原文参考 http://www.cnblogs.com/Anker/archive/2013/01/23/2873422.html
本章开始介绍了堆的基本概念,然后引入最大堆和最小堆的概念。全章采用最大堆来介绍堆的操作,两个重要的操作是调整最大堆和创建最大堆,接着着两个操作引进了堆排序,最后介绍了采用堆实现优先级队列。
1、堆
堆给人的感觉是一个二叉树,但是其本质是一种数组对象,因为对堆进行操作的时候将堆视为一颗完全二叉树,树中每个节点与数组中的存放该节点值的那个元素对应。所以堆又称为二叉堆,堆与完全二叉树的对应关系如下图所示:

通常给定节点i,可以根据其在数组中的位置求出该节点的父亲节点、左右孩子节点,这三个过程一般采用宏或者内联函数实现。书上介绍的时候,数组的下标是从1开始的,所有可到:PARENT(i)=i/2 LEFT(i) = 2*i RIGHT(i) = 2*i+1。
根据节点数值满足的条件,可以将分为最大堆和最小堆。最大堆的特性是:除了根节点以外的每个节点i,有A[PARENT(i)] >= A[i],最小堆的特性是:除了根节点以外的每个节点i,有A[PARENT(i)] <=A[i]。
2、保持堆的性质
堆的关键操作过程是如何保持堆的特有性质,给定一个节点i,要保证以i为根的子树满足堆性质。书中以最大堆作为例子进行讲解,并给出了递归形式的保持最大堆性的操作过程MAX-HEAPIFY。先从看一个例子,操作过程如下图所示:
从图中可以看出,在节点i=2时,不满足最大堆的要求,需要进行调整,选择节点2的左右孩子中最大一个进行交换,然后检查交换后的节点i=4是否满足最大堆的要求,从图看出不满足,接着进行调整,直到没有交换为止。书中给出了递归形式的伪代码:

我用C语言实现如下所示:
1 void max_heapify(int A[],int length,int i){ 2 int l,r,largest; 3 int temp; 4 l= LEFT(i); 5 r= RIGHT(i); 6 if(l<= length && A[l]>A[i]) 7 largest = l; 8 else largest = i; 9 10 if(r<= length && A[r]>A[largest]) 11 largest = r; 12 13 if (largest != i) { 14 temp = A[i]; 15 A[i] = A[largest]; 16 A[largest] = temp; 17 max_heapify(A,length,largest); 18 } 19 }
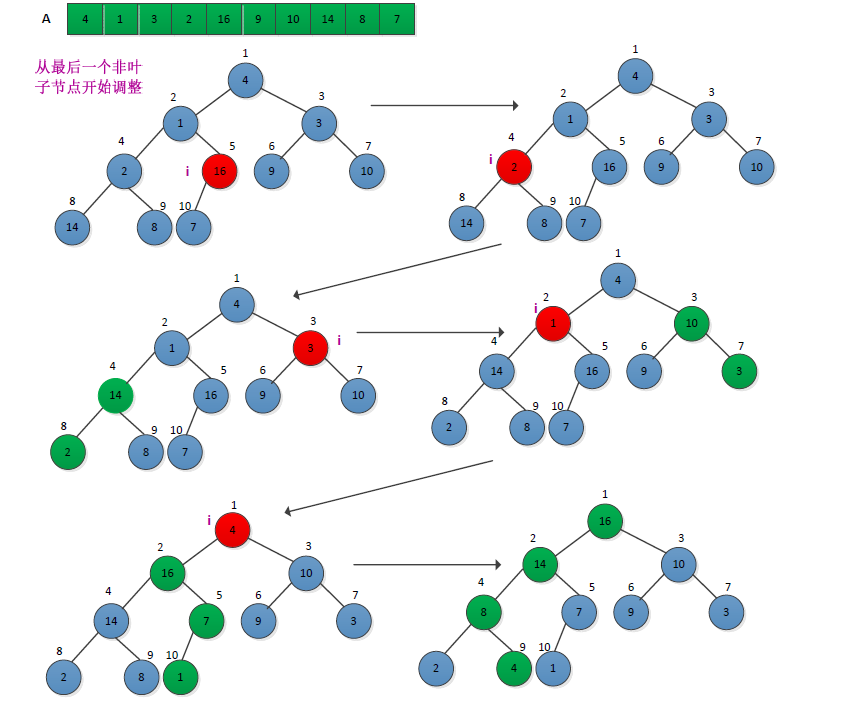
3、建堆
建立最大堆的过程是自底向上地调用最大堆调整程序将一个数组A[1.....N]变成一个最大堆。将数组视为一颗完全二叉树,从其最后一个非叶子节点(n/2)开始调整。调整过程如下图所示:
书中给出了创建堆的为代码,
我用C语言实现如下:
1 void build_max_heap(int a[],int length) { 2 int i; 3 for(i=length/2; i>0; i--) { 4 max_heapify(a,LEN,i); 5 } 6 }
4、堆排序算法
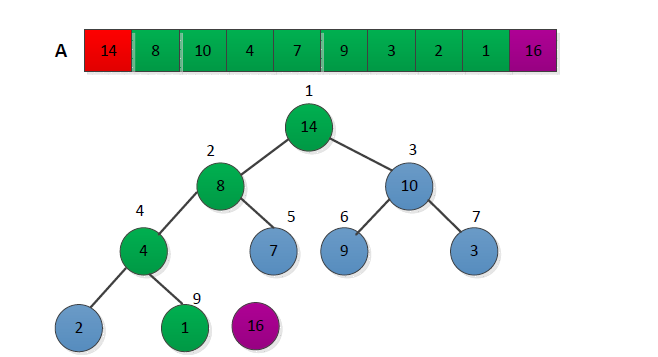
堆排序算法过程为:先调用创建堆函数将输入数组A[1...n]造成一个最大堆,使得最大的值存放在数组第一个位置A[1],然后用数组最后一个位置元素与第一个位置进行交换,并将堆的大小减少1,并调用最大堆调整函数从第一个位置调整最大堆。给出堆数组A={4,1,3,16,9,10,14,8,7}进行堆排序简单的过程如下:
(1)创建最大堆,数组第一个元素最大,执行后结果下图:

(2)进行循环,从length(a)到2,并不断的调整最大堆,给出一个简单过程如下:
书中给出了对排序为代码,

我用C语言实现如下所示:
1 void heap_sort(int A[],int length) { 2 int i; 3 int temp; 4 build_max_heap(A,length); 5 for(i=length; i>1; i--){ 6 temp = A[1]; 7 A[1] = A[i]; 8 A[i] = temp; 9 length--; 10 max_heapify(A,length,1); 11 } 12 }
结合上面的调整堆和创建堆 的过程,写个简单测试程序连续堆排序,程序如下所示:


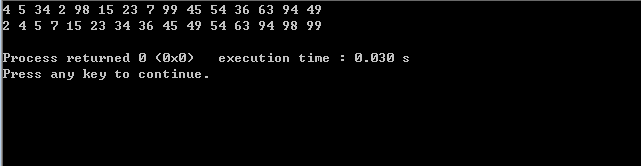
1 #include<stdio.h> 2 #define NOUSEDATA -65536 3 #define LEN 9 4 int LEFT(int i){ 5 return 2*i; 6 } 7 int RIGHT(int i){ 8 return 2*i+1; 9 } 10 void max_heapify(int A[],int length,int i){ 11 int l,r,largest; 12 int temp; 13 l= LEFT(i); 14 r= RIGHT(i); 15 if(l<= length && A[l]>A[i]) 16 largest = l; 17 else largest = i; 18 19 if(r<= length && A[r]>A[largest]) 20 largest = r; 21 22 if (largest != i) { 23 temp = A[i]; 24 A[i] = A[largest]; 25 A[largest] = temp; 26 max_heapify(A,length,largest); 27 } 28 } 29 void build_max_heap(int a[],int length) { 30 int i; 31 for(i=length/2; i>0; i--) { 32 max_heapify(a,LEN,i); 33 } 34 } 35 void heap_sort(int A[],int length) { 36 int i; 37 int temp; 38 build_max_heap(A,length); 39 for(i=length; i>1; i--){ 40 temp = A[1]; 41 A[1] = A[i]; 42 A[i] = temp;//因为是最大堆,A[1]就是最大值,所以A[i]始终保存最大值。 43 length--; 44 max_heapify(A,length,1); 45 } 46 } 47 48 int main(void) { 49 int i; 50 int A[LEN+1]={NOUSEDATA, 4, 5, 34, 2, 98, 15, 23, 7, 99}; 51 for(i=1;i<=9;i++ ) { 52 printf("%d ",A[i]); 53 } 54 printf(" "); 55 heap_sort(A,LEN); 56 for(i=1;i<=LEN;i++ ) { 57 printf("%d ",A[i]); 58 } 59 printf(" "); 60 return 0; 61 } 62 #if(0) 63 //非递归的方法 64 void max_heap(int A[],int length, int i){ 65 } 66 #endif
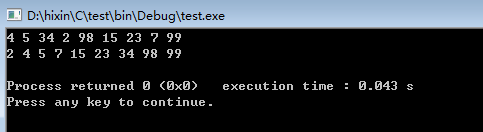
从结果可以看出按照最大堆进行堆排序最终使得结果是从小到大排序(非递减的)。
堆排序算法时间复杂度:调整堆过程满足递归式T(n)<=T(2n/3)+θ(1),有master定义可以知道T(n) = O(lgn),堆排序过程中执行一个循环,调用最大堆调整函数,总的时间复杂度为O(nlgn)。
5、问题
(1)课后习题要求给出其非递归的形式,我想了半天,才搞出来,领悟能力有限啊。非递归就要考虑要循环进行实现,需要考虑的是循环结束条件是什么。对一个给定的节点i,要对其进行调整使其满足最大堆的性质。总的思想是先找出节点i的左右孩子节点,然后从三者中找到最大的节点,如果找到的最大节点就是i,说明i节点满足堆的性质,此时循环就结束了。如果找到的最大节点不是节点i,那么这个时候就要将最大的节点(设为largest)与节点i进行交换,然后从largest节点开始循环进行调整,直到满足条件为止。给出非递归的调整堆程序如下:
1 #if(1) 2 //非递归的方法 3 void max_heap(int a[],int length, int i){ 4 int l,r,largest; 5 int temp; 6 l= LEFT(i); 7 r= RIGHT(i); 8 do{ 9 10 if(l<= length && a[i]<a[l]){ 11 largest = l; 12 } 13 else 14 largest = i; 15 if(r<= length && a[largest]< a[r]) { 16 largest = r; 17 } 18 19 if(largest != i) { 20 temp = a[i]; 21 a[i] = a[largest]; 22 a[largest] = temp; 23 i = largest; 24 l = LEFT(i); 25 r= RIGHT(i); 26 } 27 else { 28 break; 29 } 30 }while(largest <= length); 31 32 } 33 34 #endif
实则就是模拟了递归的过程,循环结束条件表面上为largest要小于结点个数,实则退出循环是因为break语句,因为l或者r都要比largest大,只要largest = i就认为该结点满足最大堆性质。采用do while结构是为了让largest能被初始化。
增加结点数,程序运行结果为:
(2)在创建最大堆的过程中,为什么从最后一个非叶子节点(n/2)开始到第一个非叶子(1)结束,而不是从第一个非叶子节点(1)到最后一个非叶子节点(n/2)结束呢?
我的想法是:如果是从第一个非叶子节点开始创建堆,有可能导致创建的堆不满足最大堆的性质,从第一个非叶子节点(1)到最后一个非叶子节点(n/2)创建,后面的结点在调整的过程中可能会破坏第一个结点创建好的最大堆结构。反过来就不一样,因为第
一个结点的递归次数最多,第一个结点放在最后调整,因为递归深度大,可以把之前打乱的给修复好。
如果是从第一个非叶子节点开始创建堆,有可能导致创建的堆不满足堆的性质,使得第一个元素不是最大的。这样做只是使得该节点的和其左右孩子节点满足堆性质,不能确保整个树满足堆的性质。如果最大的节点在叶子节点,那么将可能不会出现在根节点
中。例如下面的例子:

从图中可以看出,从第一个非叶子节点开始创建最大堆,最后得到的结果并不是最大堆。而从最后一个非叶子节点开始创建堆时候,能够保证该节点的子树都满足堆的性质,从而自底向上进行调整堆,最终使得满足最大堆的性质。