grep、cut、awk、sed 常常应用在查找日志、数据、输出结果等等,并对我们想要的数据进行提取。
通常grep,sed命令是对行进行提取,cut跟awk是对列进行提取
处理海量数据之grep命令
grep应用场景:
通常对数据进行 行的提取
语法:
grep [选项]...[内容]...[file]
-v #对内容进行取反提取
-n #对提取的内容显示行号(原文件中对应行号)
-w #精确匹配
-i #忽略大小写
^ #匹配开头行首
-E #正则匹配
系统文件进行实例演示:
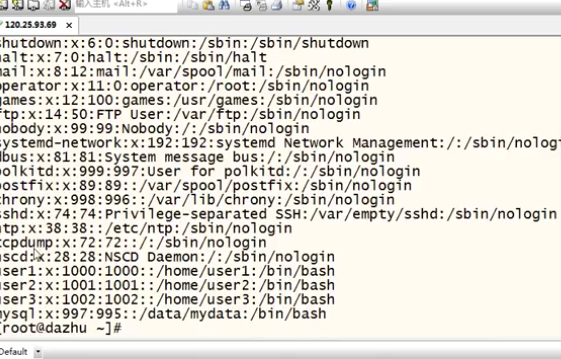
1. 提取是区分大小写的提取
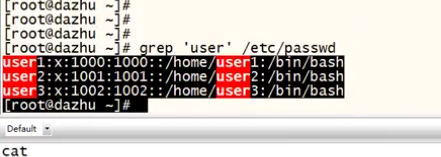
2. -v 提取上述以外的内容
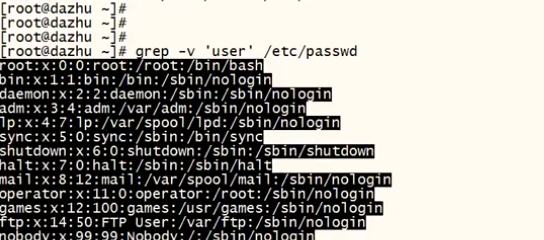
-w 全字符匹配
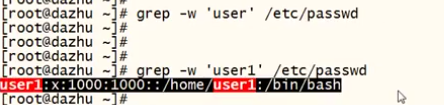
-i

^ 开头
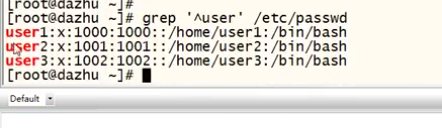
-E 正则

处理海量数据之cut命令
cut应用场景:
通常对数据进行列的提取
语法:
cut [选项]...[file]
-d #指定分割符
-f #指定截取区域
-c #以字符为单位进行分割
注意:不加-d选项,默认为制表符,不是空格
仍然以系统文件为实例
-d与-f:
eg:
以':'为分隔符,截取出/etc/passwd的第一列跟第三列
cut -d ':' -f 1,3 /etc/passwd
eg:
以':'为分隔符,截取出/etc/passwd的第一列到第三列
cut -d ':' -f 1-3 /etc/passwd
eg:
以':'为分隔符,截取出/etc/passwd的第二列到最后一列
cut -d ':' -f 2- /etc/passwd
-c:
eg:
截取/etc/passwd文件从第二个字符到第九个字符
cut -c 2-9 /etc/passwd
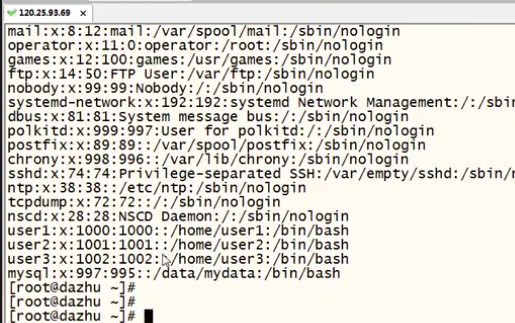
eg:
截取linux上面所有可登陆普通用户
/bin/bash #代表可以登录的用户
/sbin/nologin #代表不可以登录的用户
grep '/bin/bash' /etc/passwd | cut -d ':' -f 1 | grep -v root
cut -d ':' -f 1--------第一列代表所有用户

-v #对内容进行取反提取

处理海量数据之awk命令
awk的简介:
其实一门编程语言,支持条件判断,数组,循环等功能,与grep,sed被称为 linux三剑客
awk的应用场景:
通常对数据进行 列的提取 先执行条件再执行动作
语法:
awk '条件 {执行动作}'文件名
awk '条件1 {执行动作} 条件2 {执行动作} ...' 文件名
或awk [选项] '条件1 {执行动作} 条件2 {执行动作} ...' 文件名
特殊要点与举例说明:
printf #格式化输出,不会自动换行。
( %ns:字符串型,n代表有多少个字符;
%ni:整型,n代表输出几个数字;
%.nf:浮点型,n代表的是小数点后有多少个小数)
print #打印出内容,默认会自动换行
#制表符(tab键 )
#换行符
eg:

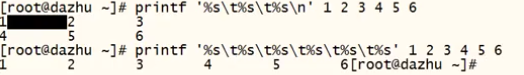

注意:%s 是字符串 %i 是整形
df -h 磁盘空间分区使用率
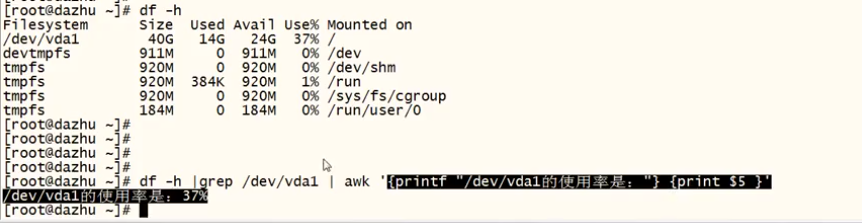
df -h |grep /dev/vda1 | awk '{printf "/dev/vda1的使用率是:"} {print $5 }'
与之前传参不同: $1 #代表第一列 $2 #代表第二列 $0 #代表一整行
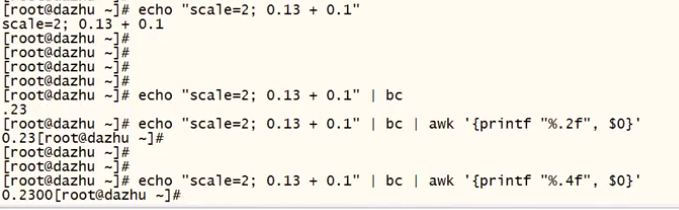
%.nf:浮点型,n代表的是小数点后有多少个小数 换行
小数:echo "scale=2; 0.13 + 0.1" | bc | awk '{printf "%.2f ", $0}'
-F #指定分割符
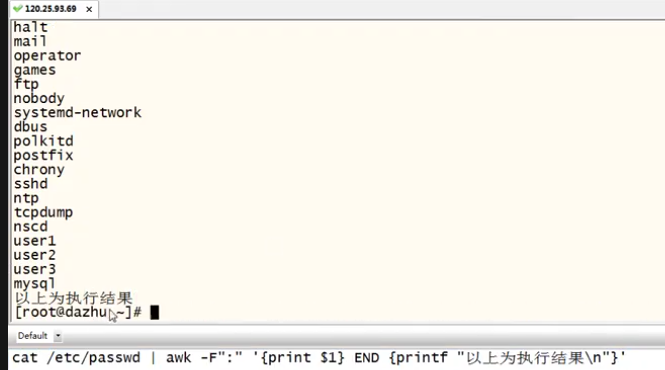
eg:cat /etc/passwd | awk -F":" '{print $1}'
以:为分隔符打印出第一列
另一种方式

BEGIN #在读取所有行内容前就开始执行,常常被用于修改内置变量的值
FS #BEGIN时定义分割符
eg:cat /etc/passwd | awk 'BEGIN {FS=":"} {print $1}'
![]()
END #结束的时候 执行 (在最后的时刻才会执行)
NR #行号
eg:df -h | awk 'NR==2 {print $5}'
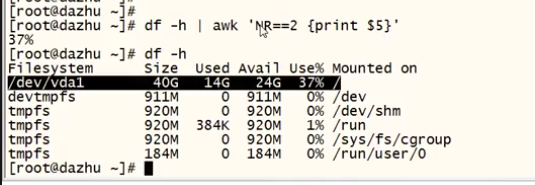
打印多行:
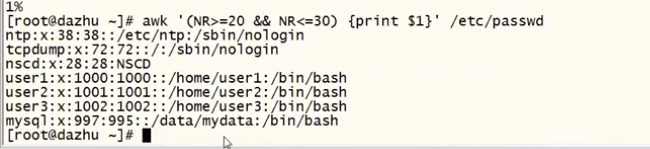

打印行数

处理海量数据之sed命令
sed的应用场景:(只更改输出 不会对源文件进行操作)
主要对数据进行处理(选取,新增,替换,删除,搜索)
sed语法:
sed [选项] [动作] 文件名
常见的选项与参数:
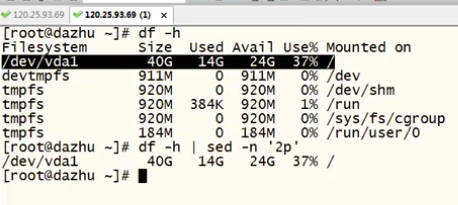
-n #把匹配到的行输出打印到屏幕
p #以行为单位进行查询,通常与-n一起使用
eg:
df -h | sed -n '2p'
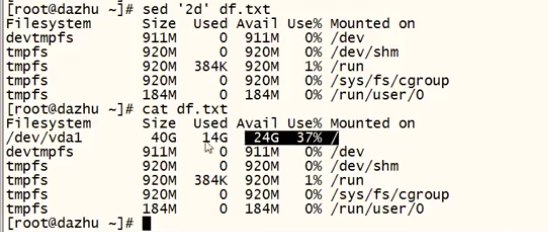
d #删除 (只是打印的内容看不见 并不是对原文件删除)
eg:
sed '2d' df.txt
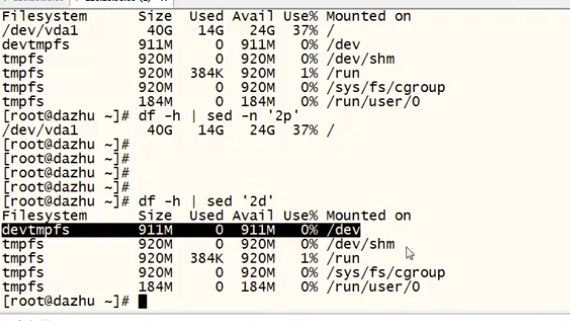
源文件保留
a #在行的下面插入新的内容
eg: sed '2a 1234567890' df.txt
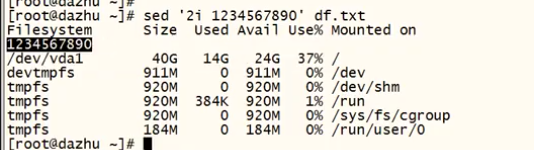
i #在行的上面插入新的内容
eg: sed '2i 1234567890' df.txt
c #替换
eg: sed '2c 1234567890' df.txt
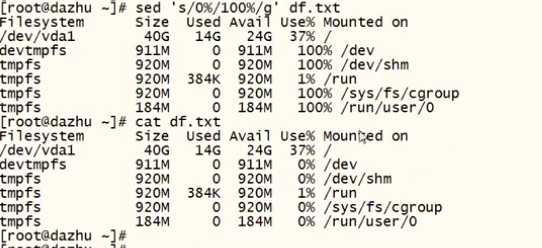
s/要被取代的内容/新的字符串/g #指定内容进行替换
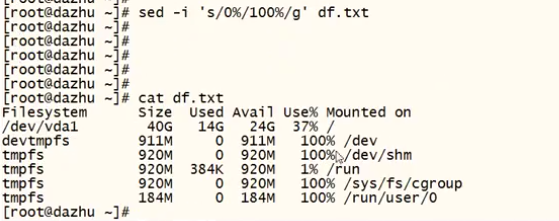
-i #对源文件进行修改(高危操作,慎用,用之前需要备份源文件)
修改 不打印
搜索:(同grep)
在文件中搜索内容 '/100%/p'
eg:
cat -n df.txt | sed -n '/100%/p'

-e #表示可以执行多条动作 (注意)
eg:
cat -n df.txt | sed -n -e 's/100%/100%-----100%/g' -e '/100%-----100%/p'
