数组和链表的区别,请详细解释。
从逻辑结构来看:
a) 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费;数组可以根据下标直接存取。
b) 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项,非常繁琐)链表必须根据next指针找到下一个元素
从内存存储来看:
a) (静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小
b) 链表从堆中分配空间, 自由度大但是申请管理比较麻烦
从上面的比较可以看出,如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;相反, 如果需要经常插入和删除元素就需要用链表数据结构了。
| 顺序存储结构 | 链表存储结构 |
|---|---|
| 读取方便 O(1) | 读取不方便 需要遍历 O(n) |
| 插入删除 需要移动大量元素 | 插入删除方便 只需要改变指针 |
| 空间分配 :一次性 | 在需要时分配 |
| 存储密度 = 1 | 存储密度 < 1 |
| 数组 | 链表 |
|---|---|
| 事先定义长度,不能适应数据动态地增减 | 动态地进行存储分配,可以适应数据动态地增减 |
| 从栈中分配空间 | 从堆中分配空间 |
| 快速访问数据元素,插入删除不方便 | 查找访问数据不方便,插入删除数据发 |
| 头指针 | 头结点 |
|---|---|
| 是链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针 | 头结点是为了操作的统一和方便而设立的,放在第一元素的结点之前。 |
| 是必需的 | 不是必需的 为了方便操作 |
| 具有标识作用 | 对于插入和删除第一结点,和其他结点操作统一 |
树
二叉树的特点:
1、每个结点最多有两颗子树,结点的度最大为2。
2、左子树和右子树是有顺序的,次序不能颠倒。
3、即使某结点只有一个子树,也要区分左右子树。
4、二叉树可以是空树、只有一个根结点、根结点只有左子树、根结点只有右子树、根结点左右子树都有。
二叉排序树:
是比根结点大的放在右子树,比根结点小的放在左子树
二叉平衡树:
在二叉排序树的基础上,只要保证每个节点左子树和右子树的高度差小于等于1就可以了。
适用于插入删除比较少,但是查找比较多的情况
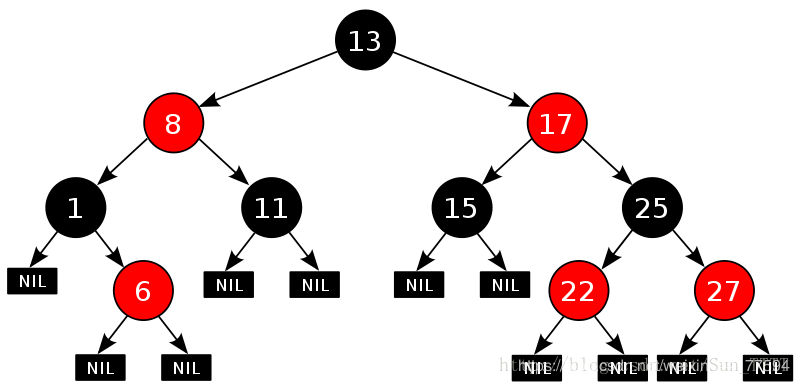
节点是红色或者黑色,没有其他的颜色 根结点是黑色,不能为红。 每个叶节点是黑色,这里的叶子结 节点是指空的叶子结点 不存在两个连续的红色节点,即父节点和子节点不能是连续的红色 从任一节点到其每个叶节点的所有路径都包含相同数目的黑色节点。
优点:平均查找,添加输出效果都还不错
红黑树的应用比较广泛,主要是用它来存储有序的数据,它的时间复杂度是O(lgn),效率非常之高。
例如,Java集合中的TreeSet和TreeMap,C++ STL中的set、map,需要使用动态规则的防火墙系统,使用红黑树而不是散列表被实践证明具有更好的伸缩性。Linux内核在管理vm_area_struct(虚拟内存)时就是采用了红黑树来维护内存块的。
B树和B+树的区别,以一个m阶数为例
关键词的数量不同:
B+树中具有n个关键字的结点只含有n棵子树。每个结点关键字个数的范围是|m/2| <= n <= m
B树中具有n个关键字的结点含有n+1棵子树。每个结点关键字个数的范围是|m/2| -1<= n <= m-1
存储的位置不同:B+树中数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中。
分支结点的结构不同:B+树的分支结点仅仅存储着关键字信息和儿子的指针,也就是说内部结点仅仅包含着索引信息
查询不同:B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束。
图
普利姆算法(Prim)
将v0到其他顶点的所有边当做候选边
重复以下过程,直到所有的顶点被并入树中
1.从候选边中挑选出最小的边输出,并将于该边的另一端顶点并入树中
2.考查所有剩余的顶点,选取与这棵树相接的边最短的边
克鲁斯卡尔算法
将图中边按照权值从小到大排序,
然后从最小边开始扫描,
并检测当前边是否为候选边,即是否该边并入会构成回路
排序
述快速排序过程
1)选择一个基准元素,通常选择第一个元素或者最后一个元素,
2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
KMP算法:
在一个字符串中查找是否包含目标的匹配字符串。其主要思想是每趟比较过程让子串先后滑动一个合适的位置。当发生不匹配的情况时,不是右移一位,而是移动(当前匹配的长度– 当前匹配子串的部分匹配值)位。
怎么理解哈希表,哈希表是什么
摘自百度:散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数
建立方法
直接定址法:
H(Key)=a*Key+b
特点:计算简单,且不会产生冲突,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
数字分析法:
适用于关键字位数比较多且标红可能的关键字都是已知的情况
平方取中法:
取关键字平方后的中间几位作为Hash地址
适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数
除留余数法:
解决哈希冲突的方法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
1) 线性探测法
2) 平方探测法
3) 伪随机序列法
4) 拉链法
贪心算法和动态规划区别?
贪心算法顾名思义就是做出在当前看来是最好的结果,它不从整体上加以考虑,也就是局部最优解。贪心算法从上往下,从顶部一步一步最优,的到最后的结果,它不能保证全局最优解,与贪心策略的选择有关。
动态规划是把问题分解成子问题,这些子问题可能有重复,可以记录下前面子问题的结果防止重复计算。动态规划解决子问题,前一个子问题的解对后一个子问题产生一定的影响。在求解子问题的过程中保留哪些有可能得到最优的局部解,丢弃其他局部解,直到解决最后一个问题时也就是初始问题的解。动态规划是从下到上,一步一步找到全局最优解。