zookeeper是一个分布式程序的高性能协调服务,提供集中式信息存储服务,数据存储于内存中,类似文件系统的树形结构,高吞吐量和低延时,集群高可靠,基于zookeeper可以实现分布式统一配置中心、分布式锁、服务注册中心。
zookeeper的同类产品 consul etcd Doozer等
单机版安装
下载tar文件,地址 http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/
解压后在conf目录增加zoo.cfg(复制zoo_sample.cfg文件,重命名即可),注意配置data的路径
启动服务端 进入zookeeper安装目录 bin/zkServer.sh start
客户端连接 bin/zkCli.sh -server 127.0.0.1:2181
zookeeper常用命令,参考 https://zookeeper.apache.org/doc/current/zookeeperStarted.html ,输出help即可看到

在安装包下有 zookeeper-3.4.14.jar,它就是官方提供的java 客户端,我们可以使用它来操作zookeeper,但是其api太过底层,所以一般使用第三方的客户端,常用的有zkClient和Curator。
zookeeper核心概念
1、session
一个客户端连接是一个会话,由zk分布一个唯一id 客户端以特定的时间发送心跳保持会话,ticktime,超过会话超时时间未收到心跳则判定客户端挂掉,(默认2倍ticktime),会话中的请求FIFO执行
2、数据模型
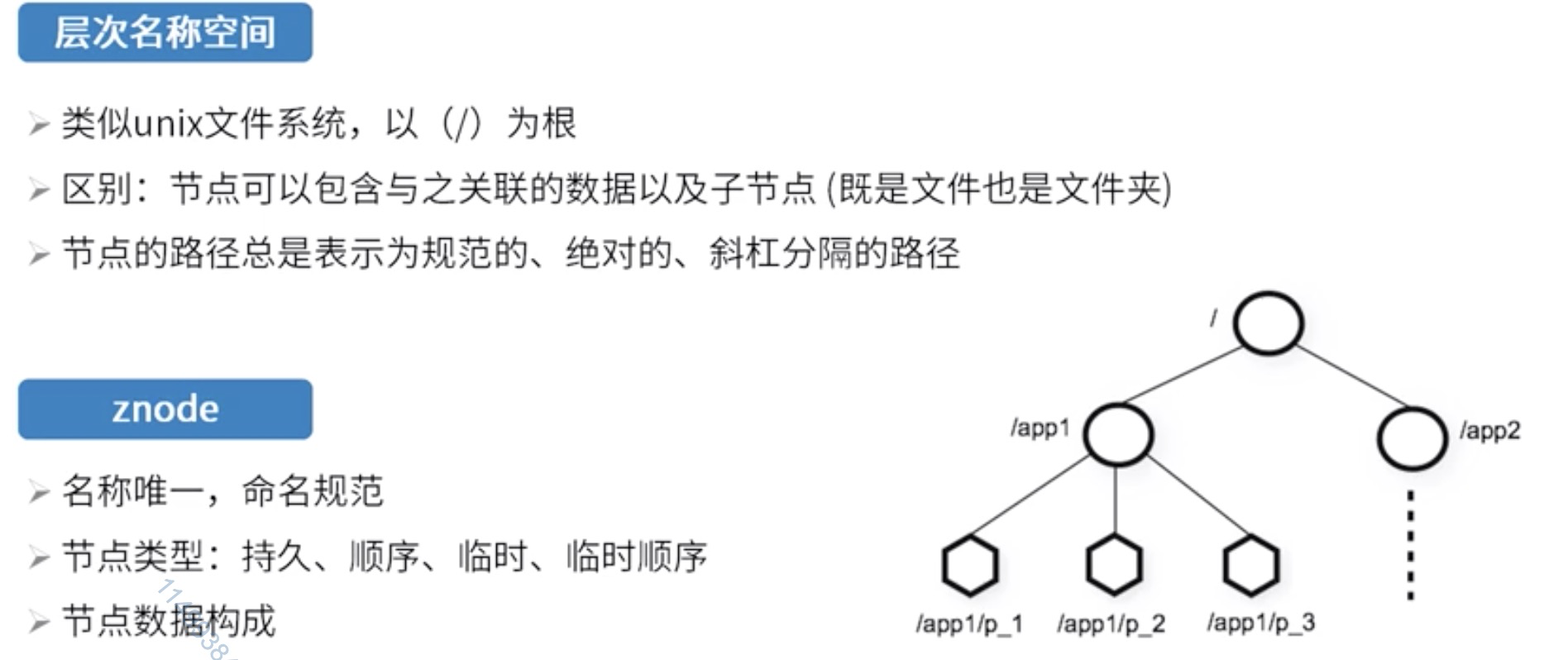
节点类型
持久节点 create /asd asd
临时节点 create -e /asd asd 连接断开后即消失
顺序节点 create -s /asd asd 真实名称asd0000000268(名字+ 10位十进制数字)
顺序节点 create -s /asd/ asd 真实名称0000000268(10位十进制数字)
临时顺序节点 create -s -e /asd asd
节点数据构成:存储的协调信息和元数据,数据量上限1M
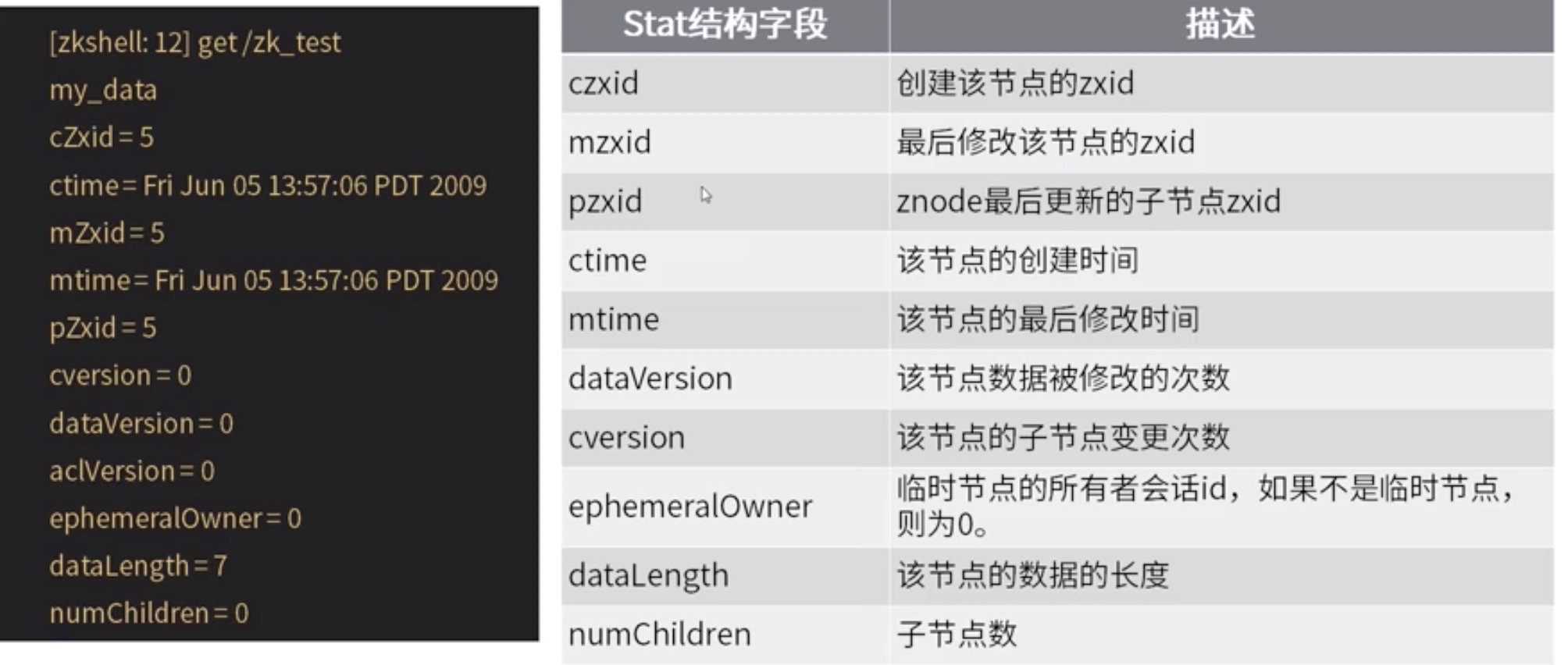
节点元数据结构:zxid(事务id)
3、zookeeper中的时间
Zxid zookeeper种每一次更改操作都对应一个唯一的事务id,称为zxid,它是全局有序的戳记,如果zxid1>zxid2,则zxid1一定在zxid2之后发生
version number 每次对节点的修改都会使其版本号增加
ticktime 在使用多服务器时,服务器通过ticktime来定义事件的时间,ticktime仅通过最小会话时间(ticktime的2倍)公开,如果客户端请求的会话时间小于最小会话时间,则服务器会告诉客户端会话超时实际上为最小超时时间
real time 仅在znode创建和修改时将时间戳放入stat结构中
4、watch监听机制
通过help命令我们可以看到ls get 等命令都支持watch,命令使用如下 get /asd 1(boolean值,默认为0,为1时表示监控变化)。watch机制是一次性触发,即只能监控到第一次的变化,若要持续监控,则需要持续设置watch,watch是有序的,客户端先收到watch通知后看到变化。
因为watch是一次性的,并且在获取通知和发送新的watch请求存在间隙,所以不能可靠的发现节点的每一次变化
使用场景
1、配置中心
主要使用到zookeeper的两个特性,znode存储数据及watch机制,两种使用方式:一个配置项一个znode和一个配置文件一个znode,具体看配置在集群中的差异性。
2、命名服务
分布式开发中A服务不依赖B服务的具体ip端口信息,而是根据一个服务名去获取对应的ip端口信息,这样A服务可以先行部署而后监听B服务对应的服务名的变化,而后B服务开发完工后再部署后,A服务不用做任何修改就可以正常访问,具体如下图

3、master选举
两种方式:
(1)争抢创建主节点,集群中各个服务器在申请创建同一个主节点(临时节点)时带上自己的地址信息,但是只有一个会创建成功,其它的创建失败后则后通过获取主节点的值来知道当前主节点是谁,并且注册对主节点的watch,当master挂掉后,对应的主节点也被删除,此时剩下的服务器则又开始新一轮的争抢创建主节点,创建成功的即为下一个master。
(2)集群各个服务器都申请创建临时顺序节点,序号最小的即为master,master挂掉后其后一个节点对应的机器则为master。
同时还可以创建一个server节点,所有集群中的节点都来创建一个一个临时顺序节点,利用这个可以做集群管理
4、分布式队列
入队:所有生产者往同一个节点下(queue)创建顺序节点
出队:获取节点下所有子节点,移除最小序号对应的节点
针对无界队列,可以利用上面所说直接实现,有界队列则需要用到分布式所来实现获取队列元素数目和放入元素同步
5、分布式锁
两种方式
(1)都去创建同名临时节点,创建成功则执行后续逻辑,没有创建成功则注册这个节点的watch
(2)创建同名临时顺序节点,获取所有子节点,判断自己是否为最小号,是则获取锁成功执行逻辑后删除对应节点,不是则注册前一个节点的watch等待被通知