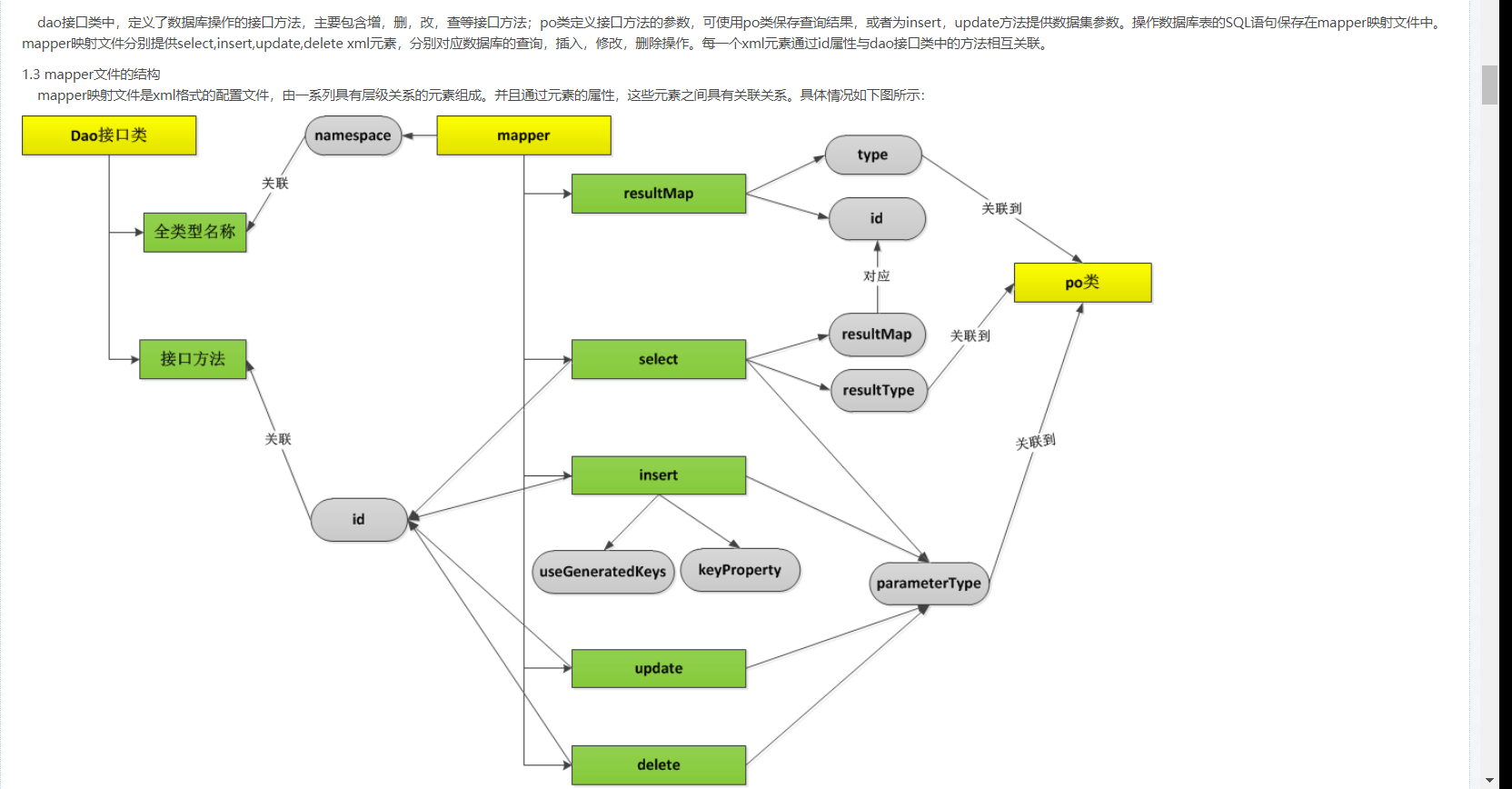
mybatis总结:
-
mybatis最基础的版本是一个基于配置文件的dao层框架,通过在配置文件中配置实现对数据库的操作
- 配置mybatis-config.xml:使用的日志类。
- 然后配置环境,需要配置事务管理器,数据源。
- 最后就是配置映射文件的扫描,最基础的资源扫描,后面是类扫描,最后是包扫描。
- 因为映射文件中涉及到很多的类需要封装,而所有的类在分装的时候写全类名比较麻烦,所以mybatis支持给类型区别名
- 对于写资源文件,最重要的就有4样东西
- namespace: 没有配置对应的接口的时候可以随意,用来给不同的操作数据库的函数不同的命名空间。
- 方法的名字id
- 参数的拆分
- 结果的封装。ResultMapper
- 数据库的调用:
- 读入总的配置文件
- 根据配置文件,创建sql的对话工厂
- 有了工厂创建一个个sqlSession
- 然后根据sqlSession调用方法,通过selectXXX和updataXXX()实现查询和修改,参数是资源文件中定义的id坐标,包含命名看见,和相应的传入的参数。
- 提交修改。
根据上面的基础操作衍生处了一些列的问题:
-
每次传入的方法,或者返回的方法名称复杂,不友好
解决方法:别名TypeAlias
- 最低级的在mybatis-config.xml中配置所有的别名,注意:扫描包,大小写不区分
- 可以通过在类对象上@Alias注解取别名,可以覆盖上一种方式
- 适用范围所有的配置文件
-
传递参数复杂:
- 原始的传递参数的方式有:(参数可以不写,自动判定)
- 基础的数据类型
- 传递一个对现象,在sql语句中直接使用它的属性进行拆包
- 传递多个参数,将参数封装成一个HashMap的形式。Map<string,object>
- 现在的方式:使用接口类来代替原本的xml配置
- 核心思想: 设置接口,然后让mybatis自动注入查询方法。xml文件是用来注入的方法,接口提供方法调用。
- 前提:
- xml的命名空间和包名相似。
- 方法名和id相似
- 返回值的基础类型相同。如果是列表不影响。
- ResultMapper需要进行重新封装数据,如果属性名完全形同,可以使用默认的封装器。
- 参数:
- 除了基本的,不需要封装多参数,使用paramk(k>=1)和argx(x>=0)开始
- @Param("name") 给参数重命名,方便后米娜的引用
- 原始的传递参数的方式有:(参数可以不写,自动判定)
-
如何避免mapper文件的方法注入:
解决方法:注解注入方法
- @Select
- @Update
- @Delete
- @Insert
-
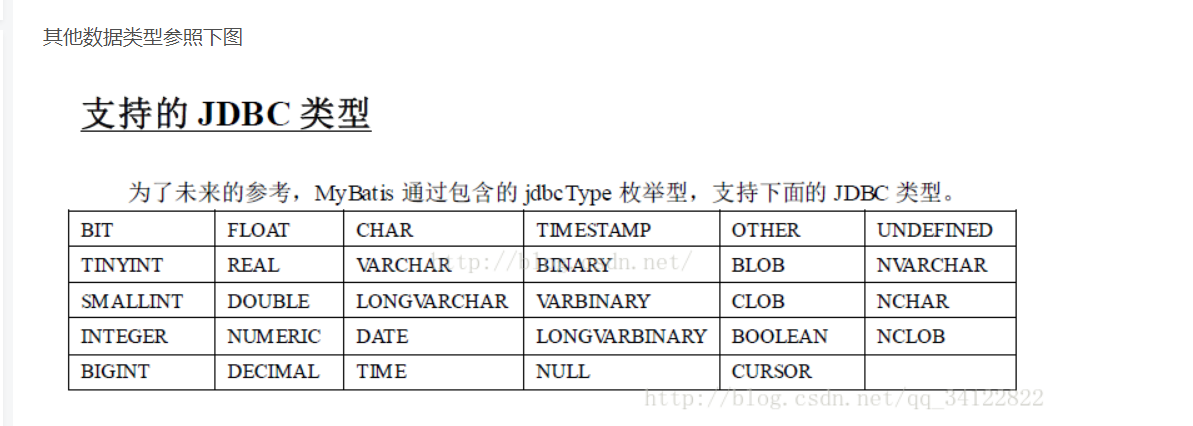
插入的值为空值
<insert id="save" parameterType="User">
insert into USER(USER_GUID,USER_NAME,USER_DESC)
values (#{userGuid, jdbcType=VARCHAR}, #{userName, jdbcType=VARCHAR},#{userDesc, jdbcType=VARCHAR})
</insert>
-
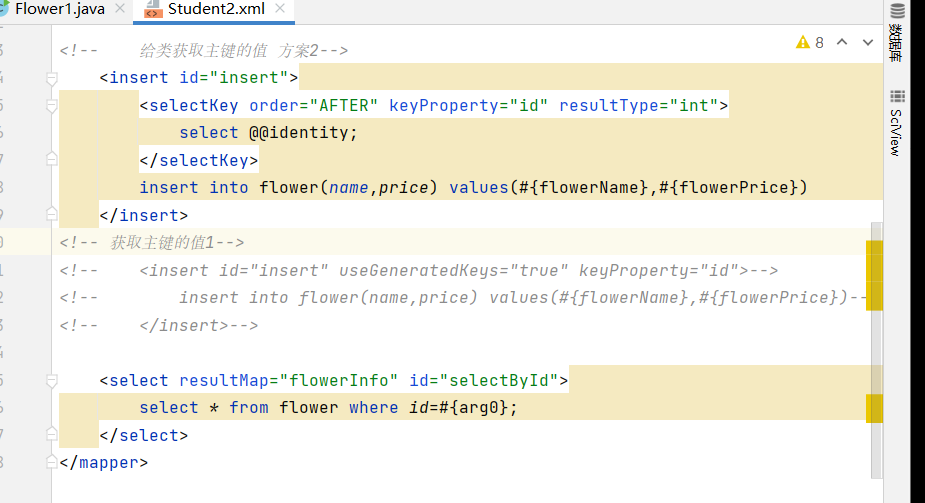
自动生成主键
Mybatis 配置文件 useGeneratedKeys 参数只针对 insert 语句生效,默认为 false。当设置为 true 时,表示如果插入的表以自增列为主键,则允许 JDBC 支持自动生成主键,并可将自动生成的主键返回。
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into flower(name,price) values(#{flowerName},#{flowerPrice})
</insert>
或者分成**两次查询**:**\<selectKey>**标签
<insert id="insert">
<selectKey order="AFTER" keyProperty="id" resultType="int">
select @@identity;
</selectKey>
insert into flower(name,price) values(#{flowerName},#{flowerPrice})
</insert>
after是插入之后查询id返回给实体类
- 注解自动生成主键
@Mapper
public interface UserMapper
{
@Insert("insert into tbl_user (name, age) values (#{name}, #{age})")
@Options(useGeneratedKeys=true, keyProperty="userId", keyColumn="id")
void insertUser(User user);
}
-
select语句太长,或者需要条件判断
解决方法:OGNL标签动态生成sql语句。
-
多表查询
-
分为联合查询和嵌入查询
-
联合查询,sql语句多表查询,查询的内容一起嵌入到一个resultMapper里面
-
嵌入查询,查询里面指定另一个查询并指定连接词column。因为一般属性在字段设计的时候,每个类会有一个连接属性,数据库中不存在,需要嵌入一层查询。
-
-
<select id="selectAll" resultMap="rm2">
select * from class;
</select>
<resultMap id="rm2" type="class">
<id property="classno" column="classno"/>
<result property="className" column="className"/>
<collection property="studentList" column="classno" ofType="stu" select="com.test.mapper.StuDao.selectByClassNo" fetchType="lazy"/>
</resultMap>
<select id="selectByClassNo" resultType="stu">
select <include refid="stu"/> from stu
<where>
classno = #{param1}
</where>
</select>
collection中可以再配置,实现映射。
javaType彻底封装之后的返回值,相当于二次封装。
column连接属性
-
注解驱动
-
@Result 实现结果集封装 @Results 可以与@Result 一起使用,封装多个结果集 @ResultMap 实现引用@Results 定义的封装 - @Result代替了ResultMapper,本质是同一个东西
- @Result代替了所有属性的配对
- id代表主键
- one一对一查询
- many1对多查询
@Results(id = "rm9",value ={
@Result(id = true, property = "sid", column = "sid"),
@Result(property = "sname",column = "sname"),
@Result(property = "sex", column = "sex"),
@Result(property = "classno",column = "classno"),
@Result(property = "aClass", javaType = Class.class,column = "classno", one=@One(select = "com.test.mapper.ClassDao2.selectOne",fetchType = FetchType.LAZY))
})//只需要配特殊的映射
@Select("select sid, sname, sex, classno from stu")
List<Student> selectAll1();
@Select("select * from class where classno = #{param1}")
public Class selectOne1();
-
一对多查询的注意点
- javaType="list"实际的返回类型
- ofType:子元素类型,所有的名称要么是全类名,要么是别名
<collection property="studentList" column="classno" javaType="list" ofType="stu" select="com.test.mapper.StuDao.selectByClassNo" fetchType="lazy"/>
1.配置文件的参数
mapper
package包扫描
<mappers>
<!-- <mapper resource="com/test/mapper/StudentMapper.xml"/>-->
<!-- <mapper class="com.test.mapper.Student2"/>-->
<package name="com.test.mapper"/>
</mappers>
工作原理
- 先去找所有的接口
- 然后根绝接口名称去找对应的xml.
- 所以接口名称必须和xml保持一致。
- 如果不是包扫描没必要保持一致,只需要域名和接口的完全限定名一致就好了。

扫描xml
根据域名去找对应的接口。所以域名和接口要一致。
2.映射器配置文件和全局配置文件
parameterType
可写可以不写,会自动识别输入的参数。要写就需要写对,可省略
传参的三种方法
- 传入普通数据类型
- 传入对象
- 传入HashMap,通过#{关键字};
传播参数的个数只能是一个。
ResultType
为int的时候可以省略。
ResultMapper
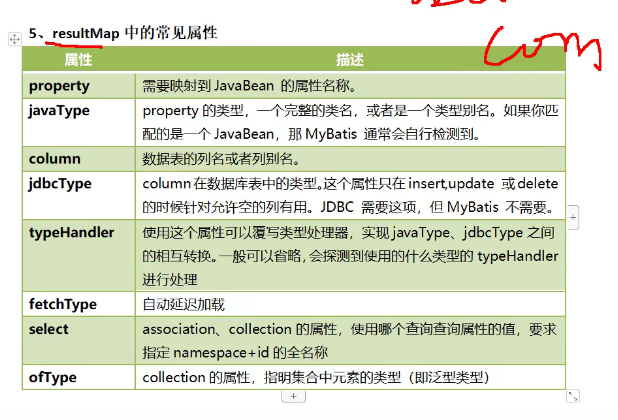
如果类的属性和表格的字段不对应,我们需要构造一个属性映射器,ResultMapper的作用。
- id类型映射器的标识符
- type映射到类。
- <id>和<reuslt>主键标签和元素标签。
- collection是类对象的映射标签。
在select标签中结果自动映射到映射器上。
不能自动对应就是Null
解决自动映射的方法
- 给mysql查询的表格取别名
- 手动映射ResultType
3.1映射器
可以构造一个接口名字和xml类的id相同,输入参数的类型相同,返回值的类型也相同(可以是单个实体也可以是数组),函数的名字也相同。xml文件生成的类会自动继承接口函数。然后就可以通过调用接口函数来调用语句。
1.insert
-
正常的插入
-
有主键自增的情况下,可以正常添加,或者向mybatis声明谁是自增主键,mybatis会自动调用jdbc.getGeneratedKeys()获取主键的自增数,然后赋值给当前的对象stuId,并添加数据。
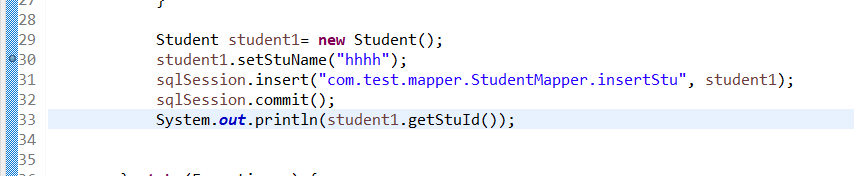
stuId被自动赋值。
2.sql语句定义被重复使用的语句块<include/>
<sql id="userColumns"> id,username,password</sql>
<select id="selectUser" parameterType="int" resultType="hashmap">
select <include refid="userColumns"/>
from userinfo where id = #{id};
</select>
#和$的区别
#{}代表占位符,由preparedStatement自动通过调用setXXX()自动填装。
${}相当于拼接, 会自动取出数据,进行字符串的拼接,一般需要加引号。
3.日志文件log4j

文件配置类log4j.properties一般放到src下面就是源目录下面,可以叫java也可以叫src。
日志级别
日志有多个级别。低级别的可以输出高级别的问题。
例如上面的debug可以输出所有类型的信息而error只能输出error和fatal两类的信息。
全局级别和局部级别
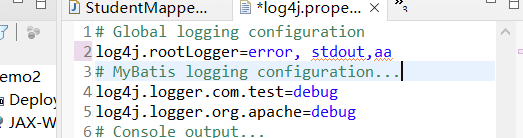
- log4j.rootLogger是全局级别的
- 下面的两条是局部级别的debug,写的是命名空间,是我们mapper类配置文件的命名空间,该命名空间下的所有方法自动调整级别。
- 命名空间可以自己随意定义。
为什么是针对xml的namespace。
xml的域名就是xml的名字。如果使用mapper接口代理。
域名就不能随便叫了,可以看成接口的实现类,所以域名需要和接口的名字相同。
4.typeAliases
属性值:
<typeAliase type="" alias="">
- type 原始的类的完全限定
- alias 别名的名称
给多个类取别名
直接导入包。
- <package name="">
- alias不用写,别名就是类名,不区分任何大小写。
基本类型
已经给基本类型自己取了别名。所以可以直接用,首字母都是小写的。
如果有list,要写全路径。
@Alias()
会自动覆盖typeAliase里面的配置,使之失效。
3.2属性文件properties
dtd是规定标签的排放顺序的。
根据错误提示重新排放标签。
再mybatis.xml通过properties标签引用,resources,文件的路径。

日志类型可以指定也可以不指定,不指定他会自己去找。
4.基操--增删改查
三种类型:
-
selectList("id的全限定")。
-
selectOne("")
-
返回值为map。 selectMap("id",”key是哪个字段“)
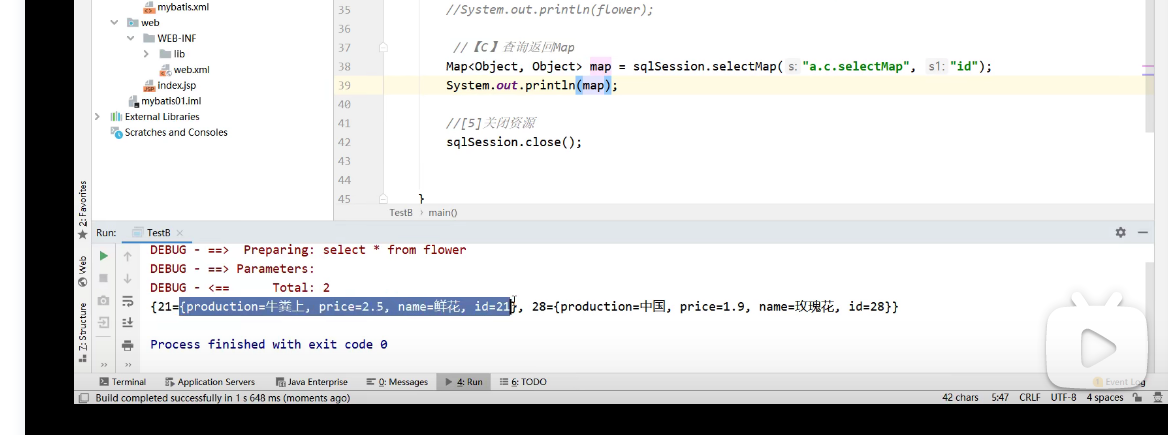
优点:方便找对应的值,如果用主键作为key,可以快速的找到对应主键的内容
1.模糊查询
- 注意点,字符串中#{}不会被解析,会被当做字符窜。
- 传入拼好的参数 “%baidu%” 或者传入再拼接 concat('%',param,'%')。
2.增删改
修改手动提交。
- sqlSession.close()
- 或者我们在构造openSession的时候传入true,openSession(true)

3.自动获取主键自增的值
可以用useGeneralKey自动调用主键自增函数,并赋值给插入对象。然后我们插入到对象就有主键了。
给对象获取主键。
一共两种方案,第一种方案更安全,本质是插入之后在查询,在多线程中是安全的。
当多个人一起操作的时候,获取到的主键值可能出现错乱,故第二种方案不一定正确。
5.Mapper高级代理
mapper代理就是一种接口的绑定。
- 域名和类名保持一致
- id需要和方法名保持一致
返回值了类型可以一定程度的不一致,包括参数类型。
传入多个参数
在xml文件中,参数可以不写,会自动识别,如果写输入参数只能写一个,因此我们需要对输出的参数进行包装,可以用hashMap来包装。
如果时用mapper的代理接口,我们可以在代理接口中设计诸多的参数,然后传入多个参数,此时在xml中不必写参数。
xml和mapper接口中的参数如何配对
- 在xml中使用paramx指代mapper接口方法中的参数。x代表的是位置。从1开始。
- 也可以使用argx代表。x从0开始。

- 通过注解实现。注解告诉xml,每个参数在xml中对应的参数名。‘
- 传入一个类,自动拆包,将属性对应起来。如果传入多个类,则是需要用arg或param或注解指定哪个类的属性。
4.动态sql
所有标签都是为了构造合法的sql语句,主要用于动态的生成字符窜。
1.if标签
- test是判断条件,里面写OGNL
<select id="selectMore" resultMap="flowerInfo">
select * from flower where 1=1
-- OGNL表达式
<if test="param1!=null and param1!=''">
and name=#{param1}
</if>
<if test="param2!=null and param2!=0">
and price=#{param2}
</if>
</select>
2.where标签
作用,自动去添加where关键字。自动的去掉第一个and。
<select id="selectMore" resultMap="flowerInfo">
select * from flower
-- OGNL表达式
<where>
<if test="param1!=null and param1!=''">
and name=#{param1}
</if>
<if test="param2!=null and param2!=0">
and price=#{param2}
</if>
</where>
</select>
3.choose标签
多种情况选择一种,类似于if else
<select id="selectMore2" resultMap="flowerInfo">
select * from flower
<where>
<choose>
<when test="param1!=null and param1=''">
name=#{param1}
</when>
<!--成立了就不继续执行-->
<when test="param2!=0">
and price=#{param2}
</when>
<otherwise>
1 = 1
</otherwise>
</choose>
</where>
</select>
4.set标签
只能用在修改里面。
会自动的去添加set关键字并删除最后的逗号。
<update>
update flower
<set>
<if test="param1!=null">
name = #{param1},
</if>
<!--自动去除的逗号-->
<if test="param2!=0">
price=#{param2}
</if>
</set>
where id = #{param3};
</update>
5.trim标签
前后缀处理
- prefix添加前缀
- prefixOverrides去除前缀,如果存在
- suffix添加后缀
- suffixOverrides去除后缀,如果存在
- 功能和where和set重合
<update>
update flower
<!--添加前缀set,去除可能的后缀,-->
<trim prefix="set" suffixOverrides=",">
<if test="param1!=null">
name = #{param1},
</if>
<!--自动去除的逗号-->
<if test="param2!=0">
price=#{param2}
</if>
</trim>
where id = #{param3};
</update>
6.forEach
如何删除的内容是个数组或者集合,那么sql语句就很难写,因为数组或者集合中的元素没任何规律。
需要对集合进行遍历,forEach将集合的元素变成一个字符窜。
实际上传入多个值的时候,mybatis自动封装成一个map,List的关键字是list,数组的关键字是array,所以我们通过关键字使用变量。
<delete>
delete from flower where id in
<!-- collection 集合类型 list或者array item指向集合中的每个元素-->
<foreach collection="list" item="i" open="(" close=")", separator=",">
${i}
</foreach>
</delete>
7.Bind
拼接字符窜的形成一个新串的工具,功能类似于concat。
value值的书写就是字符窜相加。
<select id="selectMore4" resultType="flowerInfo">
select * from flower
<where>
<if test="param1!=null">
<!--新的变量名和变量值,OGNL语言字符窜需要用‘’标识出来-->
<bind name="pa" value="'%'+param1+'%'"/>
name like #{pa}
</if>
</where>
</select>
8.sql标签
select语句查*号效率比较低。
用来规定公共的代码片段,通过include来引用
<include refid="sqa"/>
sql语句可以定义代码块
<sql id="sqa">
id,name,price,production
</sql>
<select id="" resultType="flowerInfo">
select <include refid="sqa"/> from flower
</select>
5.多表查询
N+1模式
对于数据库中的外键,我们在java类中用一个类引用成员代替外键连接的表,来存储两张联合搜索的结果。
association一对一关联
在手动映射器上设置关联函数。
- select 希望执行那一条sql语句。可以直接用namespace+id来定位查询语句。
- column 作为参数的列(就是连接的列)
- javaType返回值类型
- property 结果保存到到哪个属性。
利用的是手动映射ResultMap,无法找到某个对应映射的数据的时候,再次激活一个查询语句。
<resultMap id="rm2" type="stu">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<result property="sex" column="sex"/>
<result property="classno" column="classno"/>
<!-- aclass属性的类型是class,关联的语句时selectOne(可以是sql语句也可以是引用一个查询块) column是连接字段-->
<association property="aClass" javaType="class" column="classno" select="com.test.mapper.ClassDao.selectOne"/>
</resultMap>
<select id="selectAll" resultMap="rm2">
select <include refid="stu"/> from stu;
</select>
association支持多层关联
- 不仅支持关联函数的返回结果
- 也可以关联一个手动映射器。
- 二次关联可以写成嵌套型
分开写
<resultMap type="Card" id="cardMap">
<id property="cardId"
column="card_id"/>
<result property="cardNum"
column="card_num"/>
<result property="address"
column="address"/>
</resultMap>
<resultMap type="User" id="userMap">
<result property="userName"
column="user_name"/>
<result property="age"
column="age"/>
<association property="card"
resultMap="cardMap">
</association>
</resultMap>
嵌套型
<resultMap type="User" id="userMap">
<result property="userName"
column="user_name"/>
<result property="age"
column="age"/>
<association
property="card"
column="card_id"
javaType="Card">
<id property="cardId"
column="card_id"/>
<result property="cardNum"
column="card_num"/>
<result property="address"
column="address"/>
</association>
</resultMap>
-
column:当关联的语句需要多个参数的时候,我们用map将多个参数进行封装。
<collection property="htAuthorityDTO" ofType="com.sailod.shiro.dto.HtAuthorityDTO" select="selectAuthority" column="{htAuthorityId2 = htAuthorityId ,currentUserId2 = currentUserId}" > -
javaType: 指定返回的类型java.util.ArrayList
-
ofType集合所包含的类型。
collection:一对多关联
对应一个集合,集合对应的是student
<resultMap id="BaseResultMap" type="com.xxx.modules.xxx.entity.Question" >
<id column="id" property="id" jdbcType="VARCHAR" />
<result column="content" property="content" jdbcType="VARCHAR" />
<result column="type" property="type" jdbcType="VARCHAR" />
<result column="sort" property="sort" jdbcType="INTEGER" />
<collection property="options" javaType="java.util.ArrayList" ofType="com.xxx.modules.data.entity.QuestionOption">
<id column="o_id" property="id" jdbcType="VARCHAR" />
<result column="o_content" property="content" jdbcType="VARCHAR" />
<result column="o_sort" property="sort" jdbcType="INTEGER" />
</collection>
<!-- 列的别名 o_id,o_content,o_sort , 起别名是因为主子表都有这几个字段
这里要写 ofType, javaType还是可以不写 -->
</resultMap>
多表查询语句
如果搜索的内容是双表连接,可以把公共字段省略,两张表的搜索结果,我们根据类直接的关系可以分为主类和附加类。 主类的重叠字段不重复,附加类自动变成列表,接收字段一个都不能
<resultMap id="rm3" type="class">
<id property="classno" column="classno"/>
<result property="className" column="className"/>
<collection property="list" ofType="stu">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<result property="sex" column="sex"/>
<result property="classno" column="classno"/>
</collection>
</resultMap>
总结
- 业务代码,通过java代码实现
- N+1,用association 和collection集合实现,多次查询
- 多表查询SQL。(ResultMap可以通过注解实现。)
加载方式
加载方式分为两种:延迟加载和积极加载,就是加载属性时使用,一般用于多表查询,先查询一部分结果。
积极加载
如上面的例子,如果我们使用了sql关联语法,在选所有班级时候对应的学生也会加载 ,这叫积极加载。
延迟记载就是不先加载关联。
- 通过全局配置实现, setting name="lazyLoadingEnabled" value="true",这个每个属性只有用的时候才加载。
- 关闭每个属性的懒加载。<setting name="aggressiveLazyLoading" value="false"/>
- 开启特殊属性进行懒加载。使用标签(collection)的 fetchType="lazy"
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
特点:
懒加载就是使用属性时加载对应的属性。
缓存
直接从缓存中拿数据,减小服务器的压力,尤其是查询次数多的情况。mybatis分为一级缓存和二级缓存。
List<Class> classes = classDao.selectAll();
classDao.selectAll();
第二次查询在缓存中读取。 一级缓存自动开启,为sqlSession缓存。缓存的级别在sqlSession这个级别。
不同的sqlSession不能共用缓存。
二级缓存
缓存:缓存的是记录。
称为sqlSessionFactory级别的缓存,可以实现不同sqlSession之间的数据缓存。
开启二级缓存
实际上是要先开启全局的缓存(默认是开启的)“cacheEnabled”,再开启单个文件的。
在映射文件mapper里面加<cache>
缓存之间的关系
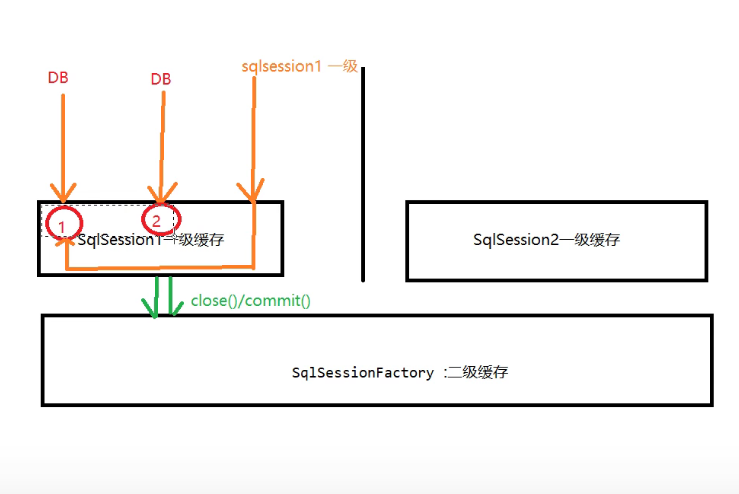
查询的时候,二级缓存-->一级缓存-->DB,其中数据查找到的先保存在一级缓存,当close()或者commit的时候一级缓存的内容移动到二级缓存中。
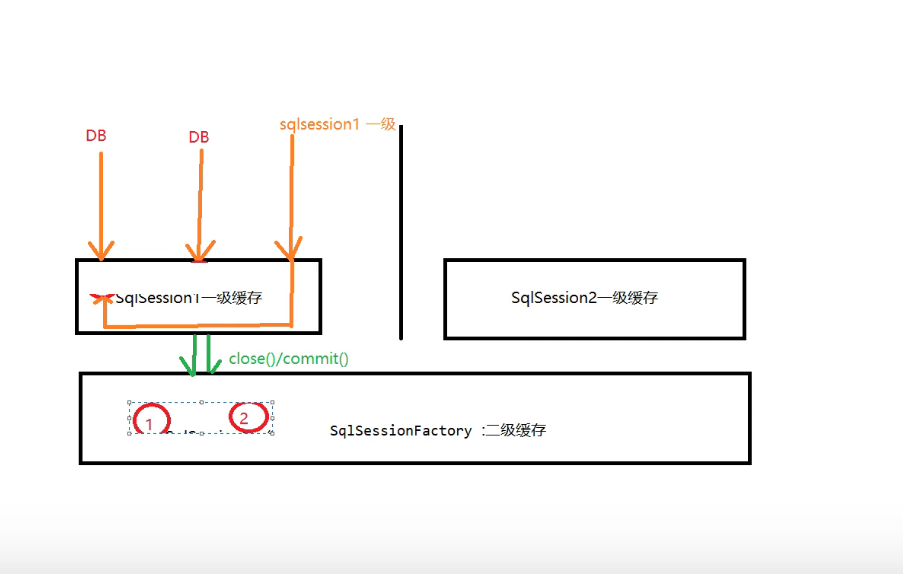

cache的细节
-
开启二级缓存
@CacheNamespace(blocking = true) -
type自定义缓存类,需要继承缓存类org.apache.ibatis.cache.Cache。
-
readOnly缓存内容只读。
-
缓存策略:什么时候缓存被清空,例如LRU,最近最少使用。
-
flushInterval刷新的间隔,毫秒为单位。添加删除修改会导致缓存中的数据消失,缓存清空。
-
关闭单个查询语句的缓存,通过语句的useCache标签。
注解代替
@Select
将语句设置到方法上面
注解一般只是用单表的增删改查和多条件查询。
@Update
@Delete
@Insert
@Result
源码解读
Mybatis.XML的解析
1.InputStream,
读取xml文件,变成文件输入流
2.设计模式
工厂设计模式,用工厂批量的生成对象。
build(inputStream)-->xmlConfigBuilder()进行解析--->解析根节点,获得节点对象,然后用反射去解析,获取配置类Configuration。--->然后用配置类去构造工厂。
3.openSession()
利用默认工厂类DefaultSqlSessionFactory创建openSession()。 -->创建一个DefaultSqlSession-->
4.getMapper
采用动态代理模式,也是一种设计模式
帮我们动态创建实现类。
从Configration中调用getMapper。
产生代理对象,帮我们产生实现类:(JDK动态代理)

MapperProxy:
- MapperMethod,里面有excute方法。
标签中定义的 insert update delete 都会调用调用sqlSession中对应的方法update()方法。
查询都是调用selectList()方法。
update()
插入空值
mybatis在插入数据的时候,如果是空值会报错,解决这个的方法是,在插入的变量后面交代清楚输入的sql类型。例如
@Insert("insert into tbl_user(id,email,username,password,imageId,personalInfo,createTime) values(#{id},#{email},#{username},#{password},#{imageId,jdbcType=VARCHAR},#{personalInfo,jdbcType=VARCHAR},#{createTime})")
void insert(User user);