一:单词计数
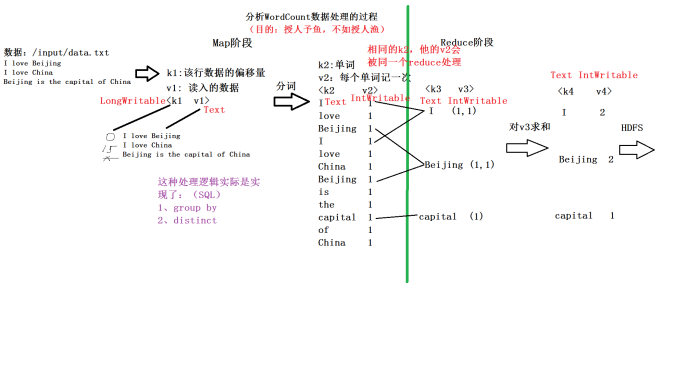
1:单词计数总流程图
2:代码实现
1:Map阶段
package it.dawn.YARNPra.wc_hdfs;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author Dawn
* @date 2019年5月1日23:09:08
* @version 1.0
*
* 思路?
* wordcount单词计数(数据来源hdfs上)
* <单词,1>
*
* 数据传输
*
* KEYIN:数据的起始偏移量0~10 11~20 21~30
* VALUEIN:数据
*
* KEYOUT:mapper输出到reduce阶段 k的类型
* VALUEOUT:mapper输出到reduce阶段v的类型
* <hello,1><hunter,1><henshuai,1>
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//key 起始偏移量 value 数据 context 上下文
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1.读取数据
String line=value.toString();
//2.切割 hello hunter
String[] words=line.split(" ");
//3.循环的写到下一个阶段<hello,1><hunter,1>
for(String word: words) {
//4.输出到reducer阶段
context.write(new Text(word), new IntWritable(1));
}
}
}
2:Reduce阶段
package it.dawn.YARNPra.wc_hdfs;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author Dawn
* @date 2019年5月1日23:15:33
* @version 1.0
*
* 汇总 <hello,4> <hunter,1> <henshuai,2>
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,
Context context) throws IOException, InterruptedException {
//1.统计单词出现的次数
int sum=0;
//2 累加求和
for(IntWritable v :v3) {
//拿到累加值
sum+=v.get();
}
//3 输出结果
context.write(k3, new IntWritable(sum));
}
}
3:Driver阶段
package it.dawn.YARNPra.wc_hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import it.dawn.YARNPra.wc_hdfs.WordCountMapper;
import it.dawn.YARNPra.wc_hdfs.WordCountReducer;
/**
* @author Dawn
* @date 2019年5月2日14:28:27
* @version 1.0
* 输入和输出路径都是hdfs上的路径
*/
public class WordCountDriver_hdfs {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job信息
Configuration conf=new Configuration();
Job job=Job.getInstance();
//2.获取jar包
job.setJarByClass(WordCountDriver_hdfs.class);
//3.获取自定义的mapper与reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4.设置map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置reduce输出的数据类型(最终的数据类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入存在的路径与处理后的结果路径(注意包的导入 是org.apache.hadoop.mapreduce.lib.下的包)
FileInputFormat.setInputPaths(job, new Path("/dawn/wordcount.txt"));
FileOutputFormat.setOutputPath(job, new Path("/output/wc"));
//7.提交任务
boolean rs=job.waitForCompletion(true);
System.out.println(rs?0:1);
}
}
4:打包程序提交到集群上运行
命令 (如果jar包没在当前目录下,记得写好路径):
hadoop jar wordcount.jar it.dawn.YARNPra.wc_hdfs.WordCountDriver_hdfs
总结:
用户编写mr程序主要分为三个部分:Mapper,Reducer,Driver
1.Mapper阶段
(1)用户自定义mapper类 要继承父类Mapper
(2)Mapper的输入数据的kv对形式(kv类型可以自定义)
(3)Mapper的map方法的重写(加入业务逻辑)
(4)Mapper的数据输出kv对的形式(kv类型可以自定义)
(5)map()方法(maptask进程)对每个<k,v>调用一次
2.Reducer阶段
(1)用户自定义reducer类 要继承父类Reducer
(2)Reducer的数据输入类型对应的是Mapper阶段的输出数据类型,也是kv对
(3)Reducer的reduce方法的重写(加入业务逻辑)
(4)ReduceTask进程对每组的k的<k,v>组调用一次reduce方法
3.Driver阶段
MR程序需要一个Driver来进行任务的提交,提交的任务是一个描述了各种重要信息的job对象
=============================================================================
补充: 如果在集群上运行 ,修改配置文件 mapred-site.xml
指定MR程序运行容器或者框架 默认是本地模式
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
修改如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
分发到bigdata13 bigdata12
scp mapred-site.xml bigdata12:$PWD
scp mapred-site.xml bigdata13:$PWD