作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
本次作业是在期中大作业的基础上利用hadoop和hive技术进行大数据分析
1. 准备数据(下图为SCV截图):
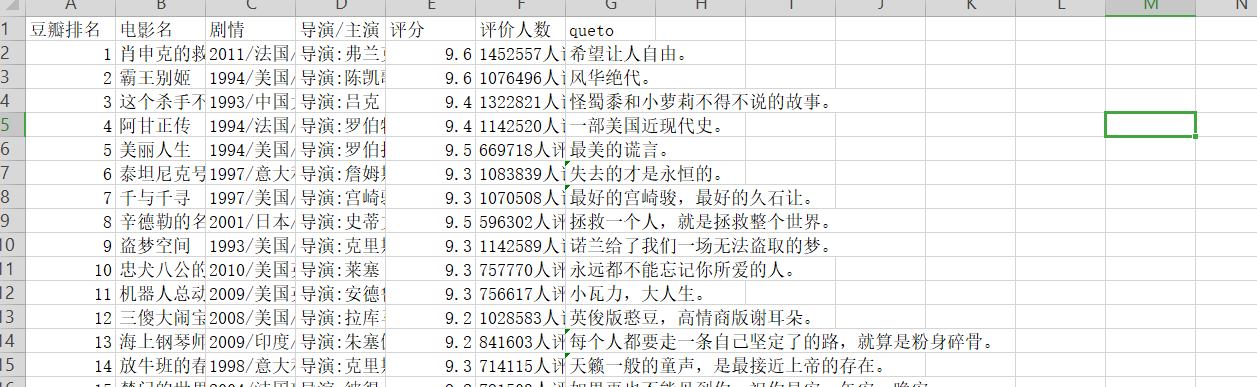
把CSV添加到/bigdatacase/dataset中

查看前十条数据看是否添加成功
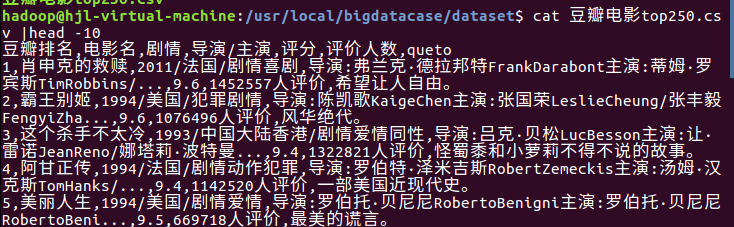
可以看到已经添加成功了
表格预处理:
删除第一行表头并查看是否删除成功:
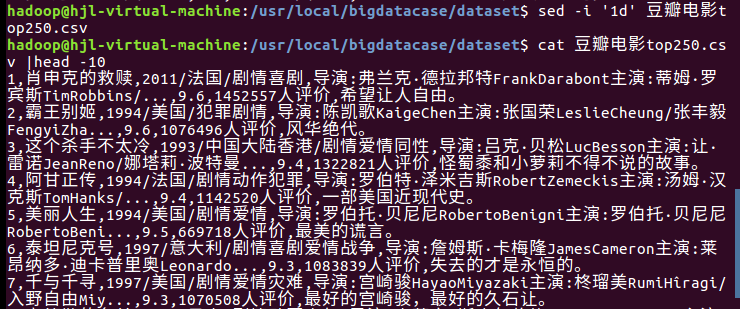
编辑pre_deal.sh以进行文件预处理:
#!/bin/bash
infile=$1
outfile=$2
awk -F "," 'BEGIN{
srand();
}
{
print " "$1" "$2" "$3" "$4" "$5" "$8" "$9" "
}' $infile > $outfile
查看是否与处理成功:
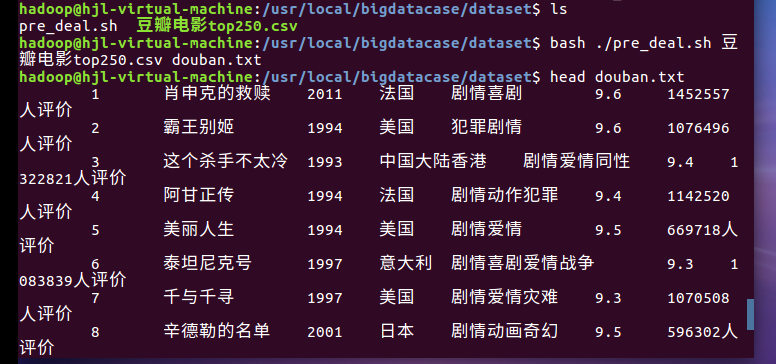
把文件上传到Hadoop上:

把hdfs中“/bigdatabase/dataset”目录下的数据加载到了数据仓库的hive中:

查看表的前十条数据:

数据分析:
根据期中大作业的分析可得:


美国的豆瓣TOP250还是占比最高;

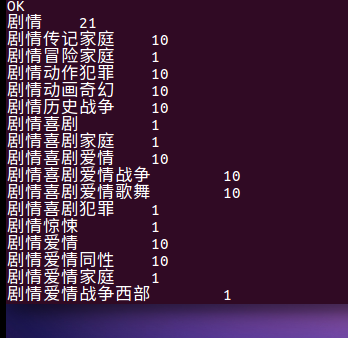
可以看出剧情类的电影在TOP250中的数量是最多的,也就是说比较多人偏向纯剧情类型的电影,还有20部电影是剧情音乐类型的,也是会有挺多人的喜欢看。
犯罪剧情奇幻悬疑,剧情爱情家庭,战争西部片,比较少好的电影,也比较少人看,也有部分的喜剧类电影比较少人看,比如犯罪类型和家庭类喜剧。

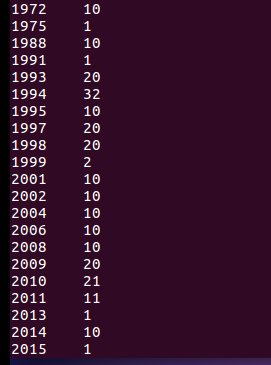
从上图也可以看出来在1994年的电影占豆瓣TOP250比较多的比例,一共32部电影入选。1975和1991年就比较少了,只有1部电影,13和15年亦是如此只有一部电影可以进入豆瓣TOP250。