1. 利用loc、iloc提取行数据
import numpy as np import pandas as pd #创建一个Dataframe data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD')) In[1]: data Out[1]: A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 d 12 13 14 15 #取索引为'a'的行 In[2]: data.loc['a'] Out[2]: A 0 B 1 C 2 D 3 #取第一行数据,索引为'a'的行就是第一行,所以结果相同 In[3]: data.iloc[0] Out[3]: A 0 B 1 C 2 D 3
2. 利用loc、iloc提取指定行、指定列数据
In[6]:data.loc[['a','b'],['A','B']] #提取index为'a','b',列名为'A','B'中的数据 Out[6]: A B a 0 1 b 4 5 In[7]:data.iloc[[0,1],[0,1]] #提取第0、1行,第0、1列中的数据 Out[7]: A B a 0 1 b 4 5
3. 选择C列大于6的行
index_C_big_2 = data.loc[data['C']>6] print(index_C_big_2)
4.
利用loc函数的时候,当index相同时,会将相同的Index全部提取出来,优点是:如果index是人名,数据框为所有人的数据,那么我可以将某个人的多条数据提取出来分析;
缺点是:如果index不具有特定意义,而且重复,那么提取的数据需要进一步处理,可用.reset_index()函数重置index
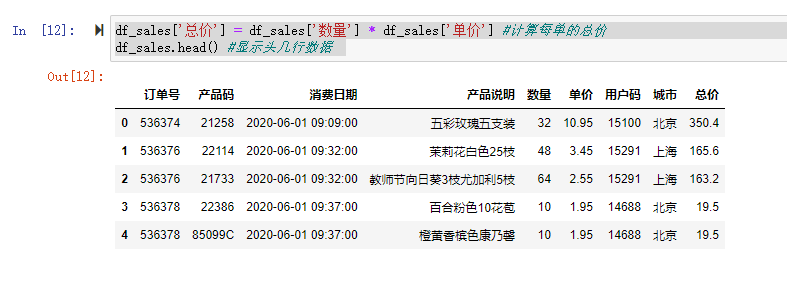
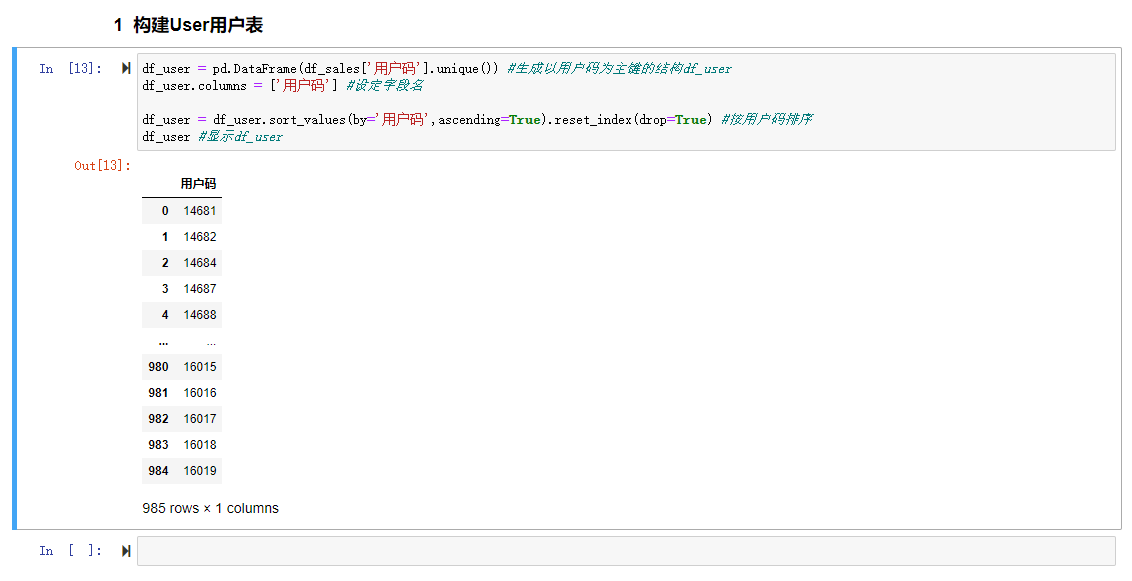
df_user = pd.DataFrame(df_sales['用户码'].unique()) #生成以用户码为主键的结构df_user df_user.columns = ['用户码'] #设定字段名 df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #按用户码排序 df_user #显示df_user
————————————————
原文链接:https://blog.csdn.net/W_weiying/article/details/81411257