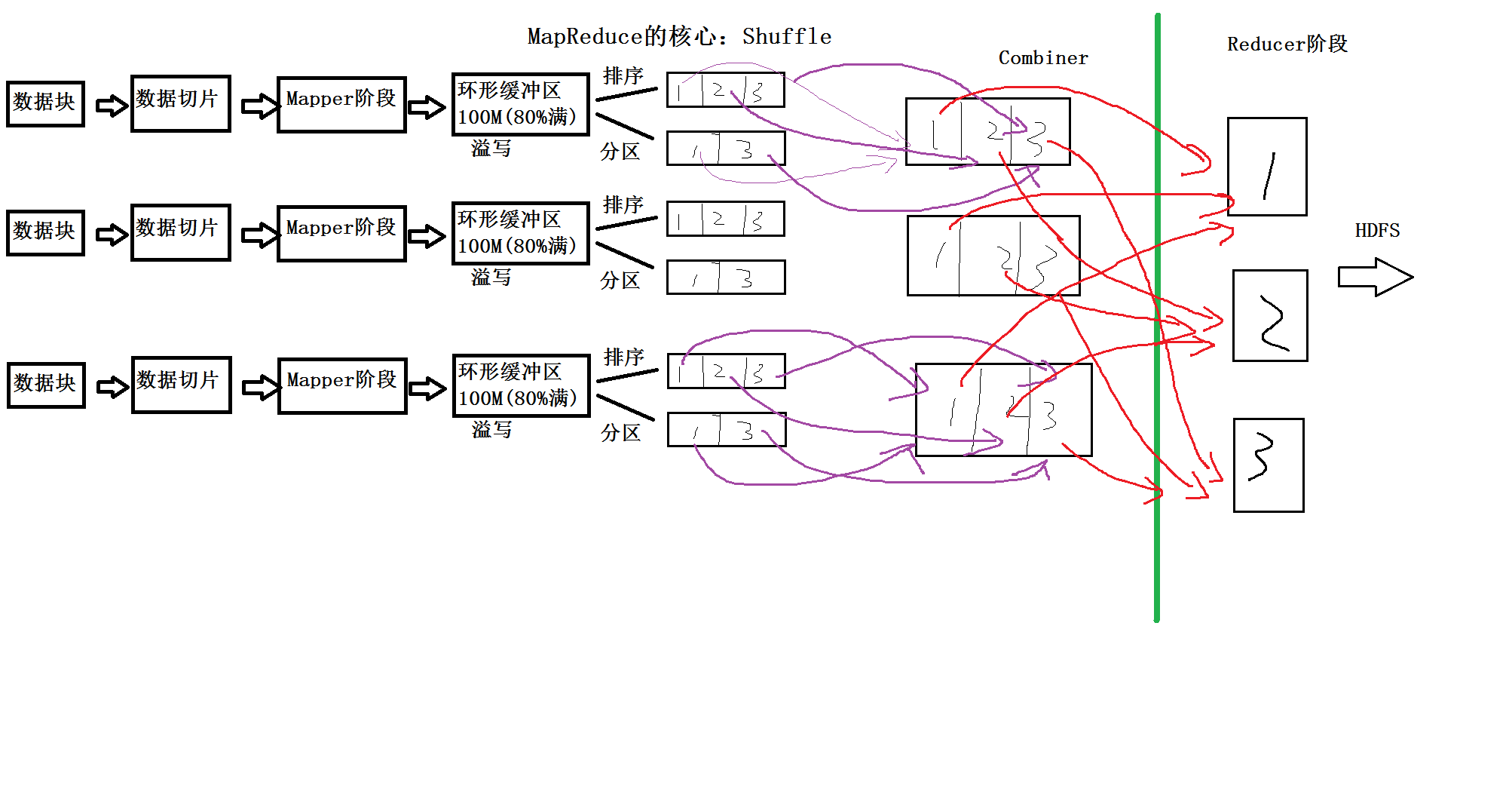
先来个原理图压压惊:
温馨提示:如果看不清这个图,可以下载下来,在自己电脑上可以放大。
或者直接放大浏览器。快捷键Ctrl+鼠标滑轮上即可放大。想恢复原来浏览器的默认大小,快键键:Ctrl+数字0

一:概述shuffle
Shuffle是mapreduce的核心,链接map与reduce的中间过程。
Mapp负责过滤分发,而reduce则是归并整理,从mapp输出到reduce的输入的这个过程称为shuffle过程。
二:map端的shuffle
1.map结果的输出
map的处理结果首先存放在一个环形的缓冲区。
这个缓冲区的内存是100M,是map存放结果的地方。如果数据量较大,超过了一定的量(默认80M),将会发生溢写过程。
在mapred-site.xml中设置内存的大小
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
在mapred-site.xml中设置内存溢写的阈值
<property>
<name>mapreduce.task.io.sort.spill.percent</name>
<value>0.8</value>
</property>
2.溢写过程
溢写是系统在后台单独开一个线程去操办。
溢写过程包括:分区partion,排序sort,溢写spill to disk,合并merge。
3.分区
分区分的是80%的内存。
因为reduce可能有不同的任务,所以会对80M的内存进行分区,将map的输出结果放入的对应的reduce分区中。
4.排序
默认是按照key排序。
当分区完成之后,对每一个分区的数据进行排序。
5.溢写
排序之后,将内存的数据写入硬盘。留出内存方便map的新的输出结果。
6.合并
如果是第一次写入硬盘则不需要考虑合并问题,但是在大数据的情况下,前面已经存在大量的spill文件的时候,这时候需要将它们进行合并。
将各个分区合并之后,对每一个分区的数据再进行一次排序
使用归并的方式进行合并,归并算法。
实现compara,进行比较。
形成一个文件。
三:reduce端的shuffle
1.步骤
对于reduce端的shuffle,大致分为复制,合并。
2.复制
当reduce开启任务后,不断的在各个节点复制需要的数据。
3.合并(内含排序)
复制数据的时候,把可以存放进内存的就把数据存放在内存中,当达到一定的时候,启动merge,将数据写进硬盘。
如果map数据大于内存需要存放的限制,直接写入硬盘,当达到一定的数量后将其合并为一个文件。
这时候,reduce开启任务需要的数据在内存中和在硬盘中,最终形成一个全局文件。
4.分组
《hadoop,1》
《hadoop,1》
《yarn,1》
《hadoop,1》
《hdfs,1》
《yarn,1》
将相同的key放在一起,使用comparable完成比较。
结果为:
《hadoop,list(1,1,1)》
《yarn,list(1,1)》
《hdfs,list(1)》
再来个简易版的洗牌图吧!!!以便理解