一、基础介绍
1.Zookeeper概念
Zookeeper是一个分布式的,开放源代码的分布式应用程序协调服务,它提供了简单的功能,例如分布式同步,配置管理,集群管理,命名惯例,队列管理。Zookeeper是集群的管理者,监视着集群中各个节点的状态,根据节点提供的反馈进行操作。
2.Zookeeper相关功能
·文件系统,zookeeper的命名空间是zookeeper应用的文件系统,每个路径都是唯一的,命名空间操作也都是绝对路径操作。
zookeeper是由一个个的znode组成的,一个znode节点可以包含子znode,也可以包含数据(只适合存储小的数据),每一个znode也有唯一的路径标识。
3.Zookeeper文件系统的特点
·访问路径只有绝对路径,没有相对路径
·zookeeper的文件系统是从“/”开始
·zookeeper只有znode节点,既有文件的功能,又有目录的功能。但是没有文件和目录的概念
4.Zookeeper基本架构
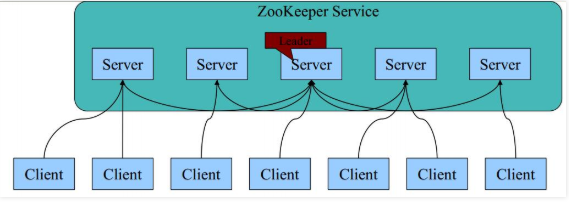
· 每个Server在内存中存储了一份数据;
·Zookeeper启动时,将从实例中选举一个leader(Paxos协议);
·Leader负责处理数据更新等操作(Zab协议);
·一个更新操作成功,当且仅当大多数Server在内存中成功修改
数据。
二、znode基础简介
1.znode分类
短暂的:断开时删除
持久的:断开时保留
2.znode4种表现形式
| persistent | 持久化znode节点,一旦创建这个znode点存储的数据不会主动消失,除非客户端主动delete |
| Persistent_sequential | 自动增加顺序编号的znode节点,比如ClientA 去 zk service 上建 立一个 znode 名字叫做/zk/conf,指定了 这种类型的节点后 zk 会 创 建 /zk/conf0000000000 , ClientB 再 去 创 建 就 是 创 建 /zk/conf0000000001, ClientC 是创建/zk/conf0000000002,以后任 意 Client 来创建这个 znode 都会得到一个比当前 zk 命名空间最 大 znode 编号+1 的 znode,也就说任意一个 Client 去创建 znode 都是保证得到的 znode 是递增的,而且是 唯一的。(原子性原则) |
| Ephemral | 临时znode节点,client连接到zkservice的时候会建立一个session,之后用这个zk连接实例创建该类型的znode ,一旦client关闭了zk的连接,服务器就会清除 session,然后这个 session 建立的 znode 节点都会从命名空间 消失。 |
| Ephemral_ sequential | 临时自动编号设置,znode节点编号会自动增加,但是会随着session消失而消失。 |
3.znode特点
·存储的数据很小,最好不要超过1M,否则很难保证数据的一致性
·创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。(无论创建的是否是有编号节点,都为顺序递增)
4.监听的触发
Znode的创建----nodeCreated
Znode 被删除---nodeDelete
Znode的数据变化---nodedatachanged
Znode的子节点的变化----nodeChildrenchange
注:监听只生效一次