MapReduce的工作流程
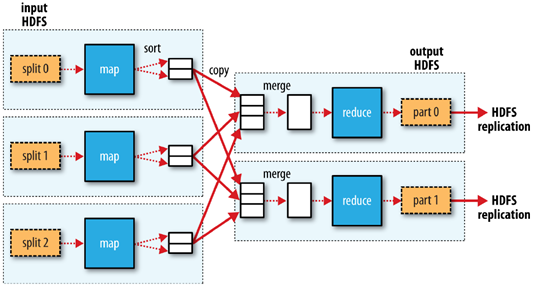
1.客户端将每个block块切片(逻辑切分),每个切片都对应一个map任务,默认一个block块对应一个切片和一个map任务,split包含的信息:分片的元数据信息,包含起始位置,长度,和所在节点列表等
2.map按行读取切片数据,组成键值对,key为当前行在源文件中的字节偏移量,value为读到的字符串
3.map函数对键值对进行计算,输出<key,value,partition(分区号)>格式数据,partition指定该键值对由哪个reducer进行处理。通过分区器,key的hashcode对reducer个数取模。
4.map将kvp写入环形缓冲区内,环形缓冲区默认为100MB,阈值为80%,当环形缓冲区达到80%时,就向磁盘溢写小文件,该小文件先按照分区号排序,区号相同的再按照key进行排序,归并排序。溢写的小文件如果达到三个,则进行归并,归并为大文件,大文件也按照分区和key进行排序,目的是降低中间结果数据量(网络传输),提升运行效率
5.如果map任务处理完毕,则reducer发送http get请求到map主机上下载数据,该过程被称为洗牌shuffle
6.可以设置combinclass(需要算法满足结合律),先在map端对数据进行一个压缩,再进行传输,map任务结束,reduce任务开始
7.reduce会对洗牌获取的数据进行归并,如果有时间,会将归并好的数据落入磁盘(其他数据还在洗牌状态)
8.每个分区对应一个reduce,每个reduce按照key进行分组,每个分组调用一次reduce方法,该方法迭代计算,将结果写到hdfs输出
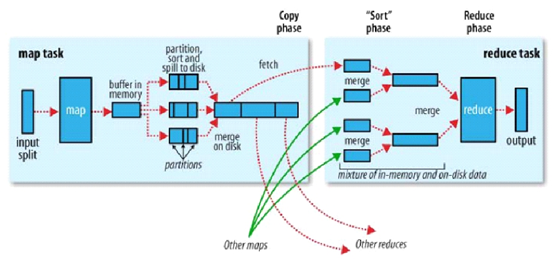
洗牌阶段
1.copy:一个reduce任务需要多个map任务的输出,每个map任务完成时间很可能不同,当只要有一个map任务完成,reduce任务立即开始复制,复制线程数配置mapred-site.xml参数“mapreduce.reduce.shuffle.parallelcopies",默认为5.
2.copy缓冲区:如果map输出相当小,则数据先被复制到reduce所在节点的内存缓冲区大小配置mapred-site.xml参数“mapreduce.reduce.shuffle.input.buffer.percent”,默认0.70),当内存缓冲区大小达到阀值(mapred-site.xml参数“mapreduce.reduce.shuffle.merge.percent”,默认0.66)或内存缓冲区文件数达到阀值(mapred-site.xml参数“mapreduce.reduce.merge.inmem.threshold”,默认1000)时,则合并后溢写磁盘。
3.sort:复制完成所有map输出后,合并map输出文件并归并排序
4.sort的合并:将map输出文件合并,直至≤合并因子(mapred-site.xml参数“mapreduce.task.io.sort.factor”,默认10)。例如,有50个map输出文件,进行5次合并,每次将10各文件合并成一个文件,最后5个文件。
K,V使用自定义数据类型
框架会对键,值序列化,因此键类型和值类型需要实现writable接口
框架会对键进行排序,因此必须实现writableComparable接口