森林------中国高校科研环境
找一棵树------压缩感知(CS,compressing sampling/sensing),主要包括信号的稀疏表示、编码测量和重构算法等三个方面.信号的稀疏表示就是将信号投影到正交变换基时,可以将其看作原始信号的一种简洁表达.这是压缩传感的先验条件.在编码测量中,必须满足约束等距性条件,最后, 运用重构算法重构原始信号.
找一树枝------稀疏表示Sparse Representation
找一片树叶---
CS的名称就要三种,
compressed sensing = to sense the compressed signal 对应于频域采样定理
compressive sensing = to sense the compressive signal 对应于时域采样定理
compressive sampling = to sample the compressive signal 对应于A/D转换器的实现。
正交变换基有许多,如果图像信号的话,常用的基是DCT基、正交小波基。正交小波基中在的CS文献中,常用的是Dauchies-4小波,这类小波变换,可在Rice大学的小波工具包中实现。关于具体表示形式,就是正变换为alpha = Psi * f, 反变换为f = Psi^(T)*alpha,正交矩阵的逆就是转置,这是常识。想要了解CS的基本原理,我建议您去看Baraniuk的综述文章《compressive sensing》,这是工程派CS的代表作。CS的名称就要三种,分别是compressed sensing、compressive sensing、compressive samping, 不要认为他们是同义词,他们各自有不同的观点。如果你要研究图像视频方面的CS应用,建议你看Fowler JE课题组的文章,这个课题组的文章非常实用,是入门级的文献,特别建议你们看他们2012年的综述文章。国内各个课题组不成组织,个人感觉靠点谱的,是燕山大学,练秋生组,不过太偏理论。我是赞同工程派CS观点的,主要偏图像视频方面的。
信号在某种表示方式下的稀疏性,是压缩感知应用的理论基础。经典的稀疏化的方法有离散余弦变换(DCT)、傅里叶变换(FFT)、离散小波变换(DWT)等。
目前常用的测量矩阵包括随机高斯矩阵、随机贝努利矩阵、部分正交矩阵、部分哈达玛矩阵等
建议看微软Yi Ma,以色列Elad,以及美国Baraniuk研究组
为什么说图像的低频是轮廓,高频是噪声和细节 https://blog.csdn.net/charlene_bo/article/details/70877999
图像的频率:灰度值变化剧烈程度的指标,是灰度在平面空间上的梯度。
(1)什么是低频?
低频就是颜色缓慢地变化,也就是灰度缓慢地变化,就代表着那是连续渐变的一块区域,这部分就是低频. 对于一幅图像来说,除去高频的就是低频了,也就是边缘以内的内容为低频,而边缘内的内容就是图像的大部分信息,即图像的大致概貌和轮廓,是图像的近似信息。
(2)什么是高频?
反过来, 高频就是频率变化快.图像中什么时候灰度变化快?就是相邻区域之间灰度相差很大,这就是变化得快.图像中,一个影像与背景的边缘部位,通常会有明显的差别,也就是说变化那条边线那里,灰度变化很快,也即是变化频率高的部位.因此,图像边缘的灰度值变化快,就对应着频率高,即高频显示图像边缘。图像的细节处也是属于灰度值急剧变化的区域,正是因为灰度值的急剧变化,才会出现细节。
另外噪声(即噪点)也是这样,在一个像素所在的位置,之所以是噪点,就是因为它与正常的点颜色不一样了,也就是说该像素点灰度值明显不一样了,也就是灰度有快速地变化了,所以是高频部分,因此有噪声在高频这么一说。
其实归根到底,是因为我们人眼识别物体就是这样的.假如你穿一个红衣服在红色背景布前拍照,你能很好地识别么?不能,因为衣服与背景融为一体了,没有变化,所以看不出来,除非有灯光从某角度照在人物身上,这样边缘处会出现高亮和阴影,这样我们就能看到一些轮廓线,这些线就是颜色(即灰度)很不一样的地方.
从稀疏表示到K-SVD,再到图像去噪 https://blog.csgrandeur.com/blogs/20170323-ksvd-and-denoising
稀疏表示
稀疏性的理解
最初稀疏性产生于信号处理领域,自然界信号低频居多,高频主要是噪声,图像处理中的频率域滤波是个典型例子。
假设有一个干净没有噪声的图像,经过传输,收到的是一个受到干扰有了噪声的图像,而噪声主要是高频分量,对图片做二维傅里叶变换,对低频的波形保持,高频的一刀切,还原回来的图像就平滑了许多,大部分高频噪声就去除了。这个假设的场景就是个“信号恢复”的过程。如果把所有的频率的波都看作一个个相互正交的向量,恢复数据就是给这些向量找到一组系数,它们一乘、一合并,得到原始信号,频率从大到小是有无穷多个的,而由于自然界信号的“稀疏性”,对于图像而言,就是指有用的频率主要是低频,那么对应高频的系数基本都是0了,低频部分也不见得全是非0,这一系列系数0很多,非0很少,就很“稀疏”。
稀疏表示的概念
稀疏表示的目的就是在给定的超完备字典中用尽可能少的原子来表示信号。
意义在于降维,可以是压缩,可以用于机器学习特征提取,还有很多我也不知道的事情。。。
原子:信号的基本构成成分,比如一个长为N的列向量。
字典:许多原子的排序集合,一个N*T的矩阵,如果T>N,则为过完备或冗余字典。
咦,线性代数又出现了,假设列向量两两线性无关,
N*N的矩阵的秩就是N了,再增加向量也不会增加额外的信息。
稀疏表示的一个场景
假设现在有了一个N*T的过完备字典 D(比如前面所述图像傅里叶变换的所有频率的波),一个要表示的对象y(要还原的图像),求一套系数x,使得y=Dx,这里y是一个已知的长为N的列向量,x是一个未知的长为T的列向量,解方程。
这是一个T个未知数,N个方程的方程组,T>N,所以是有无穷多解的,线性代数中这样的方程很熟悉了。

上面我就随便举了个N=5, T=8的例子,用来随便感受下。
这里可以引出一个名词,ill-posed problem(不适定问题),即有多个满足条件的解,无法判断哪个解更加合适,这是更“落地”的应用场景,inverse problem(逆问题),比如图像去噪,从噪声图中提取干净图。于是需要做一个约束。
增加限制条件,要求x尽可能稀疏,怎么“稀疏”呢?就是x的0尽可能多,即norm(x, 0)(零范数:非0元素个数)尽可能小。这样就有唯一解了吗?也还不是,如何能“约束”出各位合适的解,如何解,正是稀疏表示所研究的重点问题。比如后来有证明D满足一定条件情况下x满足norm(x,1)即可还原原始数据等,这有不少大神开启这个领域的故事这里就不讲了。
奥卡姆剃刀原理的思想:如果两个模型的解释力相同,选择较简洁的那个。稀疏表达就符合这一点。
针对这个例子我有个疑问,
x都比y还大了,这哪里压缩了。这个问题应该容易解答,例子里x是比y大,但是如果每个原子不是长度为N的列向量,而是个矩阵,或者更复杂的东西呢,x却依然只是一列系数。
求解
字典D已知,求y在过完备字典D上的稀疏表示x,被称作稀疏编码,模型是:
x = argminx norm(y − Dx, 2)2, s.t.norm(x, 1)≤ε
如何求解x?D又是怎么来的?先说D,D可以是前面说的傅里叶变换的一系列波啊,也可以是DCT的,也可以是小波的。但是科学家为了特定问题能有更具适应性的字典,让D也变成一个设计出来的量了,手工设计是不行,那么D也成了一个需要求的未知量。
已知D求x有OMP算法,大意是先找到D和y最接近的一个原子D(m),求出合适的系数x(m),新的y'=D(m) * x(m),再找下一个最接近的原子,直到找完合适的x,如何确定最接近,如何计算x(m),这里不再细说。
当任务是同时求出一个好的字典D,并得到一个满足稀疏约束的x,两步求解算法:先固定D,求个x出来,再固定x更新D,交替进行。
两步求解好熟悉的老套路。也许可以这么理解,求
x不再是个稀罕问题,而训练一个好的字典渐渐成为解决应用问题的关键,也是研究重点。
做这个求解的方法就有MOD、K-SVD等等一系列了。MOD分为两个步骤:Sparse Coding和Dictionary Update。
Sparse Coding:
x = argminx norm(y − Ax, 2)2, s.t.norm(x, 1)≤k
Dictinary Update:
D = argminx norm(y − Ax, 2)2
x的更新类似OMP,字典D的更新使用最小二乘法。
K-SVD
迭代K次,每次计算一下SVD分解的算法。SVD即奇异值,在了解SVD之前先复习一下矩阵的特征值。
特征值分解
特征值分解和奇异值分解是机器学习领域常见的方法。线性代数中我们熟悉的特征值 λ ,设 v是矩阵A的特征向量,则
Av = λvv是 λ 对应的特征向量。 矩阵的一组特征向量是相互正交的,特征值分解 将矩阵分解成如下形式:
A = QΣQ−1
其中Q是矩阵A的特征向量组成的矩阵, Σ 是一个对角阵,对角线上每个元素就是一个特征值,由大到小排列。
这像什么?Σ 里的一串 λ 就像前面
y=Dx里的x,而特征值矩阵Q就像字典D啊。特征向量的大小描述了每个特征值的权重,它们一起组合成了矩阵A,也就是那个y。
然而,特征值分解有个严重的局限——A必须是个方阵。
SVD(奇异值)分解
类比特征值分解,奇异值分解定义成这样:
A = UΣV′
假设A是一个N*M的矩阵,则U是N*N的方阵,Σ 是N*M的矩阵,V是M*M的方阵,于是奇异值分解就是求 Σ、U、V,V'是V的转置。于是套公式就可以求出奇异值、U、V,公式就不堆这里了。
SVD怎么和稀疏性搭边呢?因为奇异值矩阵 Σ (虽然不是方阵,但也是按45°角放着一串奇异值的类似对角阵的东西)的“对角线”上大部分数值是0或接近0的,类比特征值分解,这些奇异值就是“权重”嘛,如果把接近0的这些丢掉,是不是清(稀)爽(疏)很多?部分奇异值分解,A还是N*M,但假设取比较大的r个奇异值, Σ 变成r*r,部分SVD分解即:
AN × M ≈ UN × rΣr × rVr × M−1
如果r很小,而等式左右又能很接近,那数据就被压缩的相当不错,保存U、Σ 、V 要比保存A本身节省空间多了。
K-SVD字典学习
K-SVD和MOD最大的不同在于,每次只更新字典的一个原子(即D的一列),而不是每次用一个x更新整个D。
回忆下前面的y=Dx,但是学一个字典,当然不能只用一个数据,现在来升级版:
Y = DX
哈?小写变大写?意思是一组y和其对应的一组x,那么Y和X指的矩阵。
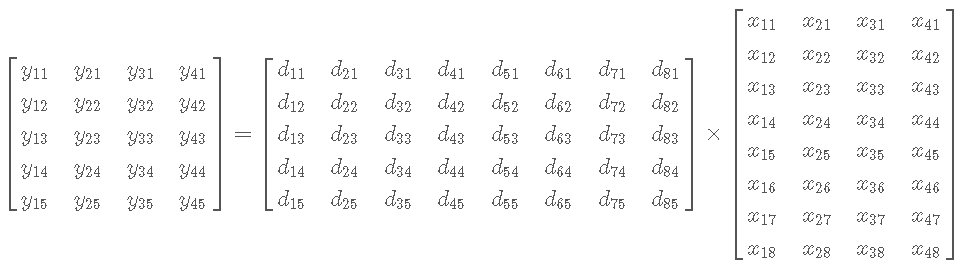
现在要更新字典D的第k个原子,也就是第k列,它能影响到的是Y的第k行,同样对应D的第k列的系数,也是X的第k行。
目标函数的转化:
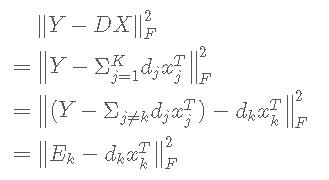
Ek 是去掉原子 dk 的 D 中的误差,于是目标函数转化为 D 的其他列固定,要更新的 dk 使全局误差( ∥Y−DX∥ )最小化。 即可得到字典的第k个原子。求解这里的 Dk, xkT ,就用到对 E 的SVD分解了。
但是直接分解 E 得到的 xkT 并不稀疏。
更新字典和稀疏系数是迭代进行的,在“本次”迭代中,找到“上次”迭代中哪些Y用到了字典D的原子k,也就是X的第k行哪些元素不为0,x1k, x2k, x3k, x4k 里,假设 x1k, x3k 不为0,那么对应的Y的1,3列就是用到了D的原子k的信号(Y的每列是一个信号)。现在把它们拆出来:

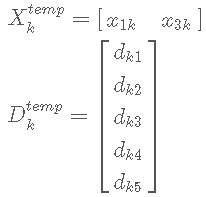
这样得到只保留非零位置的X、D计算目标函数后得到的只保留对应位置的 Ektemp ,对这个 Ektemp 再做SVD分解,Ektemp = UΣVT, U 的第一列即为新的 $widetilde{d}_{k}$, V 的第一列与 Σ(1, 1) 的乘积为新的 $widetilde{x}^{T}_{k}$ 。
逐列更新得到新字典 $widetilde{D}$ 。
K-SVD图像去噪
上面提到过稀疏表示基本的目标函数是:
x = argminx∥y−Dx∥22, s.t.∥x∥0 ≤ ε
这里暂时用0范数来说明。
假设现在有一个零均值高斯白噪声,即 n ∼ N(0, σ) , σ 是噪声的标准差,有噪声的图像为 z = y + n ,目的是从信号 z 中恢复出原始无噪信号 y,通过最大后验概率,求得目标函数的解,即可恢复出y:
x = argminx∥z−Dx∥22, s.t.∥x∥0 ≤ T
> 这里最大后验概率能恢复y是为什么暂时没管,肯定有证明了。。
其中T依赖于 ε 和 σ 。为方便优化计算,实际操作中往往转化成:
x = argminx∥z−Dx∥22 + μ∥x∥0
选取恰当的μ可以让上面两式等价。
优化属于NP难问题,有一系列研究,可通过OMP、BP、FOCUSS等算法来获得近似解。如果 x足够稀疏,近似解就足够接近精确解。