会低。
本文主要对水平分区做一介绍。
分区最佳实践
1)将大表分区后,将每个分区放在一个独立的文件中,并将这个文件存放在独立的硬盘上,这样数据库引擎可以同时并行检索多块硬盘上的不同数据文件,提高并发读写速度;
2)对于历史数据,可以考虑基于历史数据的“年龄”进行分区,例如,假设表中存储的是订单数据,可以使用订单日期列作为分区的依据,如将每年的订单数据做成一个分区。
如何分区?
假设Order表中包含了四年(1999-2002)的订单数据,有上百万的记录,那如果要对这个表进行分区,采取的步骤如下:
1)添加文件组
使用下面的命令创建一个文件组:
ALTER DATABASE OrderDB ADD FILEGROUP [1999]
ALTER DATABASE OrderDB ADD FILE (NAME = N'1999', FILENAME
= N'C:OrderDB1999.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO
FILEGROUP [1999]
通过上面的语句我们添加了一个文件组1999,然后增加了一个次要数据文件“C:OrderDB1999.ndf”到这个文件组中。
使用上面的命令再创建三个文件组2000,2001和2002,每个文件组存储一年的销售数据。
2)创建分区函数
分区函数是定义分界点的一个对象,使用下面的命令创建分区函数:
CREATE PARTITION FUNCTION FNOrderDateRange (DateTime) AS
RANGE LEFT FOR VALUES ('19991231', '20001231', '20011231')
上面的分区函数指定:
DateTime<=1999/12/31的记录进入第一个分区;
DateTime > 1999/12/31 且 <= 2000/12/31的记录进入第二个分区;
DateTime > 2000/12/31 且 <= 2001/12/31的记录进入第三个分区;
DateTime > 2001/12/31的记录进入第四个分区。
RANGE LEFT指定应该进入左边分区的边界值,例如小于或等于1999/12/31的值都应该进入第一个分区,下一个值就应该进入第二个分区了。如果使用RANGE RIGHT,边界值以及大于边界值的值都应该进入右边的分区,因此在这个例子中,边界值2000/12/31就应该进入第二个分区,小于这个边界值的值就应该进入第一个分区。
3)创建分区方案
通过分区方案在表/索引的分区和存储它们的文件组之间建立映射关系。创建分区方案的命令如下:
CREATE PARTITION SCHEME OrderDatePScheme AS PARTITION FNOrderDateRange
TO ([1999], [2000], [2001], [2002])
在上面的命令中,我们指定了:
第一个分区应该进入1999文件组;
第二个分区就进入2000文件组;
第三个分区进入2001文件组;
第四个分区进入2002文件组。
4)在表上应用分区
至此,我们定义了必要的分区原则,现在需要做的就是给表分区了。首先使用DROP INDEX命令删除表上现有的聚集索引,通常主键上有聚集索引,如果是删除主键上的索引,还可以通过DROP CONSTRAINT删除主键来间接删除主键上的索引,如下面的命令删除PK_Orders主键:
ALTER TABLE Orders DROP CONSTRAINT PK_Orders;
在分区方案上重新创建聚集索引,命令如下:
CREATE UNIQUE CLUSTERED INDEX PK_Orders ON Orders(OrderDate) ON
OrderDatePScheme (OrderDate)
假设OrderDate列的数据在表中是唯一的,表将基于分区方案OrderDatePScheme被分区,最终被分成四个小的部分,存放在四个文件组中。如果你对如何分区还有不清楚的地方,建议你去看看微软的官方文章“SQL Server 2005中的分区表和索引”(地址:http://msdn.microsoft.com/en-us/library/ms345146%28SQL.90%29.aspx)。
第十一步:使用TSQL模板更好地管理DBMS对象(额外的一步)
为了更好地管理DBMS对象(存储过程,函数,视图,触发器等),需要遵循一致的结构,但由于某些原因(主要是时间限制),我们未能维护一个一致的结构,因此后来遇到性能问题或其它原因需要重新调试这些代码时,那感觉就像是做噩梦。
为了帮助大家更好地管理DBMS对象,我创建了一些TSQL模板,利用这些模板你可以快速地开发出结构一致的DBMS对象。
如果你的团队有人专门负责检查团队成员编写的TSQL代码,在这些模板中专门有一个“审查”段落用来描写审查意见。
我提交几个常见的DBMS对象模板,它们是:
Template_StoredProcedure.txt:存储过程模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_StoredProcedure.txt)
Template_View.txt:视图模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_Trigger.txt)
Template_Trigger.txt:触发器模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_ScalarFunction.txt)
Template_ScalarFunction.txt:标量函数模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_TableValuedFunction.txt)
emplate_TableValuedFunction.txt:表值函数模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_View.txt)
1)如何创建模板?
首先下载前面给出的模板代码,然打开SQL Server管理控制台,点击“查看”*“模板浏览器”;
点击“存储过程”节点,点击右键,在弹出的菜单中选择“新建”*“模板”,为模板取一个易懂的名字;
在新创建的模板上点击右键,选择“编辑”,在弹出的窗口中输入身份验证信息,点击“连接”;
连接成功后,在编辑器中打开下载的Template_StoredProcedure.txt,拷贝文件中的内容粘贴到新建的模板中,然后点击“保存”。
上面是创建一个存储过程模板的过程,创建其它DBMS对象过程类似。
2)如何使用模板?
创建好模板后,下面就演示如何使用模板了。
首先在模板浏览器中,双击刚刚创建的存储过程模板,弹出身份验证对话框,输入对应的身份信息,点击“连接”;
连接成功后,模板将会在编辑器中打开,变量将会赋上适当的值;
按Ctrl+Shift+M为模板指定值,如下图所示;
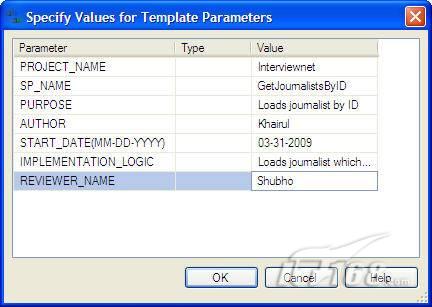
图 1 为模板参数指定值
点击“OK”,然后在SQL Server管理控制台中选择目标数据库,然后点击“执行”按钮;
如果一切顺利,存储过程就创建成功了。你可以根据上面的步骤创建其它DBMS对象。
小结
优化讲究的是一种“心态”,在优化数据库性能时,首先要相信性能问题总是可以解决的,然后就是结合经验和最佳实践努力进行优化,最重要的是要尽量预防性能问题的发生,在开发和部署期间,要利用一切可利用的技术和经验进行提前评估,千万不要等问题出现了才去想办法解决,在开发期间多花一个小时实施最佳实践,最后可能会给你节约上百小时的故障诊断和排除时间,要学会聪明地工作,而不是辛苦地工作!