10:Hbase优化方案
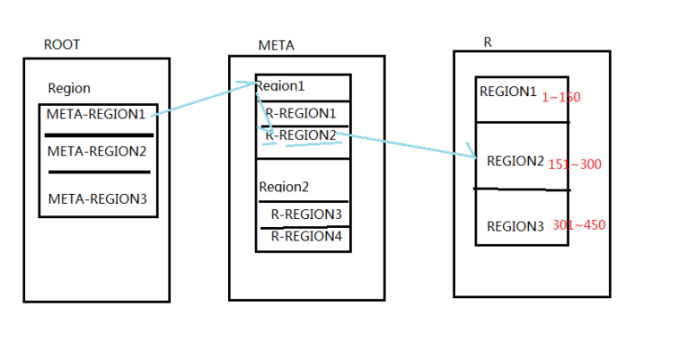
1)预分区设计
真正存储数据的是region要维护一个区间段的rowkey
startRow~endRowkey
-》手动设置预分区
create 'user_p','info','partition',SPLITS => ['101','102','103','104']
存在-∞ +∞
第一个分区 -∞ ~ 101
第二个分区 101~102
第三个分区 102~103
第四个分区 103~104
第五个分区 104 ~ +∞

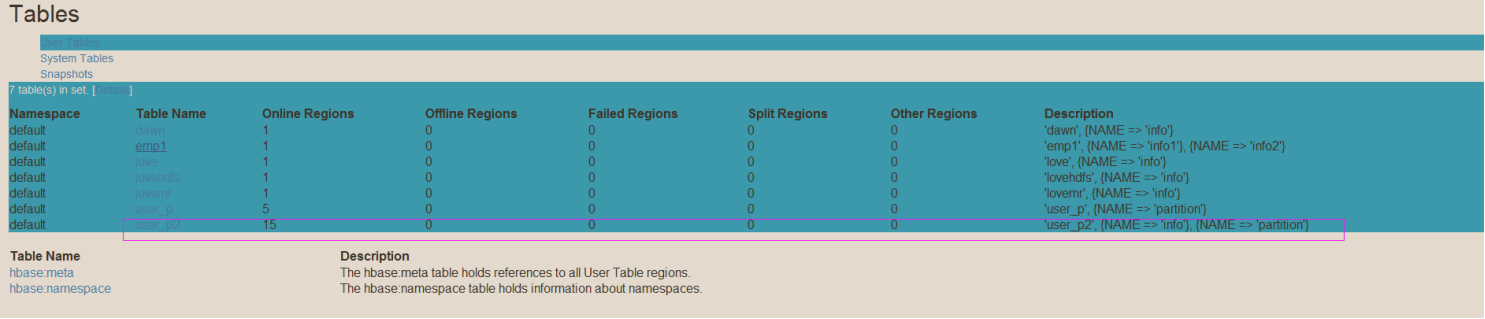
-》生成16进制序列预分区 (15个分区)
create 'user_p2','info','partition',{NUMREGIONS => 15,SPLITALGO => 'HexSt
ringSplit'}

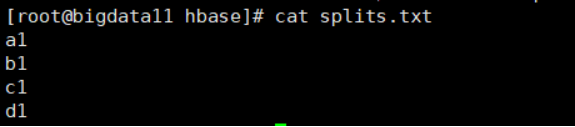
-》按照文件中设置的规则设置预分区(注意,文件是在hbase目录下的)
create 'user_p4','partition',SPLITS_FILE => 'splits.txt'

2)rowkey设计
一条数据的唯一标识是rowkey,此rowkey存储在哪个分区取决于
属于哪个预分区内。
为什么要设计rowkey?数据倾斜
为了防止出现数据倾斜
(1)生成随机数/hash/散列值
例如:rowkey是101 变成:dd21231dqwdqd123131d112131
102 变成:wqdqdq212131dqdwqwdqdw1d21
(2)字符串反转
2018120800011 1100080218102
2018120800012 2100080218102
(3)字符串拼接
2018120800011_a12e
2018120800012_odd12c
101~105 105~100000
总结:尽可能的使每个rowkey随机分布在各个region中
3)hbase优化
(1)内存优化
一般分配70%内存给Hbase的java堆
不建议分配非常大的堆内存
一般设置为 16~48G内存即可
设置:export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
注意:etc/hadoop下 hadoop-env.sh
(2)基础优化
-》优化DataNode
最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
默认值:4096 设置大于4096
-》优化延迟高的数据操作等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
默认:60000毫秒
调大
-》数据写入效率
压缩
属性:mapreduce.map.output.compress
值:org.apache.hadoop.io.compress.GzipCodec
-》优化Hstore的文件大小
属性:hbase.hregion.max.filesize
默认值:10GB
调小
我们已经学了的知识:
linux/hdfs/mr/zookeeper/hive/flume/sqoop/azkaban/hbase 坚持!!!!