hdfs的设计前提和目标:
1.认为硬件错误是常态而不是异常
2.流式数据访问,注重批处理和高吞吐量,而不是低延迟
3.大规模数据集
4.一次写入多次读取的文件访问模式
5.移动计算比移动数据更加划算
6.异构软硬件平台间的可移植性

namenode:
作用
1.存储文件和目录的元数据(元数据放在内存中):包含文件的block的副本个数,修改和访问的时间,访问权限,block大小以及block列表信息。
2.以两种方法在namenode本地进行持久化
命名空间镜像文件(fsimage)和编辑日志(edits log)
3.fsimage文件不记录每个block所在的datanode信息,这些信息会在每次系统启动的时候从datanode重建,之后datanode会周期性的通过心跳机制向namenode报告block信息。
datanode向namenode注册的时候发送的block列表信息:
-
-
- 1、文件名称和路径
- 2、文件的大小
- 3、文件的所属关系
- 4、文件的block块大小 128MB
- 5、文件的副本个数 3 MR 10个副本
- 6、文件的修改时间
- 7、文件的访问时间
- 8、文件的权限
- 9、文件的block列表
-
blk1:0,134217728,node1,node13,node26:blockID
blk2:134217728,134217728,node7,node89,node1002
blk2:134217728*2,134217728,node7,node89,node1002
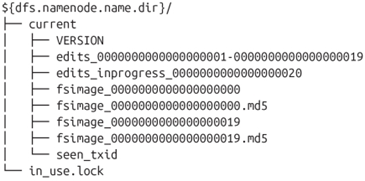
该目录结构在第一次格式化的时候创建
in_use.lock文件用于NameNode锁定存储目录,这样就防止其他同时运行的NameNode实例使用相同的存储目录
edits表示edits log日志文件,在namenode启动后,对文件系统的改动序列
fsimage:表示文件系统元数据镜像文件,启动时对整个文件系统的快照
NameNode在checkpoint之前首先要切换新的edits log文件,在切换时更新seen_txid的值。上次合并fsimage和editslog之后的第一个操作编号
用户操作过程
当文件系统客户端进行了写操作(创建或者移动了文件),这个事务首先在edits log中记录下来,namenode在内存中有文件系统的元数据,当edits log记录结束后,才更新内存中的元数据
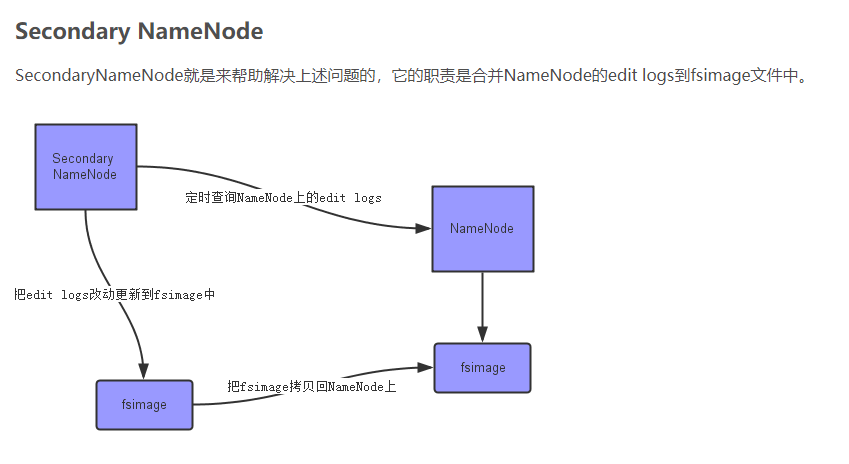
SecondaryNamenode
存在的意义
edits log会随着对文件系统的操作而无限制的增长,这种情况对正在运行的namenode而言没有任何影响,如果namenode重启,则需要很长的时间执行deits log的记录来更新fsimage(元数据的镜像文件),在此期间,整个系统不可用。
工作流程
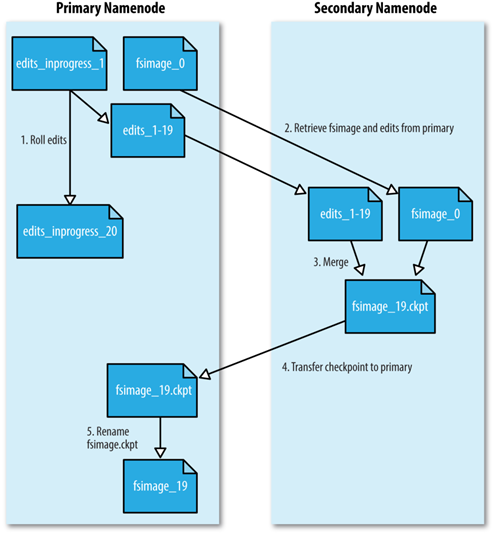
1.secondarynamenode请求namenode生成新的edits log文件并向其中写日志。NameNode会在所有的存储目录中更新seen_txid文件
2SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。
3.secondaryNameNode将fsimage加载到自己的内存上,并根据edits log更新内存中的fsimage信息,然后将更新完毕之后的fsimage写到磁盘上
4.SecondaryNamenode通过HTTP Put将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的临时文件备用。
5.NameNode重命名该临时文件并准备使用,此时NameNode拥有一个新的fsimage文件和一个很小的edits log文件(可能不是空的,因为在SecondaryNamenode合并期间,客户端可能有读写操作),管理员也可以将NameNode置于safeMode,通过hdfs dfsadmin -saveNamespace命令来进行edits log和fsimage的合并
SecondaryNameNode要和NameNode拥有相同的内存,对大的集群,SecondaryNameNode运行与一台专用的物理主机。
更新时机:
1.默认情况下:SecondaryNameNode每个小时进行一次checkpoint合并,由dfs.namenode.checkpoint.period设置,单位秒
2.在不足一小时的情况下,如果edits log存储的事务达到了100 0000 个也进行一次checkpoint合并
由dfs.namenode.checkpoint.txns设置事务数量
3.事务数量检查默认每分钟进行一次
由dfs.namenode.checkpoint.check.period设置,单位秒。
存储结构
1.目录布局和namenode完全一样
2.如果NameNode完全坏掉,也可以快速的从secondarynamenode回复,但是有可能会丢失数据,因为在secondarynamenode复制合并数据的时候,namenode的edits文件也在运行添加新的数据。
NameNode和SecondaryNamenode的工作机制
NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中,但是,如果只存在内存中,一旦断电,元数据丢失,这样,整个集群就无法工作了,因此产生了在磁盘中备份元数据的fsimage
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新fsimage,就会导致效率过低,但如果不更新,就会产生一致性的问题,一旦NameNode节点断电,就会产生数据丢失,因此,引入edits文件(只进行追加操作,效率很高),每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到edits中,这样,一旦NameNode节点断电,就可以通过fsimage和edits的合并,合成完整的元数据
但是,如果长时间添加数据到edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长,因此,需要定期进行fsimage和edits文件的合并,如果这个操作由NameNode节点完成,又会效率过低,因此,引入新的节点Secondarynamenode,专门用于fsimage和edits的合并
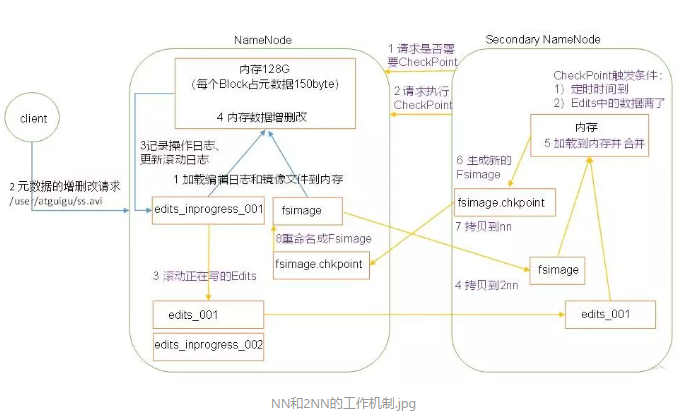
第一阶段:NameNode启动:
1.第一次启动namenode格式化后,创建fsimage和edits文件,如果不是第一次启动,直接加载编辑日志文件和镜像文件到内存。
2.NameNode记录操作日志,更新滚动日志。
3.NameNode在内存中对元数据进行增删改。
第二阶段:Secondarynamenode工作
1.secondarynamenode询问Namenode是否需要checkPoint,直接带回那么弄得是否检查结果
2.secondarynamenode请求执行checkPoint
3.NameNode滚动正在写的edits日志
4.将滚动前的编辑日志和镜像文件拷贝到secondaryNamenode
5.secondaryNamenode加载编辑日志和镜像文件到内存,并合并。
6.生成新的镜像文件fsimage.chkpoint
7.拷贝fsimage.chkpoint到NameNode
8.NameNode将fsimage.chkpoint重新命名成fsimage
DataNode
存储结构:

1、HDFS块数据存储于blk_前缀的文件中,包含了被存储文件原始字节数据的一部分。
2、每个block文件都有一个.meta后缀的元数据文件关联。该文件包含了一个版本和类型信息的头部,后接该block中每个部分的校验和。
3、每个block属于一个block池,每个block池有自己的存储目录,该目录名称就是该池子的ID(跟NameNode的VERSION文件中记录的block池ID一样)。
副本的放置策略:
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
Hadoop的安全模式
工作流程
- 启动NameNode,NameNode加载fsimage到内存,对内存数据执行edits log日志中的事务操作。
- 文件系统元数据内存镜像加载完毕,进行fsimage和edits log日志的合并,并创建新的fsimage文件和一个空的edits log日志文件。
- NameNode等待DataNode上传block列表信息,直到副本数满足最小副本条件。
- 当满足了最小副本条件,再过30秒,NameNode就会退出安全模式。最小副本条件指整个文件系统中有99.9%的block达到了最小副本数(默认值是1,可设置)
在NameNode安全模式(safemode)
- 对文件系统元数据进行只读操作
- 当文件的所有block信息具备的情况下,对文件进行只读操作
- 不允许进行文件修改(写,删除或重命名文件)