2020年9月23日
方案构思
1,获取trace出发点和目的地
2,获取出发点和目的点对应的经纬度坐标添加到trace中
3,获取到对应的street_number
4,将stree_number添加到trace的路径中
5,筛选路径出发点和目的地相同的分类
读取数据
trace = []
with open('./taxi/trace/Taxi_105','r',encoding='utf8') as fp:
for line in fp:
trace.append(json.loads(line))
取出数据
for i in range(len(trace)):
print('i=',i)
print('出发地:', trace[i]['pointList'][0])
print('目的地:', trace[i]['pointList'][len(trace[i]['pointList'])-1])

# 点坐标信息
point = []
with open('./taxi/point/Taxi_105','r',encoding='utf8') as fp:
for line in fp:
point.append(json.loads(line))
print('-------------------------------')
# 取出需要数据
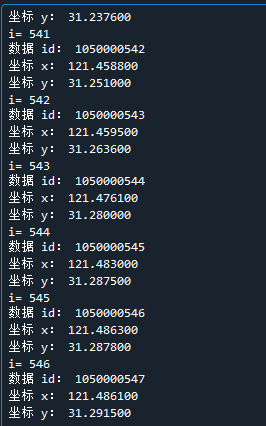
for i in range(len(point)):
print('i=',i)
print('数据 id:', point[i]['pointId'])
print('坐标 x:', point[i]['pointX'])
print('坐标 y:', point[i]['pointy'])
2020年9月24日
url请求变量参数
a= 31.225696563611
b= 121.49884033194
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={a},{b}'.format(a=a,b=b))
print(r.json())
print('street_number=',r.json()['result']['addressComponent']['street_number'])
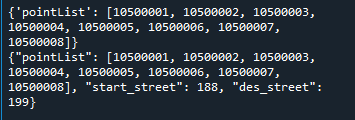
json数据的追加
embed = {'start_street':188,'des_street':199}
for i in embed:
trace[0][i]=embed[i]
jsObj = json.dumps(trace[0])
print(jsObj)
2020年9月25日
出现BUG
for j in range(len(trace)):
print('j=',j)
dep=trace[j]['pointList'][0]
des=trace[j]['pointList'][len(trace[j]['pointList'])-1]
for i in range(len(point)):
print('dep',type(dep))
print('id',type(point[i]['pointId']))
print('-----------------------------------')
if point[i]['pointId'] == dep:
print('666')
x = point[i]['pointX']
y = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
dep_street = r.json()['result']['addressComponent']['street_number']
print(dep_street)
for i in range(len(point)):
if point[i]['pointId'] == des:
x = point[i]['pointX']
y = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
des_street = r.json()['result']['addressComponent']['street_number']
找到问题

初步调试
import json
import requests
# 路线轨迹
trace = []
with open('./taxi/trace/Taxi_105','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
# 点坐标信息
point = []
with open('./taxi/point/Taxi_105','r',encoding='utf8') as fp2:
for line in fp2:
point.append(json.loads(line))
fp2.close
# ----------------------------------------------------------------
dep_street=0
des_street=2
for j in range(len(trace)):
print('j=',j)
dep=trace[j]['pointList'][0]
des=trace[j]['pointList'][len(trace[j]['pointList'])-1]
for i in range(len(point)):
if point[i]['pointId'] == str(dep):
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
dep_street = r.json()['result']['addressComponent']['street_number']
break
for i in range(len(point)):
if point[i]['pointId'] == des:
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
des_street = r.json()['result']['addressComponent']['street_number']
break
embed = {'dep_street':dep_street,'des_street':des_street}
for i in embed:
trace[j][i]=embed[i]
jsObj = json.dumps(trace[j])
print(jsObj)
整理调试
# -*- coding: utf-8 -*-
"""
1,获取trace出发点和目的地
2,获取出发点和目的点对应的经纬度坐标添加到trace中
3,获取到对应的street_number
4,将stree_number添加到trace的路径中
5,筛选路径出发点和目的地相同的分类
"""
import json
import requests
# 读取路线轨迹------------------------------------------------------------
trace = []
with open('./taxi/trace/Taxi_105','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
# 读取点坐标信息---------------------------------------------------------
point = []
with open('./taxi/point/Taxi_105','r',encoding='utf8') as fp2:
for line in fp2:
point.append(json.loads(line))
fp2.close
# 处理数据----------------------------------------------------------------
dep_street = -1
des_street = -1
carId = -1
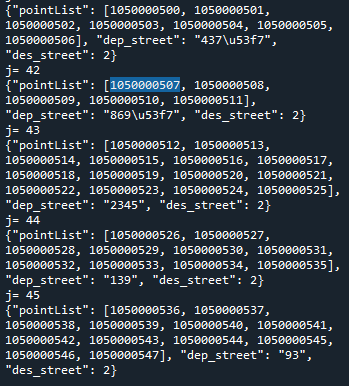
for j in range(len(trace)):
print('j=',j)
dep=trace[j]['pointList'][0]
des=trace[j]['pointList'][len(trace[j]['pointList'])-1]
for i in range(len(point)):
if point[i]['pointId'] == str(dep):
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
dep_street = r.json()['result']['addressComponent']['street_number']
break
for i in range(len(point)):
if point[i]['pointId'] == str(des):
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
des_street = r.json()['result']['addressComponent']['street_number']
break
embed = {'dep_street':dep_street,'des_street':des_street}
for i in embed:
trace[j][i]=embed[i]
jsObj = json.dumps(trace[j])
print(jsObj)
# 写入数据--------------------------------------------------------------------
with open("./test.txt",'wt') as fp3:
for i in trace:
print(i,file=fp3)
fp3.close
{'pointList': [10500001, 10500002, 10500003, 10500004, 10500005, 10500006, 10500007, 10500008], 'dep_street': '168号6楼', 'des_street': '6号楼103室'}
{'pointList': [10500009, 105000010, 105000011, 105000012, 105000013, 105000014, 105000015, 105000016, 105000017, 105000018, 105000019, 105000020, 105000021, 105000022], 'dep_street': '226号', 'des_street': '90-2'}
{'pointList': [105000027, 105000028, 105000029, 105000030, 105000031, 105000032, 105000033, 105000034, 105000035, 105000036], 'dep_street': '165号', 'des_street': '420号'}
{'pointList': [105000037, 105000038, 105000039, 105000040, 105000041, 105000042, 105000043, 105000044, 105000045, 105000046, 105000047, 105000048, 105000049, 105000050, 105000051], 'dep_street': '226', 'des_street': '1129弄98'}
{'pointList': [105000053, 105000054, 105000055, 105000056, 105000057, 105000058, 105000059, 105000060], 'dep_street': '20号', 'des_street': '44号'}
{'pointList': [105000065, 105000066, 105000067, 105000068, 105000069, 105000070, 105000071, 105000072, 105000073, 105000074, 105000075, 105000076, 105000077, 105000078, 105000079, 105000080], 'dep_street': '8号', 'des_street': '177号'}
.............
单文件处理完毕
import json
import requests
# 读取路线轨迹------------------------------------------------------------
trace = []
with open('./taxi/taxi/trace/Taxi_105','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
# 读取点坐标信息---------------------------------------------------------
point = []
with open('./taxi/taxi/point/Taxi_105','r',encoding='utf8') as fp2:
for line in fp2:
point.append(json.loads(line))
fp2.close
# 处理数据----------------------------------------------------------------
dep_street = -1
des_street = -1
carId = -1
for j in range(len(trace)):
print('j=',j)
dep=trace[j]['pointList'][0]
des=trace[j]['pointList'][len(trace[j]['pointList'])-1]
for i in range(len(point)):
if point[i]['pointId'] == str(dep):
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
dep_street = r.json()['result']['addressComponent']['street_number']
break
for i in range(len(point)):
if point[i]['pointId'] == str(des):
y = point[i]['pointX']
x = point[i]['pointy']
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
des_street = r.json()['result']['addressComponent']['street_number']
carId = point[i]['carId']
break
embed = {'dep_street':dep_street,'des_street':des_street,'carId':carId}
for i in embed:
trace[j][i]=embed[i]
jsObj = json.dumps(trace[j])
print(jsObj)
# 写入数据--------------------------------------------------------------------
with open("./test.txt",'wt') as fp3:
for i in trace:
print(i,file=fp3)
fp3.close
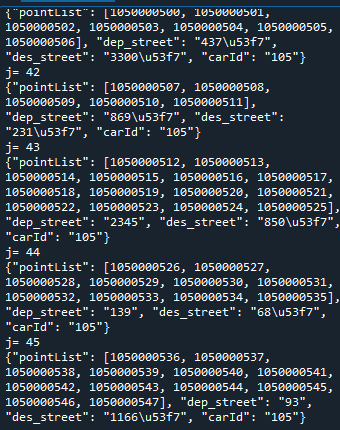
2020年9月26日
读取目录下的所有文件
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 25 20:06:24 2020
@author: jacksun
"""
import os
import json
path = "C:/Data/taxi/point" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
s = []
for file in files: #遍历文件夹
if not os.path.isdir(file): #判断是否是文件夹,不是文件夹才打开
f = open(path+"/"+file); #打开文件
iter_f = iter(f); #创建迭代器
str = ""
for line in iter_f: #遍历文件,一行行遍历,读取文本
line=line.rstrip("
")
str = str + line
s.append(str) #每个文件的文本存到list中
print(s) #打印结果
合并写入新文件
print('-------------------------------')
# 写入文件
with open("./point.txt",'wt') as fp3:
for i in s:
print(i,file=fp3)
fp3.close
遇到BUG
- 目前出现了一个BUG: ① 合并文件导致数据格式并不是很整齐
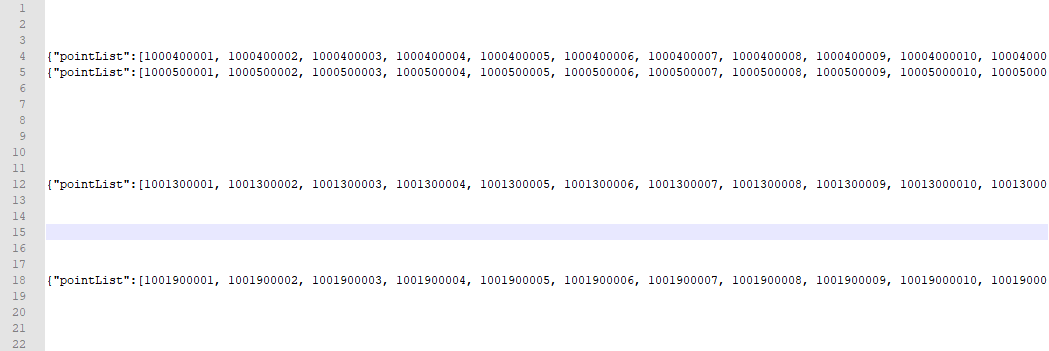
- 而且 ② 读取单个文件时,并没有按照
json格式一个一个读取 , 反而自己合并数据
- 但是对于少量的(两个)文件合并的时候是正常的 , 可能是文件太多(四千个文件)导致的

解决BUG
- 每次遍历一行就输入当文件 并且换行
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 25 20:06:24 2020
@author: jacksun
"""
import os
import json
import requests
path = "C:/Data/taxi/trace" # 文件夹目录
files = os.listdir(path) # 得到文件夹下的所有文件名称
s = []
for file in files: # 遍历文件夹
if not os.path.isdir(file): # 判断是否是文件夹,不是文件夹才打开
f = open(path + "/" + file); # 打开文件
iter_f = iter(f); # 创建迭代器
str = ""
i=0
for line in iter_f: # 遍历文件,一行行遍历,读取文本
line = line.rstrip("
")
with open("./trace_full.txt", 'a') as fp3:
fp3.write(line+"
")
fp3.close
print('-------------------------------ok')

2020年9月27日
对相同首尾的分类(单文件)
# -*- coding: utf-8 -*-
# 分类数据
import json
import pandas as pd
import requests
# 读取路线轨迹------------------------------------------------------------
trace = []
with open('./test.txt','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
df=pd.DataFrame(trace)
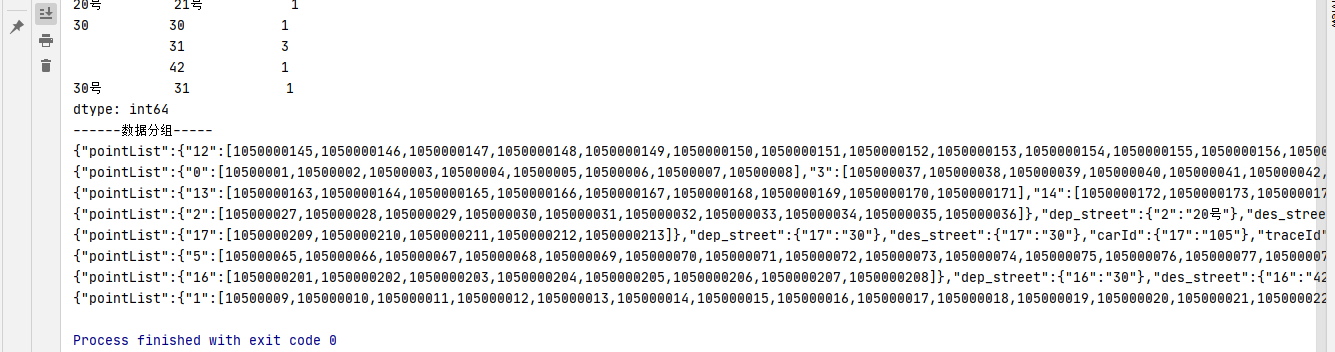
print("------数据分组统计个数-----")
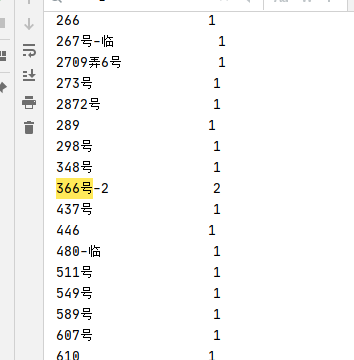
groupnum = df.groupby(['dep_street']).size()
print(groupnum)
#打印每组数据 这个很有用
print("------数据分组-----")
for groupname,grouplist in df.groupby('dep_street'):
print(groupname)
print(grouplist)
# print(df.set_index(['dep_street','traceId']))
总结
目前数据清洗进入了尾声,现在让我们进行复盘
-
获取trace出发点和目的地
-
获取出发点和目的点对应的经纬度坐标添加到trace中,再根据经纬度通过百度
api获得街道 -
然后在加入一个字段
traceId用于分类的时候用字典或者hashmap储存路径 ,将stree_number添加到trace的路径中 -
再将处理的文件保存下来,用于后面的分类
# -*- coding: utf-8 -*-
import json
import pandas
import requests
# 路线轨迹
trace = []
with open('./taxi/taxi/trace/Taxi_105','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
# 点坐标信息
point = []
with open('./taxi/taxi/point/Taxi_105','r',encoding='utf8') as fp2:
for line in fp2:
point.append(json.loads(line))
fp2.close
# 单个文件处理
# 处理数据----------------------------------------------------------------
dep_street = -1
des_street = -1
traceId = -1
carId = -1
for j in range(len(trace)):
print('j=',j)
dep=trace[j]["pointList"][0]
des=trace[j]["pointList"][len(trace[j]["pointList"])-1]
for i in range(len(point)):
if point[i]["pointId"] == str(dep):
y = point[i]["pointX"]
x = point[i]["pointy"]
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
dep_street = r.json()['result']['addressComponent']['street_number']
break
for i in range(len(point)):
if point[i]["pointId"] == str(des):
y = point[i]["pointX"]
x = point[i]["pointy"]
r = requests.get('http://api.map.baidu.com/reverse_geocoding/v3/?ak=ggWQp8TQXm39eaDlW6OBkO3HBnvbYHUT&output=json&coordtype=wgs84ll&location={x},{y}'.format(x=x,y=y))
des_street = r.json()['result']['addressComponent']['street_number']
carId = point[i]["carId"]
traceId+=1
break
embed = {"dep_street":dep_street,"des_street":des_street,"carId":carId,"traceId":traceId}
for i in embed:
trace[j][i]=embed[i]
jsObj = json.dumps(trace[j])
with open("./test.txt",'a',encoding='utf-8') as fp3:
fp3.write(jsObj+'
')
fp3.close
print(jsObj)
- 当然上面的只是单个文件,在处理文件之前,我们需要将两个文件
trace和point文件夹的所有文件分别合并成
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 25 20:06:24 2020
@author: jacksun
"""
import os
import json
import requests
path = "C:/Data/taxi/trace" # 文件夹目录
files = os.listdir(path) # 得到文件夹下的所有文件名称
s = []
for file in files: # 遍历文件夹
if not os.path.isdir(file): # 判断是否是文件夹,不是文件夹才打开
f = open(path + "/" + file); # 打开文件
iter_f = iter(f); # 创建迭代器
str = ""
i=0
for line in iter_f: # 遍历文件,一行行遍历,读取文本
line = line.rstrip("
")
with open("./trace_full.txt", 'a') as fp3:
fp3.write(line+"
")
fp3.close
print('-------------------------------ok')
- 筛选路径出发点和目的地相同的分类
# -*- coding: utf-8 -*-
# 分类数据
import json
import pandas as pd
import requests
# 读取路线轨迹------------------------------------------------------------
trace = []
with open('./test.txt','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
df=pd.DataFrame(trace)
print("------数据分组统计个数-----")
groupnum = df.groupby(['dep_street']).size()
print(groupnum)
#打印每组数据 这个很有用
print("------数据分组-----")
for groupname,grouplist in df.groupby('dep_street'):
print(groupname)
print(grouplist)
- 最后就是将数据整理保存下来
# -*- coding: utf-8 -*-
# 分类数据
import json
import pandas as pd
import requests
# 读取路线轨迹------------------------------------------------------------
trace = []
with open('./test.txt','r',encoding='utf8') as fp1:
for line in fp1:
trace.append(json.loads(line))
fp1.close
df=pd.DataFrame(trace)
print("------数据分组统计个数-----")
groupnum = df.groupby(['dep_street','des_street']).size()
print(groupnum)
#打印每组数据 这个很有用
print("------数据分组-----")
for groupname,grouplist in df.groupby(['dep_street','des_street']):
print(grouplist.to_json(force_ascii=False))